以下转自:https://zhuanlan.zhihu.com/p/50808597
一、TFRecord
1、什么是TFRecord?

TFRecord 是Google官方推荐的一种数据格式,是Google专门为TensorFlow设计的一种数据格式。
tfrecord是一种文件格式,层层向下封装
-> tf.train.Example
-->tf.trian.Features ->{"key":tf.train.Feature}
--->tf.train.Feature ->tf.train.ByateList/FloatList/Int64List
实际上,TFRecord是一种二进制文件,其能更好的利用内存,其内部包含了多个tf.train.Example, 而Example是protocol buffer(protobuf) 数据标准[3][4]的实现,在一个Example消息体中包含了一系列的tf.train.feature属性,而 每一个feature 是一个key-value的键值对,其中,key 是string类型,而value 的取值有三种:
-
bytes_list:可以存储string和byte两种数据类型。float_list:可以存储float(float32)与double(float64)两种数据类型 。int64_list:可以存储:bool, enum, int32, uint32, int64, uint64。
值的一提的是,TensorFlow 源码中到处可见.proto 的文件,且这些文件定义了TensorFlow重要的数据结构部分,且多种语言可直接使用这类数据,很强大。
tf.Example类是一种将数据表示为{"string": value}形式的meassage类型,Tensorflow经常使用tf.Example来写入、读取TFRecord数据
一般来说,tf.Example都是{"string": tf.train.Feature}这样的键值映射形式。其中,tf.train.Feature类可以使用以下3种类型
-
tf.train.BytesList: 可以使用的类型包括string和byte -
tf.train.FloatList: 可以使用的类型包括float和double -
tf.train.Int64List: 可以使用的类型包括enum,bool,int32,uint32,int64以及uint64。
https://blog.csdn.net/codesamer/article/details/95588934
2、为什么使用TFRecord?
TFRecord 并非是TensorFlow唯一支持的数据格式,你也可以使用CSV或文本等格式,但是对于TensorFlow来说,TFRecord 是最友好的,也是最方便的。前面提到,TFRecord内部是一系列实现了protocol buffer数据标准的Example,从[3] 中我们看到,对于大型数据,对比其余数据格式,protocol buffer类型的数据优势很明显。
- 使用
TFRocord存储数据的好处:- 为了更加方便的建图,原来使用
placeholder的话,还要每次feed_dict一下,使用TFRecord+Dataset的时候直接就把数据读入操作当成一个图中的节点,就不用每次都feed了。 - 可以方便的和
Estimator进行对接。
- 为了更加方便的建图,原来使用
TFRecord以字典的方式进行数据的创建。

3、将数据转化为TFRecord文件
Google官方推荐在对于中大数据集来说,先将数据集转化为TFRecord数据(.tfrecords), 这样可加快你在数据读取, 预处理中的速度。
将数据转化为 tfrecord 格式只需要三步, 下面以三个features:context,question, answer为例 :
writer = tf.python_io.TFRecordWriter(out_file_name) # 1. 定义 writer对象 for data in dataes: context = dataes[0] question = dataes[1] answer = dataes[2] """ 2. 定义features """ example = tf.train.Example( features = tf.train.Features( feature = { 'context': tf.train.Feature( int64_list=tf.train.Int64List(value=context)), 'question': tf.train.Feature( int64_list=tf.train.Int64List(value=question)), 'answer': tf.train.Feature( int64_list=tf.train.Int64List(value=answer)) })) """ 3. 序列化,写入""" serialized = example.SerializeToString()
#####""" 压缩后:b' d 5 x0efavorite_booksx12# ! x10machine laerning deep learning x0c x03agex12x05x1ax03 x01x18 x1d x05hoursx12x14x12x12 x10x00x00hAx00x00xa0Ax00x00x08Bx9ax99xf9A'"""
writer.write(serialized)
这部分的代码可以参考该Github仓库:Reading Comprehension, 该仓库中,众多数据库的读写都采用了先转换为 tfrecords 的格式然后再读取的方式。
(1)创建一个writer
writer = tf.python_io.TFRecordWriter('%s.tfrecord' %'data')
(2)创建存储类型tf_feature
往.tfrecord里面写数据的时候首先要先定义写入数据项(feature)的类型。
int64:tf.train.Feature(int64_list = tf.train.Int64List(value=输入))float32:tf.train.Feature(float_list = tf.train.FloatList(value=输入))string:tf.train.Feature(bytes_list=tf.train.BytesList(value=输入))- 注:输入必须是list(向量),由于tensorflow feature类型只接受list数据,但是如果数据类型是矩阵或者张量的时候,有两种解决方法:
