在Python中,装饰器和迭代器、生成器都是非常重要的高级函数。
在讲装饰器之前,我们先要学习以下三个内容:
一、函数的作用域
1、作用域介绍
Python中的作用域分为四种情况:
- L:local,局部作用域,即函数中定义的变量;
- E:enclosing,嵌套的父级函数的局部作用域,即包含此函数的上级函数的局部作用域,但不是全局的;
- G:globa,全局变量,就是模块级别定义的变量;
- B:built-in,系统固定模块里面的变量,比如int, bytearray等。
搜索变量的优先级顺序依次是:L –> E –> G –>B,即:局部作用域>外层作用域>当前模块中的全局>Python内置作用域。
1 x = int(2.9) # int built-in 2 3 g_count = 0 # global 4 5 def outer(): 6 o_count = 1 # enclosing 7 def inner(): 8 i_count = 2 # local 9 print(o_count) 10 print(i_count) # 找不到 11 inner() 12 outer() 13 14 print(o_count) #找不到
当然,local和enclosing是相对的,enclosing变量相对上层来说也是local。
2、作用域的产生
在Python中,只有函数(def、lambda)、类(class)以及模块(module)才会引入新的作用域,其它的代码块(如if、try、for等)是不会引入新的作用域的,如下代码:
1 if 2>1: 2 x = 1 3 print(x) # 1
if并没有引入一个新的作用域,x仍处在当前作用域中,后面代码可以使用。
1 def test(): 2 x = 2 3 print(x) # NameError: name 'x2' is not defined
上面这段代码则会报错,因为def、class、lambda是可以引入新作用域的。
3、变量的修改
1 x = 6 2 def f(): 3 print(x) 4 x = 5 5 f() 6 7 # 错误的原因在于print(x)时,解释器会在局部作用域找,会找到x=5(函数已经加载到内存),但x使用在声明前了,所以报错: 8 # local variable 'x' referenced before assignment.如何证明找到了x=5呢?简单:注释掉x=5,x=6,报错为:name 'x' is not defined 9 10 # 同理 11 x = 6 12 def f(): 13 x += 1 # local variable 'x' referenced before assignment. 14 f()
4、global关键字
当内部作用域想修改外部作用域的变量时,就要用到global和nonlocal关键字了,当修改的变量是在全局作用域(global作用域)上的,就要使用global先声明一下,代码如下:
1 count = 10 2 def outer(): 3 global count 4 print(count) #10 5 count = 100 6 print(count) #100 7 outer() 8 print(count) #100
5、nonlocal关键字
global关键字声明的变量必须在全局作用域上,不能嵌套作用域上,当要修改嵌套作用域(enclosing作用域,外层非全局作用域)中的变量怎么办呢,这时就需要nonlocal关键字了,代码如下:
1 def outer(): 2 count = 10 3 def inner(): 4 nonlocal count 5 count = 20 6 print(count) #20 7 inner() 8 print(count) #20 9 outer()
6、作用域小结
- 变量查找顺序:LEGB,作用域局部>外层作用域>当前模块中的全局>python内置作用域;
- 只有函数、类以及模块才能引入新的作用域;
- 对于一个变量,内部作用域先声明就会覆盖外部变量,不声明直接使用,就会使用外部作用域的变量;
- 内部作用域要修改外部作用域变量的值时,全局变量要使用global关键字,嵌套作用域变量要使用nonlocal关键字。nonlocal是python3新增的关键字,有了这个 关键字,就能完美的实现闭包了;
二、函数即对象
在Python中,函数和之前学过的字符串、整型、列表等一样都是对象,而且函数是最高级的对象(对象是类的实例化,可以调用相应的方法,函数是包含变量的对象)。如下:
1 def foo(): 2 print('i am the foo') 3 bar() 4 5 def bar(): 6 print('i am the bar') 7 8 foo()
接着,我们再聊一下函数在内存的存储情况:

函数对象的调用仅仅比其它对象多了一个()而已!foo,bar与a,b一样都是个变量名。
既然函数是对象,那么自然满足下面两个条件:
1、函数可以被赋值给其他变量
1 def foo(): 2 print('foo') 3 bar=foo 4 bar() 5 foo() 6 print(id(foo),id(bar)) #1386464801520 1386464801520
2、函数可以被定义在另外一个函数内(作为参数或者返回值),类似于整型、字符串等对象
1 # *******函数名作为参数********** 2 def foo(func): 3 print('foo') 4 func() 5 6 def bar(): 7 print('bar') 8 9 foo(bar) 10 11 # *******函数名作为返回值********* 12 def foo(): 13 print('foo') 14 return bar 15 16 def bar(): 17 print('bar') 18 19 b = foo() 20 b()
三、函数的闭包
如下一个函数:
1 def foo(): 2 x = 1
3 def bar(): 4 print(x) 5 return bar
我们想要调用bar函数,有什么办法呢?,如下:
1 # 方法一 2 foo()() 3 4 # 方法二 5 func = foo() 6 func()
那么以上两种调用方式,有什么区别吗?
