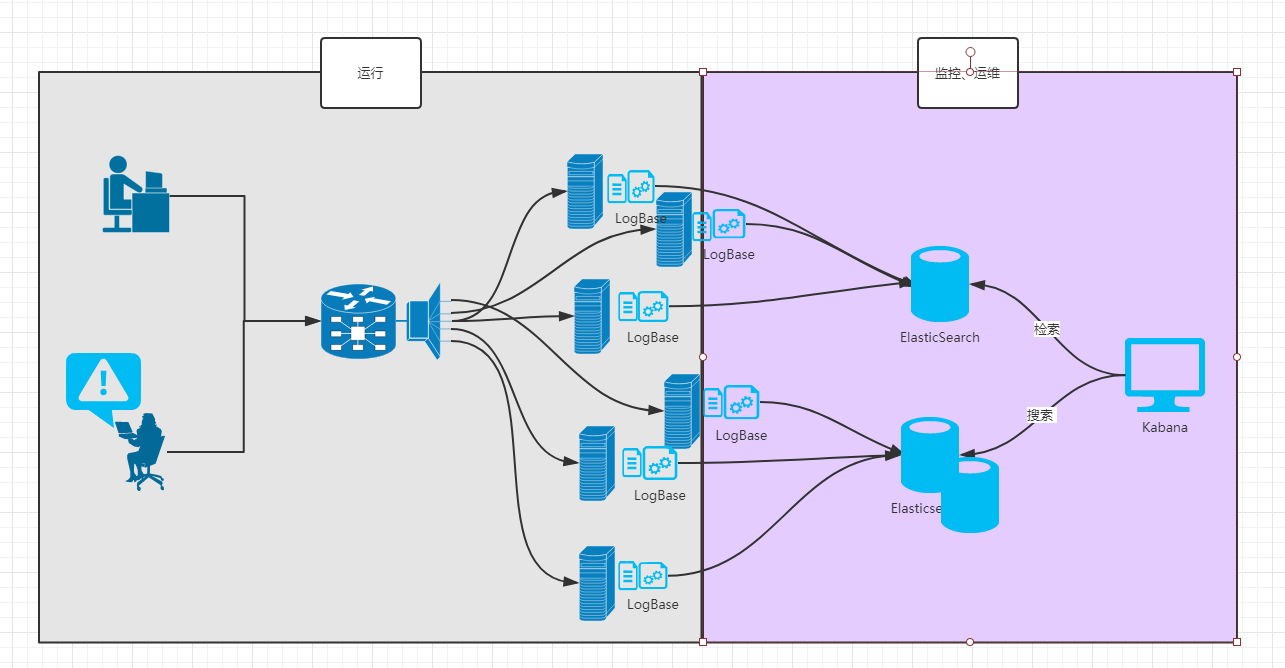
>cd elasticsearch/bin
>elasticsearch.bat
如果没有配置JAVA_HOME,又不想在环境变量中配置 可手动打开 elasticsearch-env.bat 在里面设置 set java_home=***
启动起来后,可通过 http://localhost:9200 即可查看结果。
{ "name" : "3hKw88o", "cluster_name" : "elasticsearch", "cluster_uuid" : "0elyGgO2Rsqzj7v3yKX24g", "version" : { "number" : "6.2.3", "build_hash" : "c59ff00", "build_date" : "2018-03-13T10:06:29.741383Z", "build_snapshot" : false, "lucene_version" : "7.2.1", "minimum_wire_compatibility_version" : "5.6.0", "minimum_index_compatibility_version" : "5.0.0" }, "tagline" : "You Know, for Search" }
默认情况下,elasticsearch只允许本机访问,若想改变ip则需要修改文件
configelasticsearch.yml
可修改port和 network地址:
network.host: 192.168.201.105
elastic使用 curl 命令来访问,但这种操作太不方便了,因此elasticsearch有个专用chrome插件 sense(sense下载和安装参见 浏览器chrome插件)。
或者使用 ElasticSearch-head插件可做集群的傻瓜式操作。
默认打开后,直接访问报错:
elasticsearch6.x {"error":"Content-Type header [application/x-www-form-urlencoded] is not supported"
原因为:sense0.9不支持elasticsearch6.x,6.x加了content_type声明。因此有人直接修改sense插件的ajax请求,sense.crx可被解压为文件夹,修改后将文件夹直接拖放到chrome插件发布中。
然后再访问就OK了。
因没有加入任何数据,因此检索出的结果为0。
elasticSearch 采用lucene作为索词工具,因此也会有索引和文档管理的概念。
文档管理crud介绍: create, retrieve, update, delete
create结构:[PUT|POST] http://ip:9200/<index>/<type>/[<id>]
elastic中的索引 index 如同数据库库名一样。
注意点:
1. 其中 id可选填,不填系统默认会给分配id且不填时必须用post提交
2. index为索引必须小写,一种索引只能归属于一种类型。一个索引下可以存在多笔数据,不过一个索引下的数据越多搜索消耗时间就越长。
3.type为类型,一种类型可对应多个索引。类型是一种空间区分。不过type在elastic6.0后已经不推荐使用deprecated.
