HBase 架构
HBase 是受 Google Bigtable 论文 启发实现的一个 K-V 类型的 LSM 存储引擎,其架构设计与 Bigtable 完全相仿。本文只讲解 HBase 的架构设计并剖析到 HBase 的存储不可分割的最小单元 KeyValue 类,但未涉及 HBase 数据的读写流程。关于 LSM 引擎可以看 SSTable 与 LSM 引擎
HBase 整体架构
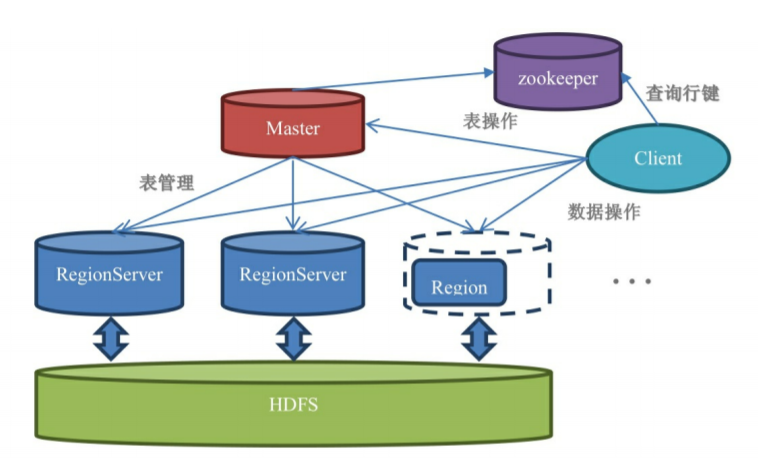
HBase 主要进程包括 Master、RegionServer 和 Client,同时还依赖于外部的 ZK 和 HDFS。
HMaster
与其他分布式存储框架类似,HBase 中 Master 宕机并不会导致集群不可用,仍然可以查询和增改数据,Master 负责的功能则包括建表、删表移动 Region 等需要跨 RegionServer 的操作,在 HBase 中 Master 更像是一个管家的角色。
RegionServer
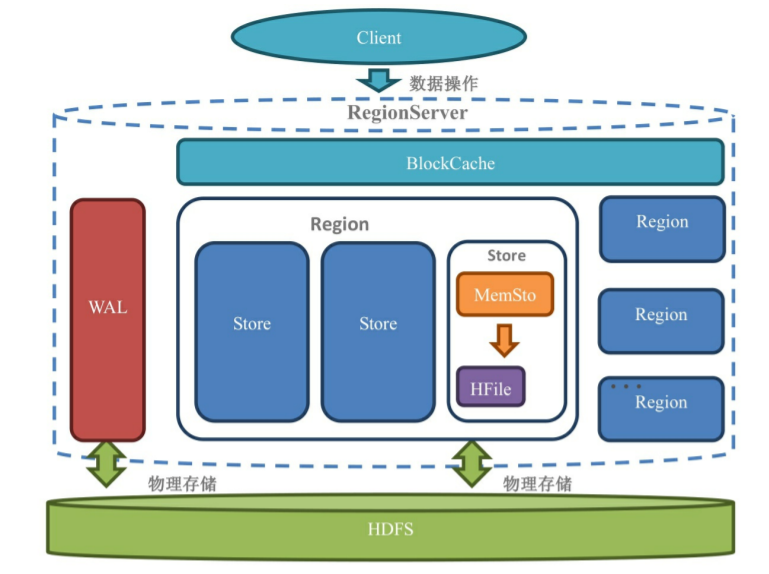
RegionServer(简称RS) 才是 HBase 服务的核心组件,Client 需要读写数据首先就要找到对应 Rowkey 范围的 Region 在哪个RS上,连接上 RS 才能进行后续操作,如下图所示,RS 由一个 WAL(Write-Ahead Log 预写日志) 、一个读缓存 BlockCache 和若干个 Region 组成。
Region
Region 是 HBase 表的水平切分,如同其字面意思所示每个 Region 管理表中一定范围的行数据,一个 Region 中有若干个 Store。随着 Region 中的数据不断增加,Region 超过一定大小后将切分为两个 Region,这是一个有些昂贵的操作,尤其是涉及到 RS 在不同节点间的转移时,所以如果能够提前预料表数据的大小时,可以在建表时考虑进行预分区,提前指定 RS 个数。
Store 及以下
一个 Store 中是一个列族的数据,一个 Strore 包含一个 MemStore 和若干 HFile。
MemStore 实际上是一个写缓存,对写请求数据进行集散,所有写请求的数据按照 rowkey 在 MemStore 中进行排序,当 MemSore 的数据超过一定限制之后将刷写到实际存储在 HDFS 上的 HFile。在 HBase 中 MemStore 是用跳表实现的,跳表同样在 Redis 中的 zset 中使用,这是因为相较于红黑树,跳表实现简单而且当数据写入时,其需要锁定的数据范围更小,有更好的并发性能。
HFile 的数据在写入后就不会被更改,所以 HFile 是一个有序的、不可变的 Map(K-V对)数据文件。得益于 HFile 的不可变性,读取 HFile 数据时不用加锁,对并发读有更好的支持。不同的 HFile 文件可能包含同一个 rowkey 对应的数据,有些是已经过期或者被删除了的,为了节省这部分数据占用的空间,HBase 在后台会对同一个 Store 中的 HFile 进行合并(compaction),得益于 HFile 的有序性,归并排序使用一个不大的内存即可完成 HFile 的合并。想要更好的理解 MemStore 和 HFile 可以看看 // todo
接下来让我们看看更微观的 HBase 结构,HFile 是 HBase 存储数据的实际载体,而 HFile 是由多个 Block 组成的,默认情况下每个 Block 的大小是 64k,Block 通常有以下几种:
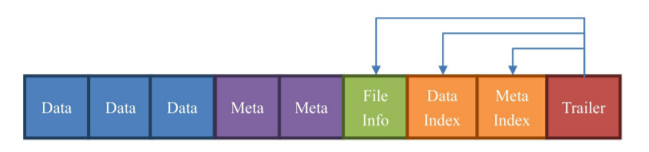
Data:数据块。每个HFile有多个Data块。我们存储在HBase表中 的数据就在这里。Data块其实是可选的,但是几乎很难看到不包含Data块的HFile。
Meta:元数据块。Meta块是可选的,Meta块只有在文件关闭的时 候才会写入。Meta块存储了该HFile文件的元数据信息,在v2之 前布隆过滤器(Bloom Filter)的信息直接放在Meta里面存储, v2之后分离出来单独存储。不过你现在暂时不需要了解布隆过滤 器是什么东西。
