原文链接:https://mp.weixin.qq.com/s/qESZSzHoxUKQRJhb1EQA_Q
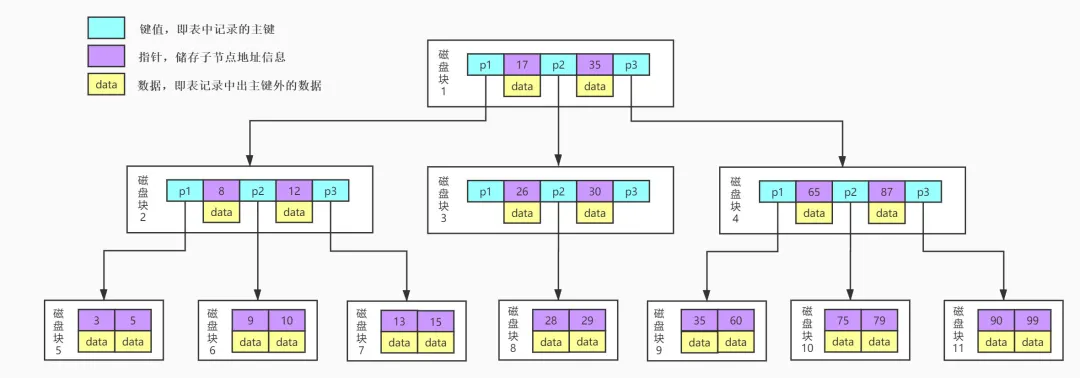
1.B-Tree结构:
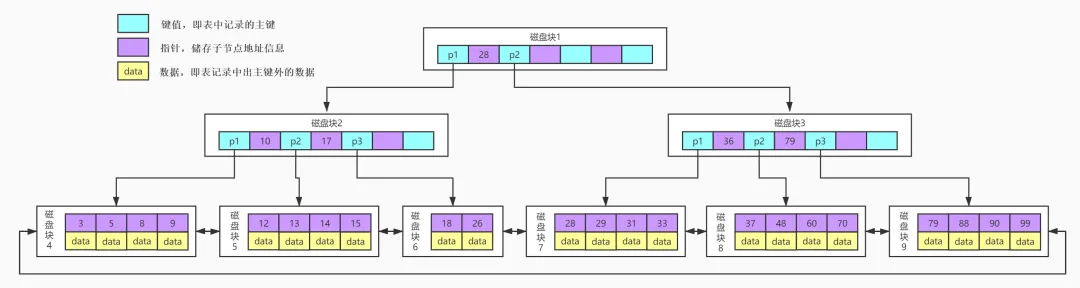
2.B+Tree结构
B+Tree相对于B-Tree做了哪些优化?
B-Tree每个节点中不仅包含数据的key值,还有data值。而每一个页的存储空间是有限的,如果data数据较大时将会导致每个节点(即一个页)能存储的key的数量很小,当存储的数据量很大时同样会导致B-Tree的深度较大,增大查询时的磁盘I/O次数,进而影响查询效率。
B+Tree是在B-Tree基础上的一种优化,使其更适合实现外存储索引结构。在B+Tree中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低B+Tree的高度。
B+Tree相对于B-Tree有几点不同:
非叶子节点只存储键值信息, 数据记录都存放在叶子节点中, 将上一节中的B-Tree优化,由于B+Tree的非叶子节点只存储键值信息,所以B+Tree的高度可以被压缩到特别的低。
而且在B+Tree上通常有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。所以我们除了可以对B+Tree进行主键的范围查找和分页查找,还可以从根节点开始,进行随机查找。
数据库中的B+Tree索引可以分为聚集索引(clustered index)和辅助索引(secondary index)。
上面的B+Tree示例图在数据库中的实现即为聚集索引,聚集索引的B+Tree中的叶子节点存放的是整张表的行记录数据,辅助索引与聚集索引的区别在于辅助索引的叶子节点并不包含行记录的全部数据,而是存储相应行数据的聚集索引键,即主键。
当通过辅助索引来查询数据时,InnoDB存储引擎会遍历辅助索引找到主键,然后再通过主键在聚集索引中找到完整的行记录数据。
不过,虽然索引可以加快查询速度,提高 MySQL 的处理性能,但是过多地使用索引也会造成以下弊端:
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
- 除了数据表占数据空间之外,每一个索引还要占一定的物理空间。如果要建立聚簇索引,那么需要的空间就会更大。
- 当对表中的数据进行增加、删除和修改的时候,索引也要动态地维护,这样就降低了数据的维护速度。
索引只是提高效率的一个因素,因此在建立索引的时候应该遵循以下原则:
- 在经常需要搜索的列上建立索引,可以加快搜索的速度。
- 在作为主键的列上创建索引,强制该列的唯一性,并组织表中数据的排列结构。
- 在经常使用表连接的列上创建索引,这些列主要是一些外键,可以加快表连接的速度。
- 在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,所以其指定的范围是连续的。
- 在经常需要排序的列上创建索引,因为索引已经排序,所以查询时可以利用索引的排序,加快排序查询。
- 在经常使用 WHERE 子句的列上创建索引,加快条件的判断速度。