- 转成
list类型:将张量fatten成list(也就是向量),再用写入list的方式写入。 - 转成
string类型:将张量用.tostring()转换成string类型,再用tf.train.Feature(bytes_list=tf.train.BytesList(value=[input.tostring()]))来存储。 - 形状信息:不管那种方式都会使数据丢失形状信息,所以在向该样本中写入feature时应该额外加入shape信息作为额外feature。shape信息是int类型,这里我是用原feature名字+'_shape'来指定shape信息的feature名。
- 转成
# 这里我们将会写3个样本,每个样本里有4个feature:标量,向量,矩阵,张量 for i in range(3): # 创建字典 features={} # 写入标量,类型Int64,由于是标量,所以"value=[scalars[i]]" 变成list features['scalar'] = tf.train.Feature(int64_list=tf.train.Int64List(value=[scalars[i]])) # 写入向量,类型float,本身就是list,所以"value=vectors[i]"没有中括号 features['vector'] = tf.train.Feature(float_list = tf.train.FloatList(value=vectors[i])) # 写入矩阵,类型float,本身是矩阵,一种方法是将矩阵flatten成list features['matrix'] = tf.train.Feature(float_list = tf.train.FloatList(value=matrices[i].reshape(-1))) # 然而矩阵的形状信息(2,3)会丢失,需要存储形状信息,随后可转回原形状 features['matrix_shape'] = tf.train.Feature(int64_list = tf.train.Int64List(value=matrices[i].shape)) # 写入张量,类型float,本身是三维张量,另一种方法是转变成字符类型存储,随后再转回原类型 features['tensor'] = tf.train.Feature(bytes_list=tf.train.BytesList(value=[tensors[i].tostring()])) # 存储丢失的形状信息(806,806,3) features['tensor_shape'] = tf.train.Feature(int64_list = tf.train.Int64List(value=tensors[i].shape))
(3)将 tf_feature 转换成 tf_example 以及进行序列化
# 将存有所有feature的字典送入tf.train.Features中 tf_features = tf.train.Features(feature= features) # 再将其变成一个样本example tf_example = tf.train.Example(features = tf_features) # 序列化该样本 tf_serialized = tf_example.SerializeToString()
(4)写入样本,关闭文件
# 写入一个序列化的样本 writer.write(tf_serialized) # 由于上面有循环3次,所以到此我们已经写了3个样本 # 关闭文件 writer.close()
将其他文件转化成tfrecord
https://blog.csdn.net/chengshuhao1991/article/details/78656724
TensorFlow2.X——从csv文件中读取数据生成tfrecord文件
4、TFRecord文件的读取
在新的API中,只需要简单的使用 tf.data.TFRecordDataset 就能够轻松的读取数据,高效便捷。 强烈建议使用 tf.data 来完成数据的读取操作,值得一提的是,旧的数据读取接口在最新的TensorFlow API 中已经完全舍弃了。
tf.data 可以与 Keras, estimator 等高层API 合作,同时也可以与底层 API 一起搭建模型。
tf.contrib.data迁移到了tf.data,成为了TensorFlow的核心组成部件。在数据集框架中,每一个数据集代表一个数据的来源:数据可以是一个张量,一个TFRecord文件,一个文本文件,等等。由于训练数据通常无法全部写入内存中,从数据集中读取数据时通常需要使用一个迭代器按顺序进行读取,数据集也是计算图中的一个节点。
(1)读取TFRecord
dataset = tf.data.TFRecordDataset(filenames) # 这样的话就是读取两次数据,数据量就是两倍 dataset = tf.data.TFRecordDataset(["test.tfrecord","test.tfrecord"])
(2)解析feature信息。
是写入的逆过程,所以会需要写入时的信息:使用库pandas。
isbyte是用于记录该feature是否字符化了。default是所读的样本该feature值如果有确实,用什么进行填补,一般是使用np.NaNlength_type:是指示读取向量的方式是否是定长。
data_info = pd.DataFrame({'name':['scalar','vector','matrix','matrix_shape','tensor','tensor_shape'],
'type':[scalars[0].dtype,vectors[0].dtype,matrices[0].dtype,tf.int64, tensors[0].dtype,tf.int64],
'shape':[scalars[0].shape,(3,),matrices[0].shape,(len(matrices[0].shape),),tensors[0].shape,(len(tensors[0].shape),)],
'isbyte':[False,False,True,False,False,False],