貌似没什么区别,但是有一个疑问:函数foo已经调用执行完毕了,再调用bar函数时,为什么没有报错(直接调用bar函数时却报错了)?
因为:函数foo return的bar函数是一个闭包函数,有x这个环境变量。
1、闭包函数
定义:如果在一个函数里,对在外部作用域(但不是在全局作用域)的变量进行引用,那么内部函数就被认为是一个闭包函数;
如上实例,bar就是内部函数,bar里引用了外部作用域的变量x(x在外部作用域foo里面,不是全局作用域),则这个内部函数bar就是一个闭包函数;
再稍微讲究一点的解释是,闭包=函数块+定义函数时的环境,bar就是函数块,x就是环境,当然这个环境可以有很多,不止一个简单的x;
2、用途
用途一:
1 # 用途1:当闭包执行完后,仍然能够保持住当前的运行环境。 2 # 比如说,如果你希望函数的每次执行结果,都是基于这个函数上次的运行结果。我以一个类似棋盘游戏的例子 3 # 来说明。假设棋盘大小为50*50,左上角为坐标系原点(0,0),我需要一个函数,接收2个参数,分别为方向 4 # (direction),步长(step),该函数控制棋子的运动。棋子运动的新的坐标除了依赖于方向和步长以外, 5 # 当然还要根据原来所处的坐标点,用闭包就可以保持住这个棋子原来所处的坐标。 6 7 origin = [0, 0] # 坐标系统原点 8 legal_x = [0, 50] # x轴方向的合法坐标 9 legal_y = [0, 50] # y轴方向的合法坐标 10 def create(pos=origin): 11 def player(direction,step): 12 # 这里应该首先判断参数direction,step的合法性,比如direction不能斜着走,step不能为负等 13 # 然后还要对新生成的x,y坐标的合法性进行判断处理,这里主要是想介绍闭包,就不详细写了。 14 new_x = pos[0] + direction[0]*step 15 new_y = pos[1] + direction[1]*step 16 pos[0] = new_x 17 pos[1] = new_y 18 #注意!此处不能写成 pos = [new_x, new_y],原因在上文有说过 19 return pos 20 return player 21 22 player = create() # 创建棋子player,起点为原点 23 print (player([1,0],10)) # 向x轴正方向移动10步 24 print (player([0,1],20)) # 向y轴正方向移动20步 25 print (player([-1,0],10)) # 向x轴负方向移动10步
用途二:
1 # 用途2:闭包可以根据外部作用域的局部变量来得到不同的结果,这有点像一种类似配置功能的作用,我们可以 2 # 修改外部的变量,闭包根据这个变量展现出不同的功能。比如有时我们需要对某些文件的特殊行进行分析,先 3 # 要提取出这些特殊行。 4 5 def make_filter(keep): 6 def the_filter(file_name): 7 file = open(file_name) 8 lines = file.readlines() 9 file.close() 10 filter_doc = [i for i in lines if keep in i] 11 return filter_doc 12 return the_filter 13 14 # 如果我们需要取得文件"result.txt"中含有"pass"关键字的行,则可以这样使用例子程序 15 filter = make_filter("pass") 16 filter_result = filter("result.txt")
四、装饰器
装饰器本质上是一个函数,该函数用来处理其他函数,它可以让其他函数在不需要修改代码的前提下增加额外的功能,装饰器的返回值也是一个函数对象。它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等应用场景。装饰器是解决这类问题的绝佳设计,有了装饰器,我们就可以抽离出大量与函数功能本身无关的雷同代码并继续重用。概括的讲,装饰器的作用就是为已经存在的对象添加额外的功能。
有如下一个函数:
1 def timer(): 2 print('timer')
我们要测试这个函数的执行时间,该怎么做?
