输入变量与输出变量均为连续变量的预测问题是回归问题;
输出变量为有限个离散变量的预测问题成为分类问题;
其实回归问题和分类问题的本质一样,都是针对一个输入做出一个输出预测,其区别在于输出变量的类型。
分类问题是指,给定一个新的模式,根据训练集推断它所对应的类别(如:+1,-1),是一种定性输出,也叫离散变量预测;
回归问题是指,给定一个新的模式,根据训练集推断它所对应的输出值(实数)是多少,是一种定量输出,也叫连续变量预测。
举个例子:预测明天的气温是多少度,这是一个回归任务;预测明天是阴、晴还是雨,就是一个分类任务。
导入要用到的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
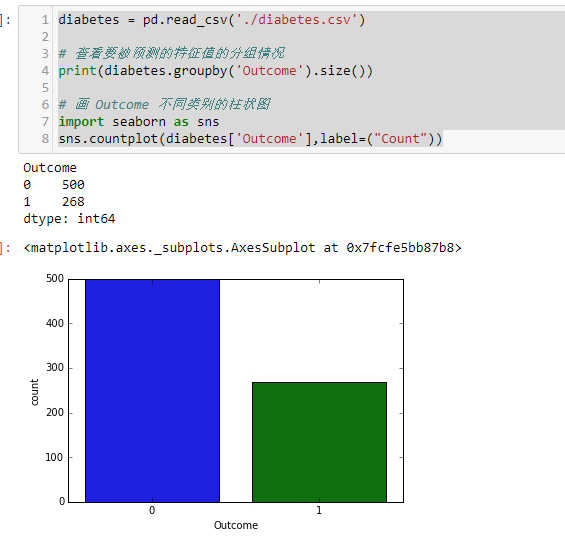
输出要被分类的特征列,柱状图可能更加直观
diabetes = pd.read_csv('./diabetes.csv')
# 查看要被预测的特征值的分组情况
print(diabetes.groupby('Outcome').size())
# 画 Outcome 不同类别的柱状图
import seaborn as sns
sns.countplot(diabetes['Outcome'],label=("Count"))
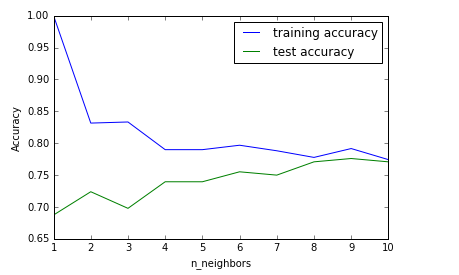
KNN 模型准确率的折线图
from sklearn.model_selection import train_test_split
# 参数stratify: 依据标签y,按原数据y中各类比例,分配给train和test,使得train和test中各类数据的比例与原数据集一样。
X_train,X_test, y_train, y_test = train_test_split(diabetes.loc[:,diabetes.columns != 'Outcome'],diabetes['Outcome'],stratify=diabetes['Outcome'],random_state=66)
# 开始 KNN
from sklearn.neighbors import KNeighborsClassifier
training_accuracy = []
test_accuracy = []
neighbors_settings = range(1, 11)
for n_neighbors in neighbors_settings:
# build the model
knn = KNeighborsClassifier(n_neighbors=n_neighbors)
knn.fit(X_train,y_train)
# record training set accuracy
training_accuracy.append(knn.score(X_train,y_train))
test_accuracy.append(knn.score(X_test,y_test))
plt.plot(neighbors_settings,training_accuracy,label="training accuracy")
plt.plot(neighbors_settings,test_accuracy,label="test accuracy")
plt.ylabel("Accuracy")
plt.xlabel("n_neighbors")
plt.legend()
plt.savefig('knn_compare_model')