'length_type':['fixed','fixed','var','fixed','fixed','fixed']},
columns=['name','type','shape','isbyte','length_type','default'])
(3)创建解析函数
example_proto,也就是序列化后的数据(也就是读取到的TFRecord数据)。
def parse_function(example_proto): # 只接受一个输入:example_proto,也就是序列化后的样本tf_serialized
解析方式有两种:
- 定长特征解析:
tf.FixedLenFeature(shape, dtype, default_value)shape:可当reshape来用,如vector的shape从(3,)改动成了(1,3)。
注:如果写入的feature使用了.tostring()其shape就是()dtype:必须是tf.float32,tf.int64,tf.string中的一种。default_value:feature值缺失时所指定的值。
- 不定长特征解析:
tf.VarLenFeature(dtype) - 注:可以不明确指定
shape,但得到的tensor是SparseTensor。
dics = {# 这里没用default_value,随后的都是None
'scalar': tf.FixedLenFeature(shape=(), dtype=tf.int64, default_value=None),
# vector的shape刻意从原本的(3,)指定成(1,3)
'vector': tf.FixedLenFeature(shape=(1,3), dtype=tf.float32),
# 使用 VarLenFeature来解析
'matrix': tf.VarLenFeature(dtype=dtype('float32')),
'matrix_shape': tf.FixedLenFeature(shape=(2,), dtype=tf.int64),
# tensor在写入时 使用了toString(),shape是()
# 但这里的type不是tensor的原type,而是字符化后所用的tf.string,随后再回转成原tf.uint8类型
'tensor': tf.FixedLenFeature(shape=(), dtype=tf.string),
'tensor_shape': tf.FixedLenFeature(shape=(3,), dtype=tf.int64)}
(4)进行解析
-
得到的
parsed_example也是一个字典,其中每个key是对应feature的名字,value是相应的feature解析值。如果使用了下面两种情况,则还需要对这些值进行转变。其他情况则不用。 -
string类型:tf.decode_raw(parsed_feature, type)来解码
注:这里type必须要和当初.tostring()化前的一致。如tensor转变前是tf.uint8,这里就需是tf.uint8;转变前是tf.float32,则tf.float32 -
VarLen解析:由于得到的是SparseTensor,所以视情况需要用tf.sparse_tensor_to_dense(SparseTensor)来转变成DenseTensor。
# 把序列化样本和解析字典送入函数里得到解析的样本 parsed_example = tf.parse_single_example(example_proto, dics) # 解码字符 parsed_example['tensor'] = tf.decode_raw(parsed_example['tensor'], tf.uint8) # 稀疏表示 转为 密集表示 parsed_example['matrix'] = tf.sparse_tensor_to_dense(parsed_example['matrix'])
(5)转变形状
# 转变matrix形状 parsed_example['matrix'] = tf.reshape(parsed_example['matrix'], parsed_example['matrix_shape']) # 转变tensor形状 parsed_example['tensor'] = tf.reshape(parsed_example['tensor'], parsed_example['tensor_shape'])
(6)执行解析函数
new_dataset = dataset.map(parse_function)
(7)创建迭代器
- 有了解析过的数据集后,接下来就是获取当中的样本。
make_one_shot_iterator():表示只将数据读取一次,然后就抛弃这个数据了
# 创建获取数据集中样本的迭代器 iterator = new_dataset.make_one_shot_iterator()
(8)获取样本
# 获得下一个样本 next_element = iterator.get_next() # 创建Session sess = tf.InteractiveSession() # 获取 i = 1 while True: # 不断的获得下一个样本 try: # 获得的值直接属于graph的一部分,所以不再需要用feed_dict来喂 scalar,vector,matrix,tensor = sess.run([next_element['scalar'], next_element['vector'], next_element['matrix'], next_element['tensor']]) # 如果遍历完了数据集,则返回错误 except tf.errors.OutOfRangeError: print("End of dataset") break else: # 显示每个样本中的所有feature的信息,只显示scalar的值 print('==============example %s ==============' %i) print('scalar: value: %s | shape: %s | type: %s' %(scalar, scalar.shape, scalar.dtype)) print('vector shape: %s | type: %s' %(vector.shape, vector.dtype)) print('matrix shape: %s | type: %s' %(matrix.shape, matrix.dtype)) print('tensor shape: %s | type: %s' %(tensor.shape, tensor.dtype)) i+=1 plt.imshow(tensor)
进行shuffle