FileInfo:文件信息,其实也是一种数据存储块。FileInfo是 HFile的必要组成部分,是必选的。它只有在文件关闭的时候写 入,存储的是这个文件的信息,比如最后一个Key(Last Key),平均的Key长度(Avg Key Len)等。
DataIndex:存储Data块索引信息的块文件。索引的信息其实也 就是Data块的偏移值(offset)。DataIndex也是可选的,有 Data块才有DataIndex。
MetaIndex:存储Meta块索引信息的块文件。MetaIndex块也是可 选的,有Meta块才有MetaIndex。
Trailer:必选的,它存储了FileInfo、DataIndex、MetaIndex 块的偏移值。
Block 中负责存储实际数据的是 Data Block,Data Block 的结构为:

Data Block 以 BlockType 开始,后面跟着若干个 Cell。BlockType 包括 DATA、META、FILE_INFO、BLOOM_CHUNK 等类型,这里就不展开了,感兴趣的可以自行了解。Cell 是一个接口,KeyValue 是最重要的一个实现类,KeyValue 的结构为:
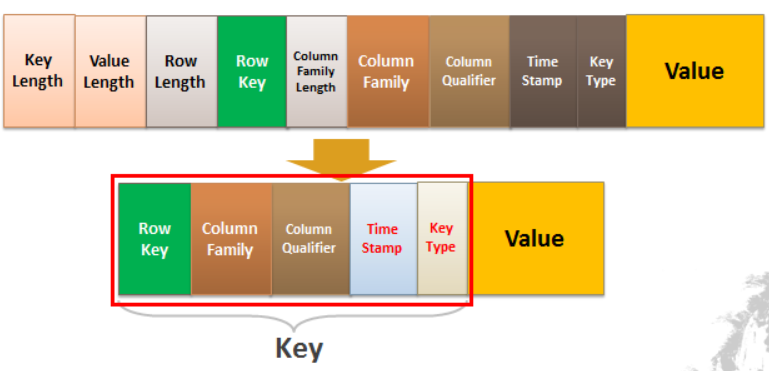
The KeyValue format inside a byte array is:
<keylength> <valuelength> <key> <value>Key is further decomposed as:<rowlength> <row> <columnfamilylength> <columnfamily> <columnqualifier> <timestamp> <keytype>
从源码中的注释我们可以知道,KeyValue 大致包含 <keylength> <valuelength> <key> <value> ,而 Key 又是由 <rowlength> <row> <columnfamilylength> <columnfamily> <columnqualifier> <timestamp> <keytype> 组成。
WAL(Write-Ahead Log)
预写日志,也叫做 HLog,是为 MemStore 数据意外丢失时进行灾难恢复而设立的。一个 RegionServer 中有多个 Region 但只有一个 WAL,这多个 Region 共享 WAL,这样设计的原因同样可以在 BigTable 论文中找到。
Commit-log implementation
If we kept the commit log for each tablet in a separate log file, a very large number of files would be written concurrently in GFS. Depending on the underlying file system implementation on each GFS server, these writes could cause a large number of disk seeks to write to the different physical log files. In addition, having separate log files per tablet also reduces the effectiveness of the group commit optimization, since groups would tend to be smaller. To fix these issues, we append mutations to a single commit log per tablet server, co-mingling mutations for different tablets in the same physical log file.