以例子中的建立movie(小王子)为例:
create:
POST http://192.168.201.105:9200/thelittleprince/movie/ { "title":"The Little Prince", "year" : "2012-10", "description": " a little pure prince" }
执行结果 result created:
{ "_index": "thelittleprince", "_type": "movie", "_id": "jDzZE2UB4ZisejttH3B6", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 0, "_primary_term": 1 }
update:
update和create方式一样,不同点在于update要加id。内容json部分可随意修改。
POST http://192.168.201.105:9200/thelittleprince/movie/jDzZE2UB4ZisejttH3B6 { "title":"The Little Prince", "year" : "2012-10", "description": " a little pure prince", "country" : "franch" }
执行结果 result:updated:
{ "_index": "thelittleprince", "_type": "movie", "_id": "jDzZE2UB4ZisejttH3B6", "_version": 2, "result": "updated", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 1, "_primary_term": 1 }
retrieve获取数据:
将post变为get请求即可。必须包含ID
GET http://192.168.201.105:9200/thelittleprince/movie/jDzZE2UB4ZisejttH3B6
执行结果 found:true:则找到数据,内容为_source中的json对象。
{ "_index": "thelittleprince", "_type": "movie", "_id": "jDzZE2UB4ZisejttH3B6", "_version": 2, "found": true, "_source": { "title": "The Little Prince", "year": "2012-10", "description": " a little pure prince", "country": "franch" } }
delete 删除文档:
DELETE http://192.168.201.105:9200/thelittleprince/movie/jDzZE2UB4ZisejttH3B6
执行结果 result: deleted:
{ "_index": "thelittleprince", "_type": "movie", "_id": "jDzZE2UB4ZisejttH3B6", "_version": 3, "result": "deleted", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 2, "_primary_term": 1 }
删除后再次查询就会发现found为false.