buffer_size=10000:的含义是先创建一个大小为10000的buffer,然后对这个buffer进行打乱,如果buffersize过大的话虽然打乱效果很好,但是更加的占用内存,如果buffersize小的话打乱效果不好,一般可以设置为一个batch_size的10倍。shuffle_dataset = new_dataset.shuffle(buffer_size=10000) iterator = shuffle_dataset.make_one_shot_iterator() next_element = iterator.get_next()
设置batch
batch_dataset = shuffle_dataset.batch(4) iterator = batch_dataset.make_one_shot_iterator() next_element = iterator.get_next()
Batch_padding
- 可以在每个
batch内进行padding。 padded_shapes指定了内部数据是如何pad的。rank数要与元数据对应rank中的任何一维被设定成None或-1时都表示将pad到该batch下的最大长度。
batch_padding_dataset = new_dataset.padded_batch(4, padded_shapes={'scalar': [], 'vector': [-1,5], 'matrix': [None,None], 'matrix_shape': [None], 'tensor': [None,None,None], 'tensor_shape': [None]}) iterator = batch_padding_dataset.make_one_shot_iterator() next_element = iterator.get_next()
设置epoch
使用.repeat(num_epochs)来指定要遍历几遍整个数据集。
num_epochs = 2 epoch_dataset = new_dataset.repeat(num_epochs) iterator = epoch_dataset.make_one_shot_iterator() next_element = iterator.get_next()
https://www.cnblogs.com/hellcat/p/8146748.html#_label0_3
def csv_reader_dataset(filepaths, repeat=1, n_readers=5, n_read_threads=None, shuffle_buffer_size=10000, n_parse_threads=5, batch_size=32): dataset = tf.data.Dataset.list_files(filepaths).repeat(repeat) dataset = dataset.interleave( lambda filepath: tf.data.TextLineDataset(filepath).skip(1), cycle_length=n_readers, num_parallel_calls=n_read_threads) dataset = dataset.shuffle(shuffle_buffer_size) dataset = dataset.map(preprocess, num_parallel_calls=n_parse_threads) dataset = dataset.batch(batch_size) return dataset.prefetch(1)
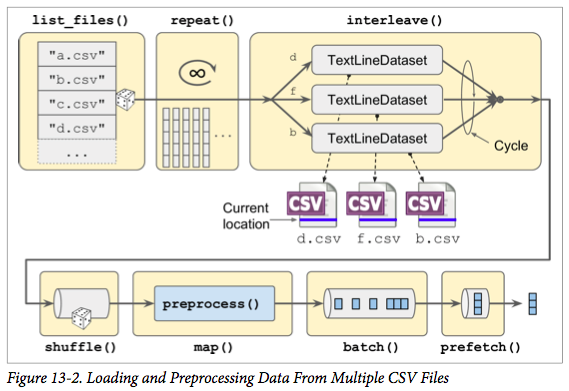
以下转载:https://blog.csdn.net/winycg/article/details/80588077
https://zhuanlan.zhihu.com/p/37106443
详解Tensorflow数据读取Dataset与Iterator
https://www.jianshu.com/p/e92a419e0181
二、Tensorflow读取数据方式
- 利用placeholder读取内存数据
- 利用queue读取硬盘中的数据
参考链接:https://zhuanlan.zhihu.com/p/27238630 - Dataset API同时支持从内存和硬盘的读取,相比之前的两种方法在语法上更加简洁易懂
三、Dataset
Google官方给出的Dataset API中的类图如下所示:
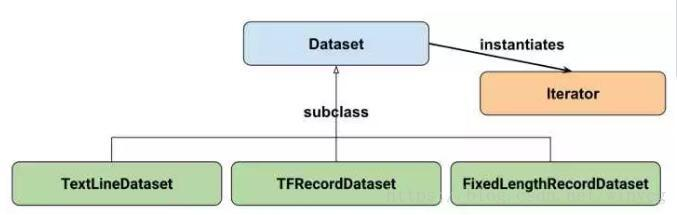
Dataset可以看作是相同类型元素的有序列表。在实际使用时,单个元素可以是向量,也可以是字符串、图片,元组tuple或者字典dict
1、DataSet 属性
Dataset的属性主要有三个:output_classes(返回单元的数据类,tf.Tensor或tf.SparseTensor),output_shapes(dataset数据单元的shape),output_types(dataset数据单元的数据类型)。
data_numpy=np.array([[1,2,3,4,5],[1,2,3,4,5]]) dataset=tf.data.Dataset.from_tensors(data_numpy) print(dataset.output_classes)#<class 'tensorflow.python.framework.ops.Tensor'> print(dataset.output_shapes)#(2, 5) print(dataset.output_types)#<dtype: 'int64'>
2、创建DataSet
(1)从内存中创建DataSet:
from_generator(从生成器读取)、from_sparse_tensor_slices(从sparsetensor切边读取)、from_tensor_slices(从tensor切片读取)、from_tensors(从tensor读取)、range(按要求生成区间范围内的数据)。