1 import time 2 def timer(): 3 start_time = time.time() 4 print('timer') 5 time.sleep(1.22) 6 end_time = time.time() 7 print('执行时间为:%s'%(end_time-start_time)) 8 9 timer() #1.230109453201294
如果有成百上千个函数需要测试的话,这样做工作量就太大了,那么可以这样做:
1 import time 2 def timer(func): 3 start_time = time.time() 4 func() 5 end_time = time.time() 6 print('执行时间为:%s'%(end_time-start_time)) 7 8 def bar(): 9 time.sleep(1.23) 10 print('bar') 11 12 timer(bar) #1.2442445755004883
这么做貌似没什么问题了,但是我们发现函数的调用发生了变化,之前我们调用bar函数只要bar()就行了,现在则要用timer(bar)来调用。如果很多代码已经是写好了的,那么我们还要去修改源代码,显然,这样的方法是不可取的。那么,还有什么更好的方法呢?就要正式用到装饰器了,如下:
1 import time 2 def timer(func): 3 def deco(): 4 start_time = time.time() 5 func() 6 end_time = time.time() 7 print('执行时间为:%s'%(end_time-start_time)) 8 return deco 9 10 def bar(): 11 time.sleep(1.23) 12 print('bar') 13 14 bar = timer(bar) 15 bar()
函数timer就是装饰器,它把真正的业务方法func包裹在函数里面,看起来像bar被上下时间函数装饰了。在这个例子中,函数进入和退出时 ,被称为一个横切面(Aspect),这种编程方式被称为面向切面的编程(Aspect-Oriented Programming)。
1、简单的装饰器
上面这段代码基本实现了装饰器的功能,但和普通函数调用比起来,还多了一行:bar = timer(bar),我们可以在需要调用的函数前面加上@timer来替代这一行,如下:
1 import time 2 def timer(func): 3 def deco(): 4 start_time = time.time() 5 func() 6 end_time = time.time() 7 print('执行时间为:%s'%(end_time-start_time)) 8 return deco 9 10 @timer # bar = timer(bar) 11 def bar(): 12 time.sleep(1.23) 13 print('bar') 14 15 @timer # foo = timer(foo) 16 def foo(): 17 time.sleep(2.23) 18 print('foo') 19 20 bar() 21 foo()
如上所示,这样我们就可以省去bar = timer(bar)这一句了,直接调用bar()即可得到想要的结果。如果我们有其他的类似函数,我们可以继续调用装饰器来修饰函数,而不用重复修改函数或者增加新的封装。这样,我们就提高了程序的可重复利用性,并增加了程序的可读性。
这里需要注意的问题:foo = timer(foo)其实是把deco引用的对象引用给了foo,而deco里的变量func之所以可以用,就是因为deco是一个闭包函数。
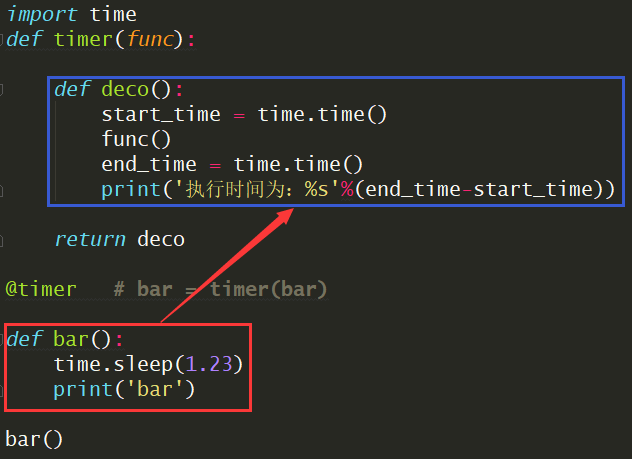
@timer帮我们做的事情就是当我们执行业务逻辑bar()时,执行的代码由红框部分转到蓝框部分,仅此而已。
装饰器在Python使用如此方便都要归因于Python的函数能像普通的对象一样能作为参数传递给其他函数,可以被赋值给其他变量,可以作为返回值,可以被定义在另外一个函数内。
2、带参数的被装饰函数
1 import time 2 def timer(func): 3 def deco(a,b): 4 start_time = time.time() 5 func(a,b) 6 end_time = time.time() 7 print('执行时间为:%s'%(end_time-start_time)) 8 return deco 9 10 @timer # bar = timer(bar) 11 def bar(a,b): 12 time.sleep(1.23) 13 print(a+b) 14 15 @timer # foo = timer(foo) 16 def foo(a,b): 17 time.sleep(2.23) 18 print(a-b) 19 20 bar(1,2) 21 foo(3,4)
3、不定长参数
1 import time 2 def timer(func): 3 def deco(*args,**kwargs): 4 start_time = time.time() 5 func(*args,**kwargs) 6 end_time = time.time() 7 print('执行时间为:%s'%(end_time-start_time)) 8 return deco 9 10 @timer # bar = timer(bar) 11 def add(*args,**kwargs): 12 time.sleep(1.23) 13 sum = 0 14 for i in args: 15 sum += i 16 print(sum) 17 18 add(1,2,3,4,5,6,7,8,9,10) #55