当开启 WAL 时,所有的对数据的变更操作操作都将首先写入 WAL 中,然后再写入 MemStore,当 MemStore 超过阈值时再批量刷写到 HFile 中。这其中 WAL 和 HFile 的数据都是存储在 HDFS 上的,而 MemStore 是基于内存的。看到这里读者可能有些疑问,既然数据已经通过 WAL 在 HDFS 上写过一遍了,为什么还需要后续的操作再往 HDFS 上写一遍,而不是直接往 HFile 中写。这里的设计考量是:WAL 是一个 Hadoop Sequence File,来一条写一条每次进行顺序追加写,其速度并不慢,而 HFile 是 HBase 需要持久化的数据,此后的查询需要读取这部分数据,为了能够快速查找是需要有序的,由于从客户端传来的数据变更请求对应的 rowkey 基本是无序的,所以先在内存中进行集散和排序,然后再写入HFile中是更优的选择,这样保证每次写入的都是有序的数据,将来读取速度更快,当数据已经刷写到 HFile 后,WAL 中的对应的部分可以删除,所以 WAL 不会很大。
当节点故障时,Master 会安排这上面的 Region 转移至其他可用节点,而 WAL 由多个 Region 共享,会对 WAL 进行 Region 粒度的拆分,之后各个 Region 进行数据恢复。
HBase 依赖的外部框架
ZK:通过 ZK 赋予的能力,HBase 可以保证任意时刻最多只有一个 Master,同时集群中的节点能够互相感知,当节点故障时可以通过 备用 Master 转正、Region 转移等进行故障恢复,保证了集群的高可用。同时 HBase 还将一些元数据放在 ZK 中,包括 RS 的地址、 Region 与 RS 的映射关系等,客户端第一次进行数据读写时,首先需要从 ZK 中获取 hbase:meta 表所在的 RS 位置并读取 hbase:meta 表,在这张表中记录了 Region 所在的 RS 及其位置,此后客户端会将这张表缓存在本地。
HDFS:通过 HDFS 赋予的能力,HBase 不用担心 WAL 和 HFile 的文件备份和故障转移问题,由于 HDFS 的分布式存储,使得 Region 转移和自动切分的速度更快。
HBase 架构总结
- 一个RegionServer包含多个Region,划分规则是:一个表的一段键值在一个RegionServer上会产生一个Region。不过要当一行的数据量太大了(要非常大,否则默认都是不切分的),HBase也会把你的这个Region根据列族切分到不同的 Region Server上去。
- 一个Region包含多个Store,划分规则是:一个列族分为一个Store,如果一个表只有一个列族,那么这个表在这个机器上的每一个Region里面都只有一个Store。
- 一个Store里面只有一个Memstore。
- 一个Store里面有多个HFile(StoreFile是HFile的抽象对象,所以如果说到StoreFile就等于HFile)。每次Memstore的刷写(flush)就产生一个新的HFile出来。
参考资料
- [1] DDIA-驱动数据库的数据结构
- [2] 大数据:Hive - ORC 文件存储格式
- [3] Redis(2)——跳跃表
- [4] HBase 不睡觉书