- 创建简单的DataSet
以单个元素为数字为例创建Dataset,创建的数据集包含1~5 5个元素
dataset = tf.data.Dataset.from_tensor_slices(np.array([1.0, 2.0, 3.0, 4.0, 5.0]))
- 创建较为复杂的Dataset
tf.data.Dataset.from_tensor_slices会切分传入Tensor的第0个维度,生成相应的dataset。
dataset = tf.data.Dataset.from_tensor_slices(np.random.uniform(size=(5, 2)))
传入的数值是一个矩阵,它的形状为(5, 2)。
[0.30689369 0.1312599 ] [0.41654633 0.6453099 ] [0.57331825 0.01766034] [0.73171401 0.97161158] [0.3017584 0.84737853]
tf.data.Dataset.from_tensor_slices就会切分它形状上的第0个维度,最后生成的dataset中一个含有5个元素,每个元素的形状是(2, ),即每个元素是矩阵的一行,相当于一个一维的array。
实际使用中,Dataset中的元素可能是元组或者字典。在图像识别问题中,一个元素可以是{“image”: image_tensor, “label”: label_tensor}形式的字典。
例如(字典):
dataset = tf.data.Dataset.from_tensor_slices(
{
"a": np.array([1.0, 2.0, 3.0, 4.0, 5.0]),
"b": np.random.uniform(size=(5, 2))
}
)
输出:
{'a': 1.0, 'b': array([0.26454147, 0.78977893])}
{'a': 2.0, 'b': array([0.19478178, 0.37884041])}
{'a': 3.0, 'b': array([0.45655924, 0.46979661])}
{'a': 4.0, 'b': array([0.08724776, 0.26343558])}
{'a': 5.0, 'b': array([0.63206763, 0.02796295])}
例如(元组):
dataset = tf.data.Dataset.from_tensor_slices(
(np.array([1.0, 2.0, 3.0, 4.0, 5.0]), np.random.uniform(size=(5, 2)))
)
输出:
(1.0, array([0.48643253, 0.69208099]))
(2.0, array([0.96668577, 0.39036077]))
(3.0, array([0.54854508, 0.54833064]))
(4.0, array([0.30970788, 0.29545166]))
(5.0, array([0.0290356 , 0.75689468]))
(2)从硬盘文件中创建数据
方式:对图像、文本文件等的读取、使用list_files获取目标文件的文件名数据集
(1)三种读取文件来创建DataSet的方式:
- tf.data.TextLineDataset():这个函数的输入是一个文件的列表,输出是一个dataset。dataset中的每一个元素就对应了文件中的一行。可以使用这个函数来读入CSV文件。
- tf.data.FixedLengthRecordDataset():这个函数的输入是一个文件的列表和一个record_bytes,之后dataset的每一个元素就是文件中固定字节数record_bytes的内容。通常用来读取以二进制形式保存的文件,如CIFAR10数据集就是这种形式。
- tf.data.TFRecordDataset():顾名思义,这个函数是用来读TFRecord文件的,dataset中的每一个元素就是一个TFExample。
(2)list_files获取目标文件的文件名:对于匹配所有文件格式的数据,可以利用tf.data.Dataset.list_files
files = tf.data.Dataset.list_files(file_path)
dataset = files.interleave(tf.data.TFRecordDataset)
3、Dataset数据处理
(1)单/多个元素进行转换transformation
一个Dataset通过Transformation变成一个新的Dataset。通常我们可以通过Transformation完成数据变换,打乱,组成batch,生成epoch等一系列操作
常用的Transformation有:
- map
- batch
- shuffle
- repeat
-
Dataset.filter()(对数据集的元素按照一定的条件逐一过滤,函数的返回值为bool值)
-
Dataset.flat_map()
-
Dataset.interleave()
-
Dataset.apply()(参数为转化函数,实现对单个或多个元素的处理)
-
Dataset.skip()(参数为整数,跳过n个元素,若n为-1跳过所有的元素)
flat_map、interleav虽然是对Dataset中的每一个元素进行处理,但其处理的的元素必须是dataset的实例,也就是要从dataset元素中生成新的dataset。
(a)map
map接收一个函数对象,Dataset中的每个元素都会被当作这个函数的输入,并将函数返回值作为新的Dataset,如我们可以对dataset中每个元素的值加1:
dataset = tf.data.Dataset.from_tensor_slices(np.array([1.0, 2.0, 3.0, 4.0, 5.0])) dataset = dataset.map(lambda x: x + 1) # 2.0, 3.0, 4.0, 5.0, 6.0
(b)batch
根据接收的整数值将该数个元素组合成batch,如下面的程序将dataset中的元素组成了大小为32的batch
dataset = dataset.batch(32)
(c)shuffle
打乱dataset中的元素,它有一个参数buffersize,表示打乱时使用的buffer的大小