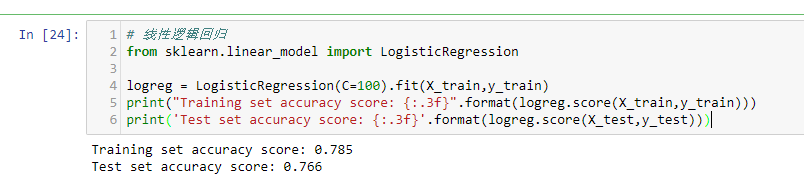
线性逻辑回归 准确率的打印以及 图形展示
# 线性逻辑回归
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression(C=1).fit(X_train,y_train)
print("Training set accuracy score: {:.3f}".format(logreg.score(X_train,y_train)))
print('Test set accuracy score: {:.3f}'.format(logreg.score(X_test,y_test)))
# 正则化参数为 100
logreg100 = LogisticRegression(C=100).fit(X_train,y_train)
logreg001 = LogisticRegression(C=0.001).fit(X_train,y_train)
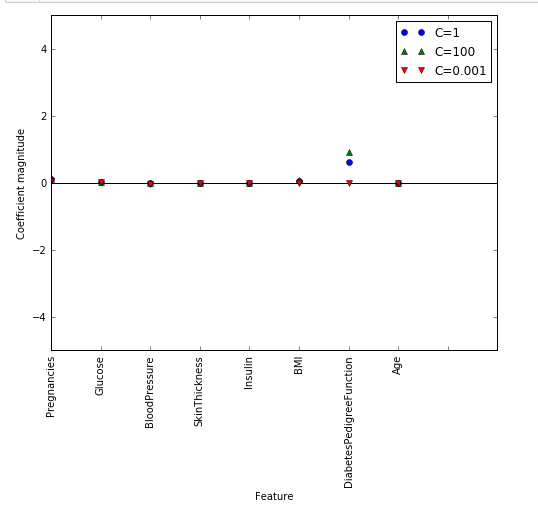
diabetes_features = [x for i,x in enumerate(diabetes.columns) if i!=8]
plt.figure(figsize=(8,6))
plt.plot(logreg.coef_.T, 'o',label="C=1")
plt.plot(logreg100.coef_.T, '^',label="C=100")
plt.plot(logreg001.coef_.T, 'v', label="C=0.001")
plt.xticks(range(diabetes.shape[1]), diabetes_features,rotation=90)
plt.hlines(0,0,diabetes.shape[1])
plt.ylim(-5,5)
plt.xlabel("Feature")
plt.ylabel("Coefficient magnitude")
plt.legend()
plt.savefig("log_coef")
决策树分类器
# 决策树分类器
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(random_state=0)
tree.fit(X_train,y_train)
print("Accuracy on training set: {:.3f}".format(tree.score(X_train,y_train)))
print("Accuracy on test set: {:.3f}".format(tree.score(X_test,y_test)))
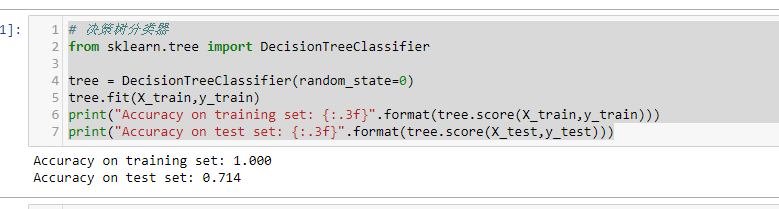
训练集的准确度可以高达100%,而测试集的准确度相对就差了很多。这表明决策树是过度拟合的,不能对新数据产生好的效果。因此,我们需要对树进行预剪枝。
我们设置max_depth=3,限制树的深度以减少过拟合。这会使训练集的准确度降低,但测试集准确度提高。
tree = DecisionTreeClassifier(max_depth=3, random_state=0)
tree.fit(X_train, y_train)
print("Accuracy on training set: {:.3f}".format(tree.score(X_train,y_train)))
print("Accuracy on test set: {:.3f}".format(tree.score(X_test,y_test)))

