本来是一个美好的大周末,突然却被一个突如其来的电话把我从美梦中惊醒,然而一切还不止这么简单......
本来刚开始了解到信息是客户的一台RouteOS设备挂了,听到这个消息时觉得自己应该可以很快解决,毕竟就是重启一下的事情,然而真正登录到后台才发现一切都没这么简单......
后台查看操作系统状态
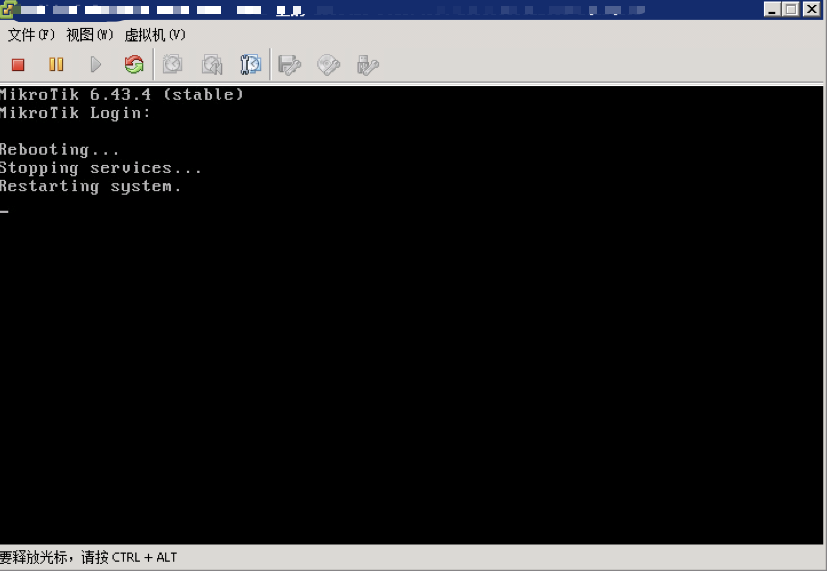
唉,别提有多难过,后台竟然发现系统刚刚启动就立马重启了,而且反复如此,陷入了死循环,因此第一时间判断为此台RouteOS被黑了(事实证明是我多虑了),看样子是没有办法短时间恢复了,让客户切换业务吧,客户涉及此台设备的业务路由进行切换。
初步分析
判断为系统被黑后,开始查看这台设备的监控信息。
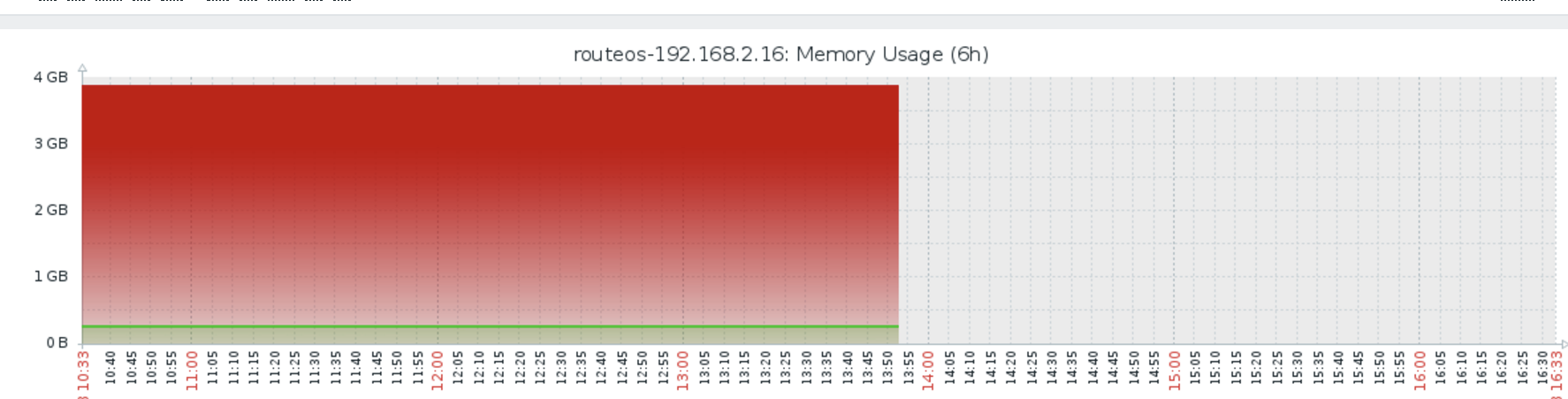
客户提供的zabbix监控数据。
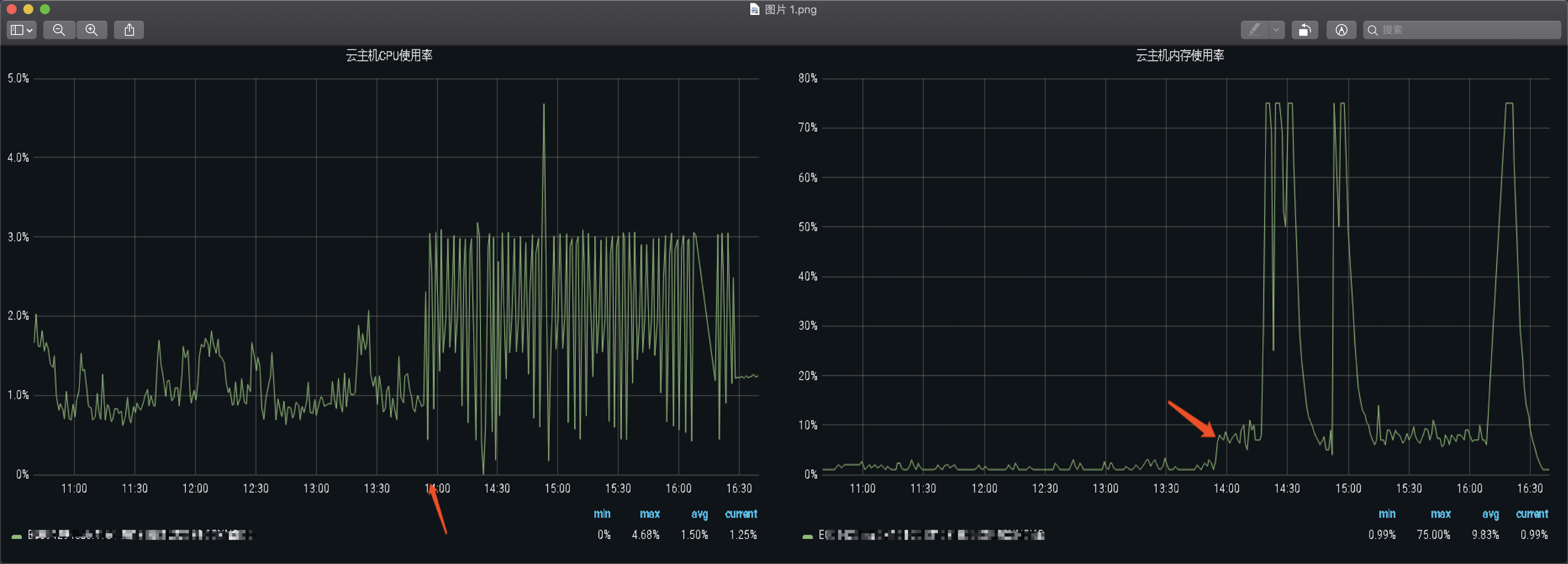
查看我方后台监控,发现CPU和内存使用率确实有异常,从客户监控获取不到数据的时间点开始,我方监控可以准确的显示到改设备的CPU使用率开始异常,与正常业务模型相比,变化明显,内存使用率也开始从正常的百分之十以下的使用率突增到百分之七十以上,此刻心中更加确信此台设备是被黑了。