dataset = dataset.shuffle(buffer_size=10000)
(d)repeat
整个序列重复多次,主要用来处理机器学习中的epoch,假设原先的数据是一个epoch,使用repeat(5)就可以将之变成5个epoch:
dataset = dataset.repeat(5)
(2)多个DataSet数据集处理
这里所说的对数据集进行处理是指Dataset这些方法的参数输入为数据集,其主要包括
- Dataset.concatenate():实现两个数据集的拼接
- Dataset.zip():实现对给定的数据集元素层面的数据集整合并生成新的数据集
- Dataset.prefetch():(参数为tf.int64)实现从数据集中取出一部分生成新的数据集。
(3)模型训练的相关数据设置
在深度学习的模型训练过程中,经常对数据进行随机打乱,并采用小批量数据进行每一步的训练,Dataset集成了这些功能,使用起来非常方便。
- Dataset.batch()(参数为tf.int64,代表小批量数据的数量,根据内存决定。若最后一个batch的N数量不够,则batch中的元素为N%batch)、、「
- Dataset.padded_batch()(同batch功能相同,但加入了数据补全功能,适用与文本数据的处理)
- Dataset.repeat()(参数为tf.int64,数据集元素重复的次数,若无参数,代表无限重复)
- Dataset.shared()(进行分布式计算)
- Dataset.shuffle()(参数)
4、访问Dataset:iterator

如果 Dataset 是一个水池的话,那么它其中的数据就好比是水池中的水,Iterator 你可以把它当成是一根水管。
在 Tensorflow 的程序代码中,正是通过 Iterator 这根水管,才可以源源不断地从 Dataset 中取出数据。
但为了应付多变的环境,水管也需要变化,Iterator 也有许多种类。
四种方式:
- 单次迭代:(创建迭代器)tf.data.Dataset.make_one_shot_iterator(), 调用 iterator 的
get_next()就可以轻松地取出数据了。[但这种方式不可以初始化] - 可初始化的迭代:make_initializable_iterator()
- 可重新初始化的迭代:
- 可馈送的迭代:
单次迭代:(一次性水管)
#实例化make_one_shot_iterator对象,该对象只能读取一次 iterator = dataset.make_one_shot_iterator() # 从iterator里取出一个元素 one_element = iterator.get_next() with tf.Session() as sess: for i in range(5): print(sess.run(one_element))
##结果
1.0 2.0 3.0 4.0 5.0
如果一个dataset中元素被读取完了,再执行sess.run(one_element)会报tf.errors.OutOfRangeError异常,这个行为与使用队列方式读取数据的行为是一致的。在实际程序中,可以在外界捕捉这个异常以判断数据是否读取完。可参考以下代码:
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
with tf.Session() as sess:
try:
while True:
print(sess.run(one_element))
except tf.errors.OutOfRangeError:
print("end!")
可初始化的迭代:(可定制的水管)
initializable iterator必须要在使用前通过sess.run()来初始化。使用initializable iterator,可以将placeholder代入Iterator中,这可以方便我们通过参数快速定义新的Iterator。
def initialable_test(): numbers = tf.placeholder(tf.int64,shape=[]) dataset = tf.data.Dataset.range(numbers) # iterator = dataset.make_one_shot_iterator() iterator = dataset.make_initializable_iterator() with tf.Session() as sess: sess.run(iterator.initializer,feed_dict={numbers:5}) while True: try: print(sess.run(iterator.get_next())) except tf.errors.OutOfRangeError: break sess.run(iterator.initializer,feed_dict={numbers:6}) while True: try: print(sess.run(iterator.get_next())) except tf.errors.OutOfRangeError: break
运行程序,结果就是打印了 01234,012345 相信大家可以很容易明白发生了什么。
跟单次 Iterator 的代码只有 2 处不同。
1、创建的方式不同,iterator.make_initialnizer()。
2、每次重新初始化的时候,都要调用sess.run(iterator.initializer)
你可以这样理解,Dataset 这个水池连续装了 2 次水,每次水量不一样,但可初始化的 Iterator 很好地处理了这件事情,但需要注意的是,这个时候 Iterator 还是面对同一个 Dataset。
一个简单的initializable iterator使用示例:
limit = tf.placeholder(dtype=tf.int32, shape=[])
dataset = tf.data.Dataset.from_tensor_slices(tf.range(start=0, limit=limit))
iterator = dataset.make_initializable_iterator()
next_element = iterator.get_next()
with tf.Session() as sess:
sess.run(iterator.initializer, feed_dict={limit: 10})
for i in range(10):
value = sess.run(next_element)
使用initializable iterator读入大规模数据时更为方便。在使用tf.data.Dataset.from_tensor_slices(array)时,实际上发生的事情是将array作为一个tf.constants保存到了计算图中。当array很大时,会导致计算图变得很大,给传输、保存带来不便。这时,我们可以用一个placeholder取代这里的array,并使用initializable iterator,只在需要时将array传进去,这样就可以避免把大数组保存在图里,示例代码为(来自官方例程):
with np.load("/var/data/training_data.npy") as data:
features = data["features"]
labels = data["labels"]
features_placeholder = tf.placeholder(features.dtype, features.shape)
labels_placeholder = tf.placeholder(labels.dtype, labels.shape)
dataset = tf.data.Dataset.from_tensor_slices((features_placeholder, labels_placeholder))
iterator = dataset.make_initializable_iterator()
sess.run(iterator.initializer, feed_dict={features_placeholder: features,
labels_placeholder: labels})
可重新初始化的迭代:(能连接不同水池的水管)
有时候,需要一个 Iterator 从不同的 Dataset 对象中读取数值。Tensorflow 针对这种情况,提供了一个可以重新初始化的 Iterator,它的用法相对而言,比较复杂,但好在不是很难理解。
def reinitialable_iterator_test(): training_data = tf.data.Dataset.range(10) validation_data = tf.data.Dataset.range(5) iterator = tf.data.Iterator.from_structure(training_data.output_types, training_data.output_shapes) train_op = iterator.make_initializer(training_data) validation_op = iterator.make_initializer(validation_data) next_element = iterator.get_next() with tf.Session() as sess: for _ in range(3): sess.run(train_op) for _ in range(3): print(sess.run(next_element)) print('===========') sess.run(validation_op) for _ in range(2): print(sess.run(next_element)) print('===========')
运行结果:
0 1 2 =========== 0 1 =========== 0 1 2 =========== 0 1 =========== 0 1 2 =========== 0 1 ===========
核心代码其实只有加粗的 3 行。
Iterator 可以接多个水池里面的水,但是要求这水池里面的水是同样的品质。
也就是,多个 Dataset 中它们的元素数据类型和形状应该是一致的。
通过 from_structure() 统一规格,后面的 2 句代码可以看成是 2 个水龙头,它们决定了放哪个水池当中的水。

不知道大家注意到一点没有?每次 Iterator 切换时,数据都从头开始打印了。如果,不想这种情况发生,就需要接下来介绍的另外一种 Iterator。
可馈送的 Iterator:(水管的转换器)
Tensorflow 最美妙的一个地方就是 feeding 机制,它决定了很多东西可以在程序运行时,动态填充,这其中也包括了 Iterator。
不同的 Dataset 用不同的 Iterator,然后利用 feeding 机制,动态决定,听起来就很棒,不是吗?
我们都知道,无论是在机器学习还是深度学习当中,训练集、验证集、测试集是大家绕不开的话题,但偏偏它们要分离开来,偏偏它们的数据类型又一致,所以,经常我们要写同样的重复的代码。
复用,是软件开发中一个重要的思想。
可馈送的 Iterator 一定程度上可以解决重复的代码,同时又将训练集和验证集的操作清晰得分离开来。
def feeding_iterator_test(): train_data = tf.data.Dataset.range(100).map( lambda x : x + tf.random_uniform([],0,10,tf.int64) ) val_data = tf.data.Dataset.range(5) handle = tf.placeholder(tf.string,shape=[]) iterator = tf.data.Iterator.from_string_handle( handle,train_data.output_types,train_data.output_shapes) next_element = iterator.get_next() train_op = train_data.make_one_shot_iterator() validation_op = val_data.make_initializable_iterator() with tf.Session() as sess: train_iterator_handle = sess.run(train_op.string_handle()) val_iterator_handle = sess.run(validation_op.string_handle()) for _ in range(3): for _ in range(2): print(sess.run(next_element,feed_dict={handle:train_iterator_handle})) print('======') sess.run(validation_op.initializer) for _ in range(5): print(sess.run(next_element,feed_dict={handle:val_iterator_handle})) print('======')