决策树中特征重要度
决策树中的特征重要度是用来衡量每个特征对于预测结果的重要性的。对每个特征有一个从0到1的打分,0表示“一点也没用”,1表示“完美预测”。各特征的重要度加和一定是为1的。
特征重要度:
[ 0.04554275 0.6830362 0. 0. 0. 0.27142106 0. 0. ]
然后我们能可视化特征重要度:
def plot_feature_importances_diabetes(model):
plt.figure(figsize=(8,6))
n_features = 8
plt.barh(range(n_features), model.feature_importances_,align='center')
plt.yticks(np.arange(n_features), diabetes_features)
plt.xlabel("Feature importance")
plt.ylabel("Feature")
plt.ylim(-1, n_features)
plot_feature_importances_diabetes(tree)
plt.savefig('feature_importance')
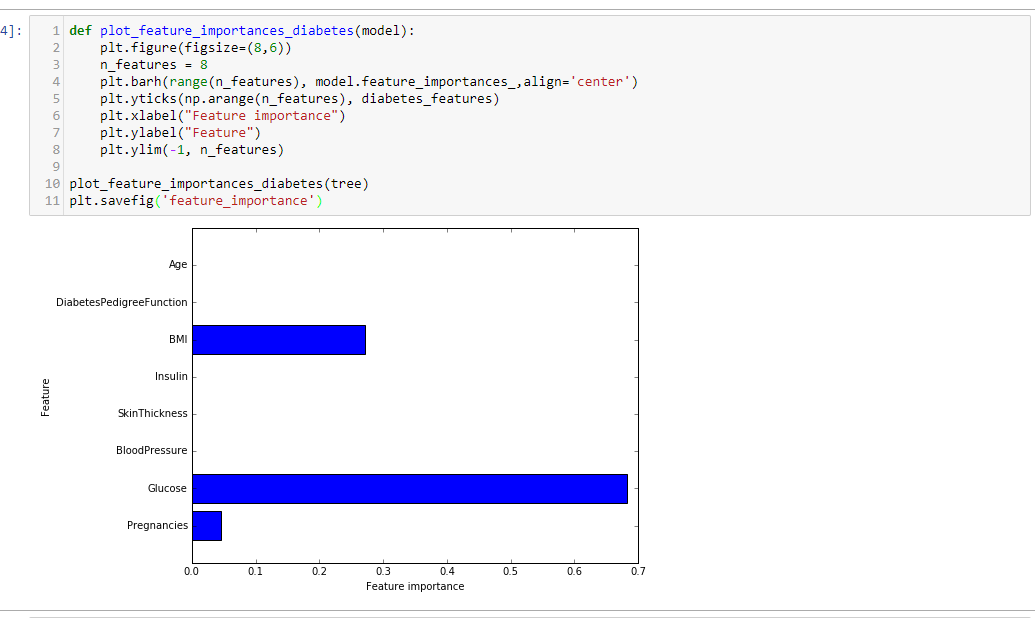
上图可以看出 特征“血糖”是目前最重要的特征。
与单一决策树相似,随机森林的结果仍然显示特征“血糖”的重要度最高,但是它也同样显示“BMI(身体质量指数)”在整体中是第二重要的信息特征。随机森林的随机性促使算法考虑了更多可能的解释,这就导致随机森林捕获的数据比单一树要大得多
梯度提升
# 梯度提升
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier(random_state=0)
gb.fit(X_train, y_train)
print("Accuracy on training set: {:.3f}".format(gb.score(X_train,y_train)))
print("Accuracy on test set: {:.3f}".format(gb.score(X_test,y_test)))

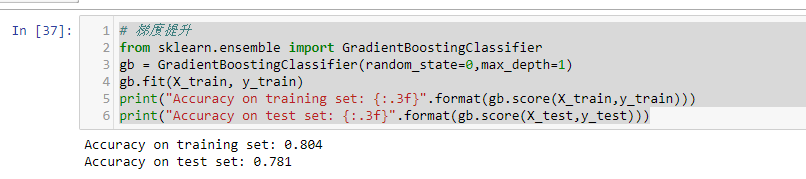
我们可能是过拟合了。为了降低这种过拟合,我们可以通过限制最大深度或降低学习速率来进行更强的修剪:
# 梯度提升
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier(random_state=0,max_depth=1)
gb.fit(X_train, y_train)
print("Accuracy on training set: {:.3f}".format(gb.score(X_train,y_train)))
print("Accuracy on test set: {:.3f}".format(gb.score(X_test,y_test)))
# 梯度提升
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier(random_state=0,max_depth=0.01)
gb.fit(X_train, y_train)
print("Accuracy on training set: {:.3f}".format(gb.score(X_train,y_train)))