咋整,此时内心无比尴尬,因为这个客户以前就已经被黑过一次了(RouteOS版本低,存在漏洞最终被攻击),并且已经升级到了最新版本还购买了KEY,没办法硬着头皮和客户说吧。因为自己不太了解RouteOS系统,所以将故障升级,且料二线工程师告诉我没办法修复了,唉,忍着被挨骂的风险告诉客户吧。
进一步获取信息
告诉了客户系统可能被黑了以后,客户说被黑的可能性不大,原因如下:
- 已经将操作系统升级至最新版本,且使用的不是破解版,还购买了key。
- 已经将所有登录方式关闭,只留下了web界面这种登录方式,可以登录的地址只开放给了客户公司的公网地址,同时修改了默认端口。
- 密码复杂度极高:20位以上随机生成密码。
目前从监控中看到的信息,CPU和内存有异常,客户表示它们的zabbix没有监控到内存有变化,和客户解释因为客户zabbix监控是使用snmp协议对此台设备进行监控的获取不到数据是因为网络不通了导致,而我方监控是直接从宿主机获取的日志,所以可以监控到后续的信息,但是根据客户提供的信息,被攻击的风险确实不大,只能硬着头皮搞了,尝试下能不能修复系统。
修复系统
当前第一要务是先把操作系统启动,确保可以稳定运行不会再一次重启,后台挂载修复镜像后,进入修复模式,对这个系统也不了解,只能一步一步琢磨加上网上搜索资料,看到有文章也遇到过类似的问题,RouteOS重启的问题,可能和watchdog有关。
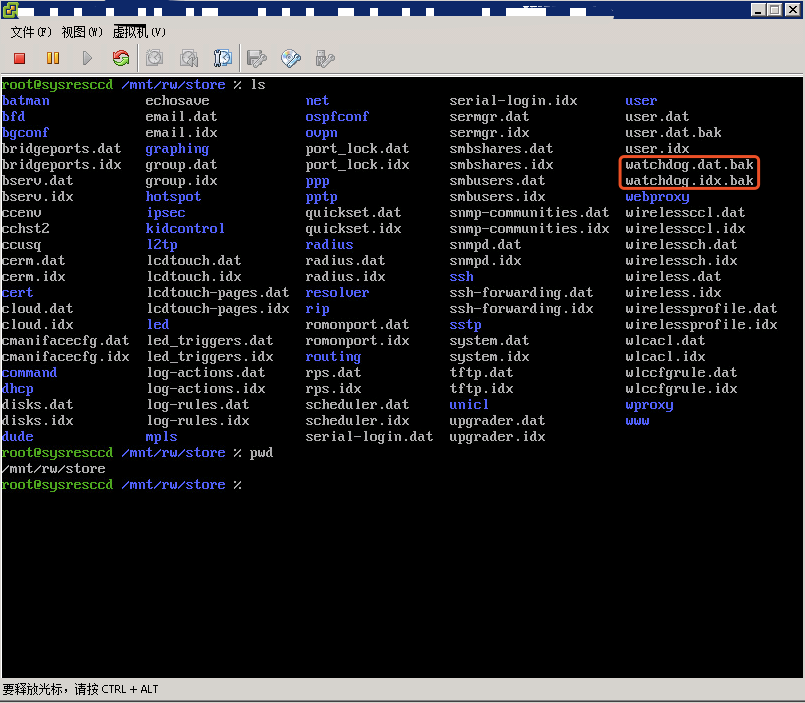
进入修复模式,将watchdog配置文件进行备份,重启发现系统正常了,确认了操作系统反复重启应该是watchdog配置导致,向客户询问有关watchdog的配置信息。
后续经过确认客户配置如下:
Watch Address: 公网网关地址
Ping Start After Boot: 00:01:00
Ping Timeout: 10s
怀疑是客户配置导致,新开了一台RouteOS进行测试,将测试机的Watchdog配置和客户相同后重启,发现操作系统确实会一直重启,确认了是因为配置导致操作系统不断重启,后续后台重启测试机的同时开始ping测试机的公网地址,到可以ping通时用时大约100s,怀疑是客户操作系统不断重启的原因是因为系统启动网卡还未完全就绪,RouteOS watchdog就已经开始执行ping测试,测试10s发现与监控地址不通,直接重启,如此反复陷入死循环。
