我们现在都知道python的多线程是个坑了,那么多进程在这个时候就变得很必要了。多进程实现了多CPU的利用,效率简直棒棒哒~~~
拥有一个多进程程序:



1 #!/usr/bin/env python 2 #-*-coding:utf-8-*- 3 __author__ = 'Eva_J' 4 import multiprocessing 5 import time 6 7 def func(msg): 8 for i in range(3): 9 print msg 10 time.sleep(1) 11 12 if __name__ == "__main__": 13 p = multiprocessing.Process(target=func, args=("hello", )) 14 p.start() 15 p.join() 16 print "have done."
按照上面的方法,我们就在自己的代码中启动了一个子进程,需要注意的是要想启动一个子进程,必须加上那句if __name__ == "main",否则就会报错。 查看了官方文档说:Safe importing of main module,Make sure that the main module can be safely imported by a new Python interpreter without causing unintended side effects (such a starting a new process).大概就是说,如果我们必须确定当前已经引入了主模块,来避免一些非预期的副作用。。。总之,加上!就对了!!!
进程池:

1 #!/usr/bin/env python 2 #-*-coding:utf-8-*- 3 __author__ = 'Eva_J' 4 def func(msg): 5 print msg,'*** in func' 6 time.sleep(3) 7 8 if __name__ == "__main__": 9 # 10 pool = multiprocessing.Pool(processes=5) 11 for i in xrange(3): 12 print i 13 pool.apply_async(func, ("hello %d" %(i), )) 14 #pool.apply(func, ("hello %d" %(i), )) 15 pool.close() 16 #pool.terminate() #结束工作进程,不在处理未完成的任务 17 pool.join() #主进程阻塞,等待子进程的退出, join方法要在close或terminate之后使用 18 print "have done."
上图中的方法就是进程池的使用,这里重点的介绍一些进程池相关的方法。
首先,我们为进程注入func,有两种方式:apply_async表示异步,就是子进程接收到请求之后就各自去执行了,而apply表示同步,子进程们将一个一个的执行,后一个子进程的执行永远以前一个子进程的结束为信号,开始执行。还是吃饭的例子。。。异步就是当我通知子进程要去吃饭的时候,他们就同时去吃饭了,同步就是他们必须一个一个的去,前一个没回来,后一个就不能去。
close方法:说关闭进程池,至此,进程池中不在有进程可以接受任务。
terminate和join是一对方法,表示的内容截然相反,执行terminate是结束当前进程池中的所有进程,不管值没执行完。join方法是阻塞主进程,等待子进程执行完毕,再继续执行主进程。需要注意的是:这两个方法都必须在close方法之后执行。当然我们也可以不执行这两个方法,那么子进程和主进程就各自执行各自的,无论执行到哪里,子进程会随着主进程的结束而结束。。。
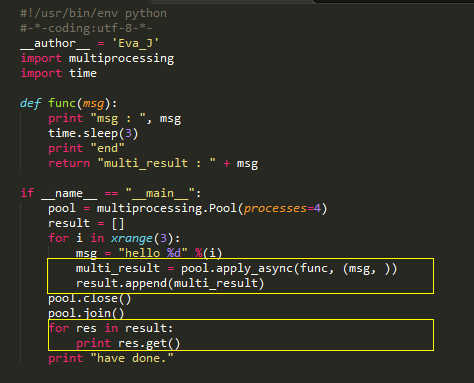
获取进程池中进程的执行结果:
1 #!/usr/bin/env python 2 #-*-coding:utf-8-*- 3 __author__ = 'Eva_J' 4 import multiprocessing 5 import time 6 7 def func(msg): 8 print "msg : ", msg 9 time.sleep(3) 10 print "end" 11 return "multi_result : " + msg 12 13 if __name__ == "__main__": 14 pool = multiprocessing.Pool(processes=4) 15 result = [] 16 for i in xrange(3): 17 msg = "hello %d" %(i) 18 multi_result = pool.apply_async(func, (msg, )) 19 result.append(multi_result) 20 pool.close() 21 pool.join() 22 for res in result: 23 print res.get() 24 print "have done."
没啥好说的,区别在黄框框里,自取不谢~~~
进程之间的内存共享:
我们之前说过,正常情况下,每个进程都拥有自己的内存空间,因此进程间的内存是无法共享的。
但是python却提供了我们方法,让我们程序的子进程之间实现简单的数据共享。
一个是Array数组,一个是multiprocessing模块中的Manager类。需要注意的是,Array数组的大小必须固定,Manager需要在linux系统下运行。代码在下面啦!!
1 #!/usr/bin/env python 2 #-*-coding:utf-8-*- 3 __author__ = 'Eva_J' 4 #方法一,Array 5 from multiprocessing import Process,Array 6 temp = Array('i', [11,22,33,44]) 7 8 def Foo(i): 9 temp[i] = 100+i 10 for item in temp: 11 print i,'----->',item 12 13 for i in range(2): 14 p = Process(target=Foo,args=(i,)) 15 p.start()
1 #!/usr/bin/env python 2 #-*-coding:utf-8-*- 3 __author__ = 'Eva_J' 4 #方法二:manage.dict()共享数据 5 from multiprocessing import Process,Manager 6 7 manage = Manager() 8 9 dic = manage.dict() 10 11 def Foo(i): 12 dic[i] = 100+i 13 print dic.values() 14 15 if __name__ == "__main__": 16 for i in range(2): 17 p = Process(target=Foo,args=(i,)) 18 p.start() 19 p.join()
参考文献:
python进程池:http://www.cnblogs.com/kaituorensheng/p/4465768.html
python多进程的使用示例:http://outofmemory.cn/code-snippet/2267/Python-duojincheng-multiprocessing-usage-example
python的线程、进程和协程:http://www.cnblogs.com/wupeiqi/articles/5040827.html
python的内存共享:http://www.cnblogs.com/dkblog/archive/2011/03/14/1983250.html
python的多进程编程:http://www.cnblogs.com/kaituorensheng/p/4445418.html