print("Accuracy on test set: {:.3f}".format(gb.score(X_test,y_test)))
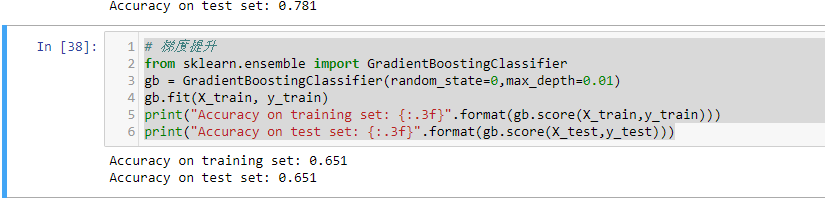
如我们所期望的,两种降低模型复杂度的方法都降低了训练集的准确度。可是测试集的泛化性能并没有提高。
尽管我们对这个模型的结果不是很满意,但我们还是希望通过特征重要度的可视化来对模型做更进一步的了解。
我们可以看到,梯度提升树的特征重要度与随机森林的特征重要度有点类似,同时它给这个模型的所有特征赋了重要度值。
支持向量机
# 支持向量机
from sklearn.svm import SVC
svc = SVC()
svc.fit(X_train, y_train)
print("Accuracy on training set: {:.2f}".format(svc.score(X_train, y_train)))
print("Accuracy on test set: {:.2f}".format(svc.score(X_test, y_test)))
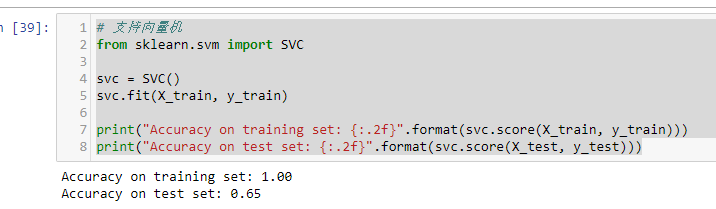
这个模型过拟合比较明显,虽然在训练集中有一个完美的表现,但是在测试集中仅仅有65%的准确度。
SVM要求所有的特征要在相似的度量范围内变化。我们需要重新调整各特征值尺度使其基本上在同一量表上。
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.fit_transform(X_test)
svc = SVC()
svc.fit(X_train_scaled,y_train)
print("Accuracy on training set: {:.2f}".format(svc.score(X_train_scaled,y_train)))
print("Accuracy on test set: {:.2f}".format(svc.score(X_test_scaled,y_test)))
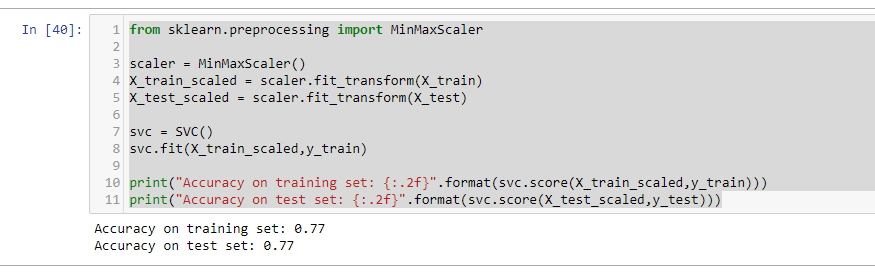
数据的度量标准化后效果大不同!现在我们的模型在训练集和测试集的结果非常相似,这其实是有一点过低拟合的,但总体而言还是更接近100%准确度的。这样来看,我们还可以试着提高C值或者gamma值来配适更复杂的模型。
svc = SVC(C=1000)
svc.fit(X_train_scaled,y_train)
print("Accuracy on training set: {:.3f}".format(svc.score(X_train_scaled,y_train)))
print("Accuracy on test set: {:.3f}".format(svc.score(X_test_scaled,y_test)))

深度学习
# 深度学习
from sklearn.neural_network import MLPClassifier
mlp = MLPClassifier(random_state=42)
mlp.fit(X_train, y_train)
print("Accuracy on training set: {:.2f}".format(mlp.score(X_train, y_train)))
print("Accuracy on test set: {:.2f}".format(mlp.score(X_test, y_test)))
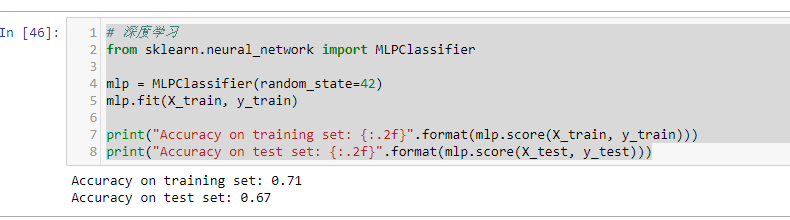
