作业1
UniversitiesRanking
# -*- coding:utf-8 -*-
import urllib.request
from bs4 import BeautifulSoup
url="http://www.shanghairanking.cn/rankings/bcur/2020"
resp = urllib.request.urlopen(url)
data = resp.read()
html = data.decode()
soup=BeautifulSoup(html,"html.parser") #利用requests和BeautifulSoup方法
university=soup.select("a[href$='university']") #制定筛选条件
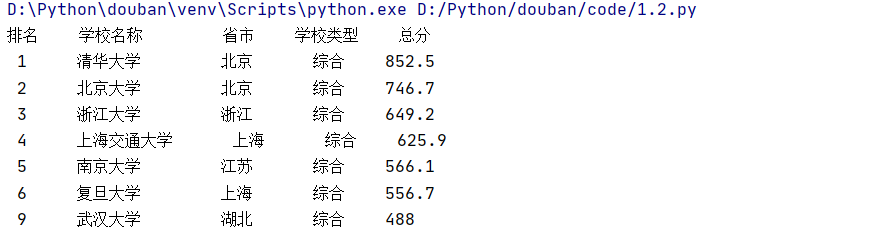
print("排名 学校名称 省市 学校类型 总分")
for ex in university:
tag=ex.parent
tank=tag.previous_sibling
area=tag.next_sibling
type=area.next_sibling
score=type.next_sibling #利用父子兄弟节点的获取方式获得需要的信息 #尽量把结果的格式装饰的好看一点
print(" "+tank.text.strip()+" "+ex.text.ljust(12,' ')+ area.text.strip()+" "+type.text.strip()+" "+score.text.strip(),chr(12288))
部分结果展示:
心得体会
因为是第一次设计并爬取网站,在有了足够的知识后,借鉴书上的代码,做出来这次的实验作业。这次的关键在于如何获取自己需要的,像省市,学校类型之类的东西。从网页源码中发现了可以利用父子兄弟节点的获取手段,成功爬出来自己需要的东西。这是意义重大的开始吧。
作业2
GoodsPrice
from bs4 import BeautifulSoup
import requests
import re
url="https://search.jd.com/Search?keyword=%E5%85%94%E5%AD%90&enc=utf-8&wq=%E5%85%94%E5%AD%90&pvid=4922ba49ea384a7384758e4f77476cb4"
r = requests.get(url, timeout=30)
r.encoding = 'utf-8'
html = r.text
soup=BeautifulSoup(html,"html.parser")
price_all=soup.select(" div[class='p-price'] strong i") #从源码中找到需要的信息所在地
name_first=soup.select("div[class='gl-i-wrap'] div[class='p-name p-name-type-2'] a em") #再次通过筛选得到更加准确的结果
# for name in name_first:
# print(name.text)
print("价格 "+"商品名")
for i in range(len(price_all)): #实测可以发现,有几个特殊的商品后面会带上换行,所以这里去掉换行符
print(price_all[i].text+" "+name_first[i].text.replace("
",""))
# print(name,price for name in name_first for price in price_all)
部分结果展示:

心得体会
这是在京东爬取“兔子”这个标签得到的信息。在查看标签时,发现最先完成的测试代码总是会多出一部分价格标签,再很纳闷的同时发现了,不是价格的问题,是商品名称后面总是会跟着一个空着的行,我看了网页的源码之后,也很不清楚为什么会多带一个换行的东西出来。
作业3
JPGFileDownload
import requests
import bs4
import os
from bs4 import BeautifulSoup
url = "http://xcb.fzu.edu.cn"
r = requests.get(url, timeout=30)
r.encoding = 'utf-8'
html = r.text
soup=BeautifulSoup(html,"html.parser")
pic_all=soup.find_all("img") #常规操作
shuchu=[] #结果存在这个里面
x=0
for s in pic_all:
p=s["src"] #找到src带着的东西
# shuchu.append(p)
if p[-2]=='p' or p[-2]=='P': #因为只需要jpg形式的图片,所以设置筛选的条件,倒数第二个是P或者p就能添加进去
shuchu.append(p)
print(shuchu)
for src in shuchu:
if src[0]=='/':
src='http://xcb.fzu.edu.cn'+src #结果的存入操作
with open("./File/"+os.path.basename(src),'wb') as f:
f.write(requests.get(src).content)
部分结果展示:

心得体会
这次是爬取网站上面的所有JPG形式的图片,在观察了网页源码之后发现,jpg和JPG形式的大小写的都有,所以在找到img后,把png形式的图片全都去掉,结果在保存在文件夹中就行了。