- Introduction
In prior work, researchers often focused on optimizing the performance of federated learning algorithm and assumed full participant. However, users will join in the training process if and only if they can benefit from the FL system and the server provider also want to attract users with high-quality data to contribute their models.
In this work, based on contract theory, authors designed a reward mechanism to maximum the total benefit for the provider.
- Main idea
In FL, the data quality is diverse among users and the provider can't find which user has high data quality, i.e., the information is asymmetry. For users, each optimization iteration will consume computation (E_n^{cmp}(f_n)=zeta c_ns_n f_n)and there is also a communication cost (E_n^{con}=frac{sigma ho_n}{Nlog(1+frac{ ho_nh_n}{N_0})})when uploading the update, where (c_n) is the CPU cycles, (s_n) is the batch size, (f_n) is the CPU cycle frequency, (sigma) is a constant, ( ho_n) is the transmission power of user (n) and (h_n) is the channel gain. For the providers, they are expect to get final model as quickly as possible. The computation time of each iteration in user (n) is (frac{c_ns_n}{f_n}) and the number of iteration is (log(frac{1}{epsilon_n}))to achieve (epsilon_n) accuracy. The transmission time is (frac{sigma}{Blog(1+frac{ ho_n h_n}{N_0})}) and the total time consumption is (T_n=log(frac{1}{epsilon_n}) frac{c_ns_n}{f_n}+frac{sigma}{Blog(1+frac{ ho_n h_n}{N_0})}).
They used ( heta_n=frac{varphi}{log(frac{1}{epsilon_n})}) to label the data quality and the higher ( heta) means the better data quality and less local computation iteration. Let ( heta_1<dots< heta_m<dots< heta_M). Based on the degree of ( heta), the provider will provide different contract and reward bundles, ((R_n(f_n), f_n)).
The profit of the provider is defined as
(omega) is the satisfaction parameter and (T_{max}) is the maximum tolerance time of the provider. Interpolate (T_n), we have
For users, the utility function is
Under individual rationality and monotonicity assumption, the objective and constraints are following:
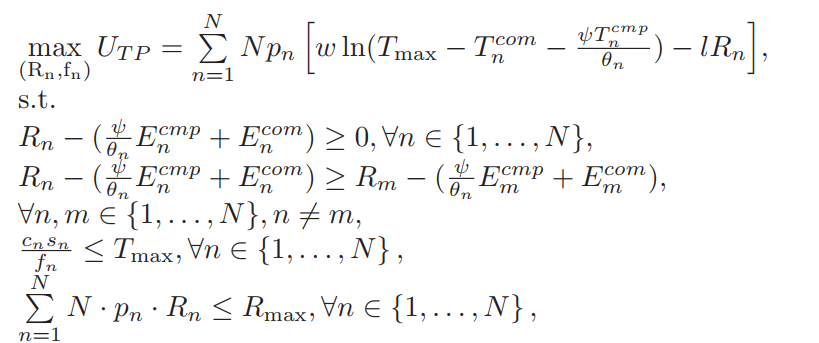
- Summary
- In their work, they wanted to incentive users with high data-quality to join in the training process.
- However, (epsilon_n) seems like a prior and it maybe unpractical.
- They measured the users' profit by (T_n) indirectly and the more straightforward idea is to measure full benefit (R-R_{-n}), where (R_{-n}) is the benefit excluding user (n).
- They designed the mechanism mainly for cross-device scenarios and it's inappropriate for cross-silo device.