多层神经网络(MLP)的预测准确度并不如其他模型表现的好,这可能是数据的尺度不同造成的。深度学习算法同样也希望所有输入的特征在同一尺度范围内变化。理想情况下,是均值为0,方差为1。所以,我们必须重新标准化我们的数据,以便能够满足这些需求。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.fit_transform(X_test)
mlp = MLPClassifier(random_state=0)
mlp.fit(X_train_scaled, y_train)
print("Accuracy on training set: {:.3f}".format(mlp.score(X_train_scaled, y_train)))
print("Accuracy on test set: {:.3f}".format(mlp.score(X_test_scaled,y_test)))
# 让我们增加迭代次数: 然并卵。。。
mlp = MLPClassifier(max_iter=1000, random_state=0)
mlp.fit(X_train_scaled, y_train)
print("Accuracy on training set: {:.3f}".format(mlp.score(X_train_scaled, y_train)))
print("Accuracy on test set: {:.3f}".format(mlp.score(X_test_scaled, y_test)))

增加迭代次数仅仅提升了训练集的性能,而对测试集没有效果。
让我们调高alpha参数并且加强权重的正则化。
# 让我们调高alpha参数并且加强权重的正则化。
mlp = MLPClassifier(max_iter=1000, alpha=1, random_state=0)
mlp.fit(X_train_scaled, y_train)
print("Accuracy on training set: {:.3f}".format(mlp.score(X_train_scaled, y_train)))
print("Accuracy on test set: {:.3f}".format(mlp.score(X_test_scaled, y_test)))
这个结果是好的,但我们无法更进一步提升测试集准确度。
因此,到目前为止我们最好的模型是在数据标准化后的默认参数深度学习模型。
最后,我们绘制了一个在糖尿病数据集上学习的神经网络的第一层权重热图。
plt.figure(figsize=(20,5))
plt.imshow(mlp.coefs_[0], interpolation='none', cmap='viridis')
plt.yticks(range(8), diabetes_features)
plt.xlabel("Columns in weight matrix")
plt.ylabel("Input Feature")
plt.colorbar()
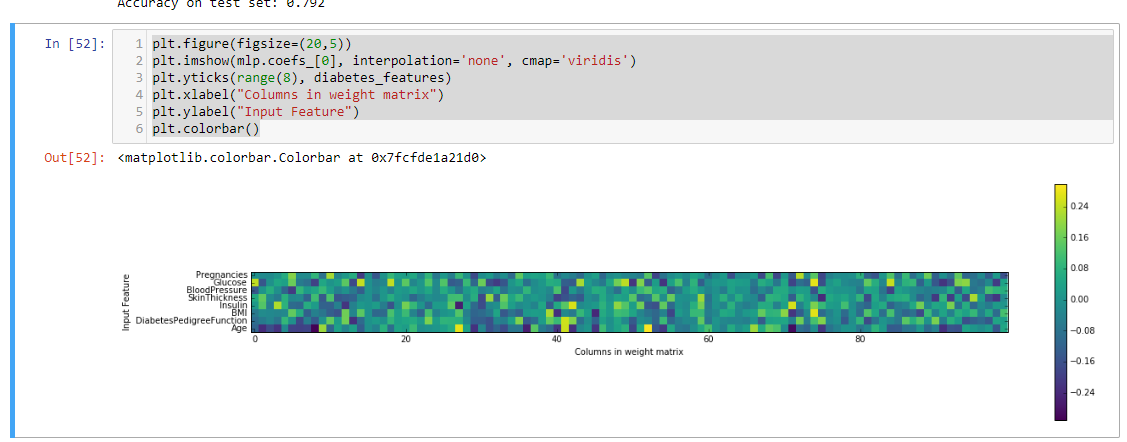
简单解释:
分类和回归的区别在于输出变量的类型。
定量输出称为回归,或者说是连续变量预测;
定性输出称为分类,或者说是离散变量预测。
举个例子:
预测明天的气温是多少度,这是一个回归任务;
预测明天是阴、晴还是雨,就是一个分类任务。
分类模型和回归模型本质一样,分类模型可将回归模型的输出离散化(下面例子1. 2. 4. 5.),回归模型也可将分类模型的输出连续化(下面例子3.)