推翻最初分析
这样就可以推翻最初被黑的分析了,至于监控到CPU和内存突增,就是操作系统反复重启导致的了,唉,通过一个一个目录找文件,到最终能把系统修复,不容易啊。
确认系统关机原因
系统反复重启的原因已经确认了,但是又是什么原因导致最初系统会关机呢,这个同样需要确认下,所以和客户要了重启时间段的日志,获取到有效信息如下:
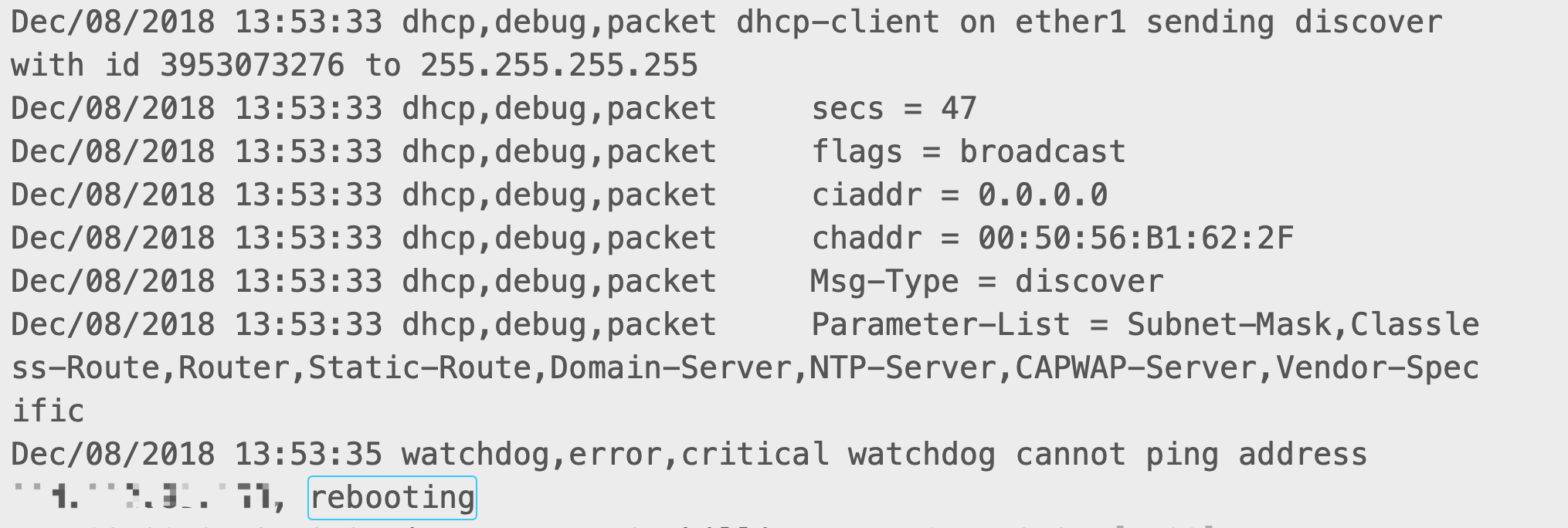
从日志字面意思理解是watchdog程序出现了严重错误,导致watchdog不能ping设置的网关地址,最终重启RouteOS。
为了确认下不是网络原因导致的,我在测试机上同样配置了相关操作,watchdog检测一个服务器的地址,后续在服务器上打开防火墙禁止ICMP协议,RouteOS开始重启,重启后获取日志信息如下:

好了,确认了如果是网络问题,会报timeout错误,至此修复了客户的操作系统,并确认了操作系统最初重启的原因,心累,不过是一次很好的学习体验。