4、带参数的装饰器
装饰器还有更大的灵活性,例如带参数的装饰器:在上面的装饰器调用中,比如@timer,该装饰器唯一的参数就是执行业务的函数。装饰器的语法允许我们在调用时,提供其它参数,比如@decorator(a)。这样,就为装饰器的编写和使用提供了更大的灵活性。
1 import time 2 def time_logger(flag=0): 3 def timer(func): 4 def deco(*args,**kwargs): 5 start_time = time.time() 6 func(*args,**kwargs) 7 end_time = time.time() 8 print('执行时间为:%s'%(end_time-start_time)) 9 if flag: 10 print('将这个函数的执行时间记录到日志当中') 11 return deco 12 return timer 13 14 @time_logger(3) 15 def add(*args,**kwargs): 16 time.sleep(1.23) 17 sum = 0 18 for i in args: 19 sum += i 20 print(sum) 21 22 add(1,2,3,4,5,6,7,8,9,10)
@time_logger(3) 做了两件事:
(1)time_logger(3):得到闭包函数timer,里面保存环境变量flag
(2)@timer:add=timer(add)
上面的time_logger是允许带参数的装饰器。它实际上是对原有装饰器的一个函数封装,并返回一个装饰器(一个含有参数的闭包函数)。当我 们使用@time_logger(3)调用的时候,Python能够发现这一层的封装,并把参数传递到装饰器的环境中。
我们可以通过装饰器time_logger中的参数flag的值来控制是否将函数的执行时间写入日志,比如:flag=0就不写入,flag!=0就写入。
5、类装饰器
相比函数装饰器,类装饰器具有灵活度大、高内聚、封装性等优点。使用类装饰器还可以依靠类内部的__call__方法,当使用 @ 形式将装饰器附加到函数上时,就会调用此方法。
1 import time 2 3 class Foo(object): 4 def __init__(self,func): 5 self._func = func 6 7 def __call__(self): 8 start_time = time.time() 9 self._func() 10 end_time = time.time() 11 print('函数执行时间为:%s' % (end_time - start_time)) 12 13 @Foo 14 def bar(): 15 time.sleep(1.25) 16 print('bar') 17 18 bar()
可以看到,类装饰器没有嵌套关系了,直接使用类当中的__call__方法。
6、装饰器实例
用装饰器,写一个实例,判断用户是否登陆,逻辑是:运行程序,打印菜单,选择要进入的菜单,如果未登录,则要进行登录,如果是已登录则直接展示菜单。
1 import os 2 def login(): 3 ''' 4 登录函数,登录成功的话将username写入user文件当中 5 ''' 6 username = input('username:') 7 passwd = input('passwd:') 8 if username == 'admin' and passwd == '123456': 9 with open('user','a+',encoding='utf-8') as f: 10 f.write(username) 11 print('登录成功') 12 else: 13 print('用户名或密码错误') 14 15 def auth(func): 16 ''' 17 校验是否登录的装饰器 18 ''' 19 def check(*args,**kwargs): 20 if os.path.exists('user'): # 判断user文件是否存在 21 func(*args,**kwargs) # 假设user文件存在就代表登录成功,执行函数 22 else: 23 print('您还未登录') 24 login() # 不存在则调用登录函数 25 func(*args, **kwargs) # 登录成功后再执行函数 26 return check 27 28 @auth 29 def home(): 30 print('Welcome to Home Page!!') 31 32 @auth 33 def finance(): 34 print('Welcome to Finance Page!!') 35 36 @auth 37 def add(): 38 print('Welcome to AddProduct Page!!') 39 40 def menu(): # 打印菜单函数 41 msg = ''' 42 1:首页 43 2:金融 44 3:添加商品 45 ''' 46 print(msg) 47 m = { 48 "1":home, 49 "2":finance, 50 "3":add 51 } 52 choice = input('请输入您的选择:').strip() 53 if choice in m: 54 m[choice]() # 调用对应的函数 55 else: 56 print('输入错误') 57 menu() 58 59 60 if __name__ == '__main__': 61 menu()