举几个例子:
Logistic Regression 和 Linear Regression:
Linear Regression: 输出一个标量 wx+b,这个值是连续值,所以可以用来处理回归问题
Logistic Regression:把上面的 wx+b 通过 sigmoid 函数映射到(0,1)上,并划分一个阈值,大于阈值的分为一类,小于等于分为另一类,可以用来处理二分类问题
更进一步:对于N分类问题,则是先得到N组w值不同的 wx+b,然后归一化,比如用 softmax 函数,最后变成N个类上的概率,可以处理多分类问题
Support Vector Regression 和 Support Vector Machine:
SVR:输出 wx+b,即某个样本点到分类面的距离,是连续值,所以是回归模型
SVM:把这个距离用 sign(·) 函数作用,距离为正(在超平面一侧)的样本点是一类,为负的是另一类,所以是分类模型
Naive Bayes 用于分类 和 回归:
用于分类:y是离散的类别,所以得到离散的 p(y|x),给定 x ,输出每个类上的概率
用于回归:对上面离散的 p(y|x)求期望 ΣyP(y|x),就得到连续值。但因为此时y本身是连续的值,所以最地道的做法是,得到连续的概率密度函数p(y|x),然后再对y求期望。参考 http://www.cs.waikato.ac.nz/~eibe/pubs/nbr.pdf
前馈神经网络(如 CNN 系列) 用于 分类 和 回归:
用于回归:最后一层有m个神经元,每个神经元输出一个标量,m个神经元的输出可以看做向量 v,现全部连到一个神经元上,则这个神经元输出 wv+b,是一个连续值,可以处理回归问题,跟上面 Linear Regression 思想一样
用于N分类:现在这m个神经元最后连接到 N 个神经元,就有 N 组w值不同的 wv+b,同理可以归一化(比如用 softmax )变成 N个类上的概率(补充一下,如果不用 softmax,而是每个 wx+b 用一个 sigmoid,就变成多标签问题,跟多分类的区别在于,样本可以被打上多个标签)
循环神经网络(如 RNN 系列) 用于分类 和 回归:
用于回归 和 分类: 跟 CNN 类似,输出层的值 y = wv+b,可做分类可做回归,只不过区别在于,RNN 的输出跟时间有关,即输出的是 {y(t), y(t+1),...}序列(关于时间序列,见下面的更新)
上面的例子其实都是从 prediction 的角度举例的,如果从 training 角度来看,分类模型和回归模型的目标函数不同,分类常见的是 log loss, hinge loss, 而回归是 square loss(关于 loss function,又是另一个story了,在此不展开了)
==== 进一步思考后的重要更新,谈谈时间序列模型 ========
上面的例子 1~4 解决的是常见的分类/回归问题,而例5 解决的是 时间序列问题。
上面例1~4 的模型只适用于:这些样本的 y,没有时间上的相关性,比如:
人脸识别(分类问题),输入 x 是人脸的图像矩阵,识别目标 y 是人的ID,离散值,显然人与人的ID没有时间上的关系
人脸年龄预测(回归问题),输入 x 还是人脸图像矩阵,识别目标 y 是人的年龄,连续值,显然人与人之间的年龄亦没有时间上的关系
而当这些样本的 y 在时间上有相关性时,就变成了 时间序列问题,如果我们依然用非时间序列的方法来处理,就割裂了y的时间相关性,所以常见手段是用例5提到的RNN,(当然,还有 HMM, CRF 这些)但注意别用统计学里面那些愚蠢的 AR 模型(参考我的回答 时间序列建模问题,如何准确的建立时间序列模型? - 知乎用户的回答 - 知乎)。应用场景:
NLP 里的命名体识别(分类问题),输入是一句话,可以看做是由单词组成的时间序列(准确说是: 事件序列),输出是每个单词所属的标签
气温预测(回归问题),输入是历史时间的气温记录,输出是未来1天或多天的气温
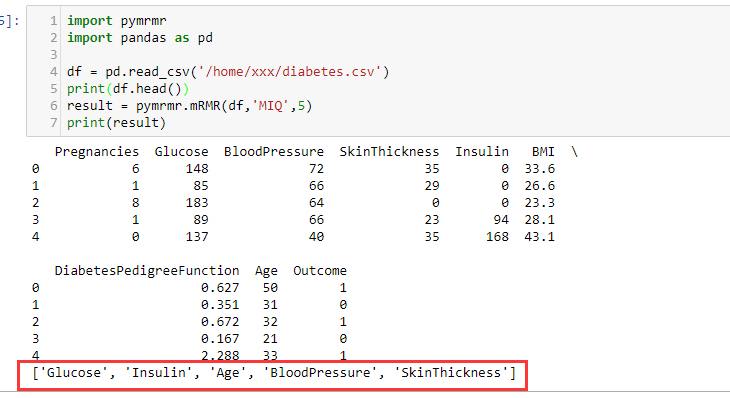
最大相关最小冗余mrmr
import pymrmr
import pandas as pd
df = pd.read_csv('/home/xxx/diabetes.csv')
print(df.head())
result = pymrmr.mRMR(df,'MIQ',5)
print(result)