如果只是以上这些,那elasticSearch就没有什么用,我们要的是搜索引擎式的海量模糊检索。
搜索,搜索前我们先插入几笔与电影有关的数据。此数据来自于易佰教程。
POST http://192.168.201.105:9200/movie/crime { "title": "The Godfather", "director": "Francis Ford Coppola", "year": 1972, "genres": ["Crime", "Drama"] } POST http://192.168.201.105:9200/movie/crime { "title": "Lawrence of Arabia", "director": "David Lean", "year": 1962, "genres": ["Adventure", "Biography", "Drama"] } POST http://192.168.201.105:9200/movie/crime { "title": "To Kill a Mockingbird", "director": "Robert Mulligan", "year": 1962, "genres": ["Crime", "Drama", "Mystery"] } POST http://192.168.201.105:9200/movies/drama { "title": "Apocalypse Now", "director": "Francis Ford Coppola", "year": 1979, "genres": ["Drama", "War"] } POST http://192.168.201.105:9200/movies/drama { "title": "Kill Bill: Vol. 1", "director": "Quentin Tarantino", "year": 2003, "genres": ["Action", "Crime", "Thriller"] } POST http://192.168.201.105:9200/movies/drama { "title": "The Assassination of Jesse James by the Coward Robert Ford", "director": "Andrew Dominik", "year": 2007, "genres": ["Biography", "Crime", "Drama"] }
_search 第一种通过url检索:
http://localhost:9200/<index>/<type>/_search
post http://192.168.201.105:9200/_search post http://192.168.201.105:9200/movie/_search post http://192.168.201.105:9200/movie/crime/_search
注意分类一定要添加索引才可以查询,如果索引不正确会导致直接报错error,而非查无结果。
正文检索 -DSL query:
简单字符串查询 query_string
POST http://192.168.201.105:9200/_search {"query": {"query_string": { "query": "Kill" }}}
执行结果:会查到与Kill有关的所有的信息。
增加fields可以缩小查询的范围,约束查询指定的属性。
POST http://192.168.201.105:9200/_search {"query": {"query_string": { "query": "Bill", "fields": [ "title" ] }}}
此时也就约束仅仅查询属性为title 的内容。
增加过滤条件 filter:
在elasticsearch5.0废弃:
"filtered": { "query": {}, "filter": {} } no [query] registered for [filtered]
改为:
POST http://192.168.201.105:9200/_search {"query": { "multi_match": { "query": "kill", "fields": ["title"] } }}
具体查询详见ElasticSearch的DSL说明。
_bulk 批量导入:
我们如果希望批量向elasticsearch中导入数据:
post _bulk {"index":{"_index":"myindex","_type":"fulltext","_id":"123456"}} {"content":"你好China6","title1":"你好World6"} {"index":{"_index":"myindex","_type":"fulltext","_id":"123457"}} {"content":"你好China7","title1":"你好World7"}
索引
多索引查询:
http://ip:port/_index1,_index2,.../_search
POST myindex,indextest/_search { "query": { "term": { "content": { "value": "中国" } } } }
自动创建索引关闭 elasticsearch.yml:
action.auto_create_index:false
index.mapper.dynamic:false限制只允许(+)和不允许(-)以什么开头创建的索引:
action.auto_create_index:+acc*,-bank*
创建索引带有设置5个分片3个复制品:
PUT myindex2 { "settings" : { "index" : { "number_of_shards" : 5, "number_of_replicas" : 3 } } }
----------------
>get myindex3 //测试索引是否存在
>POST myindex2/_close //关闭索引
>POST myindex2/_open //开启索引
>GET myindex2/_settings //查看索引设置>POST myindex2/_analyze // 字词分解查看
POST myindex2/_analyze { "analyzer" : "standard", "text" : "I am a worker" }
>myindex2/_aliases?pretty=true创建别名,可将多个索引使用一个别名绑定PUT myindex2/_aliases?pretty=true { "actions": [ { "add": {"index": "myindex2", "alias": "indx"} } ] }
>get myindex2/_stats //查看索引下的一些状态信息
>POST _template/[temp_id] //创建索引模板,很有用,这样类似的索引就不需要单独设置mapping和setting了。
创建索引模板:
index_patterns 选择index匹配规则,此处以ik开头或以ik结尾的index都使用此template。
type1 为设置默认类型,_source 中enabled表示source是否可见。
这样在创建index后会默认使用template的设置。
POST _template/temp_ik { "index_patterns": ["ik_*", "*_ik"], "settings": { "number_of_shards": 2 }, "mappings": { "type1": { "_source": { "enabled": false }, "properties": { "title": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }, "name":{ "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }, "content":{ "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }, "create_date": { "type": "date", "format": "EEE MMM dd HH:mm:ss Z YYYY" } } } } }
>delete _template/[temp_id]
>delete myindex2 //删除索引
>get [index]/_flush //刷新清除数据,将缓存内存中的index数据存入到存储中
>get [index]/_refresh //刷新
elasticsearch.yml
主要模块说明:
参照 https://www.yiibai.com/elasticsearch/elasticsearch_modules.html