它是通过一个 string 类型的 handle 实现的。
需要注意的一点是,string_handle() 方法返回的是一个 Tensor,只有运行一个 Tensor 才会返回 string 类型的 handle。不然,程序会报错。
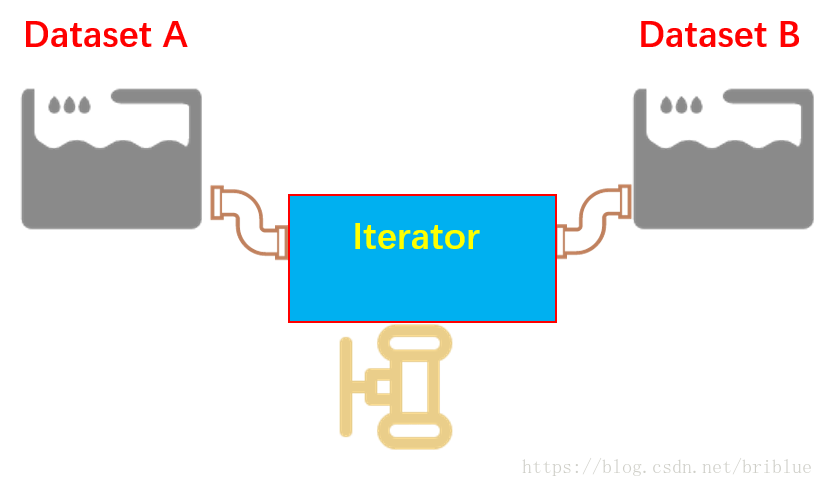
如果用图表的形式加深理解的话,那就是可馈送 Iterator 的方式,可以自主决定用哪个 Iterator,就好比不同的水池有不同的水管,不需要用同一根水管接到不同的水池当中去了。
可馈送的 Iterator 和可重新初始化的 Iterator 非常相似,但是,可馈送的 Iterator 在不同的 Iterator 切换的时候,可以做到不从头开始。
总结:
1、 单次 Iterator ,它最简单,但无法重用,无法处理数据集参数化的要求。
2、 可以初始化的 Iterator ,它可以满足 Dataset 重复加载数据,满足了参数化要求。
3、可重新初始化的 Iterator,它可以对接不同的 Dataset,也就是可以从不同的 Dataset 中读取数据。
4、可馈送的 Iterator,它可以通过 feeding 的方式,让程序在运行时候选择正确的 Iterator,它和可重新初始化的 Iterator 不同的地方就是它的数据在不同的 Iterator 切换时,可以做到不重头开始读取数据。
5、实例:读入磁盘图片和label创建Dataset
读入磁盘中的图片和图片相应的label,并将其打乱,组成batch_size=32的训练样本。在训练时重复10个epoch。
# 将filename对应的图片文件读入,并缩放到统一的大小
def _parse_function(filename, label):
# 读取图像文件内容编码为字符串
image_contents = tf.read_file(filename)
# 根据图像编码后的字符串解码为uint8的tensor
image_decoded = tf.image.decode_image(image_contents)
# 修改图像尺寸
image_resized = tf.image.resize_images(image_decoded, [28, 28])
return image_resized, label
# 图片文件的列表
filenames = tf.constant(["/var/data/image1.jpg", "/var/data/image2.jpg", ...])
# label[i]就是图片filenames[i]的label
labels = tf.constant([0, 37, ...])
# 此时dataset中的一个元素是(filename, label)
dataset = tf.data.Dataset.from_tensor_slices((filenames, labels))
# 此时dataset中的一个元素是(image_resized, label)
dataset = dataset.map(_parse_function)
# 此时dataset中的一个元素是(image_resized_batch, label_batch)
# dataset中的元素是(image_resized_batch, label_batch),image_resized_batch的形状为(32, 28, 28, 3),而label_batch的形状为(32, )
dataset = dataset.shuffle(buffersize=1000).batch(32).repeat(10)
四、相关函数解释
1、tf.data.Dataset.interleave()
interleave( map_func, cycle_length=AUTOTUNE, block_length=1, num_parallel_calls=None ):从dataset中同时抽取cycle_length个元素,通过map_func映射后,得到cycle_length个新dataset,再同时每个新dataset中一次取出block_length个元素可用来同时处理多个输入文件,增加更多的随机性,交错逐行读取数据
# Preprocess 4 files concurrently, and interleave blocks of 16 records from each file. filenames = ["/var/data/file1.txt", "/var/data/file2.txt", ...] dataset = (Dataset.from_tensor_slices(filenames) .interleave(lambda x: TextLineDataset(x).map(parse_fn, num_parallel_calls=1), cycle_length=4, block_length=16))
https://blog.csdn.net/menghuanshen/article/details/104240189
interleave()是Dataset的类方法,所以interleave是作用在一个Dataset上的。
(1)语法:返回一个dataset
-
- cycle_length:同时处理的输入元素数量,设置其为1,则一次处理一个输入元素。如果未指定,则将从可用的CPU内核数中得出该值。
- map_func:数据集对应的映射函数
- block_length:在循环到另一个输入元素之前,每个输入元素要生成的连续元素的数量。
num_parallel_calls:如果指定,实现将创建一个线程池,该线程池用于异步和并行地从循环元素中获取输入。
interleave( map_func, cycle_length=AUTOTUNE, block_length=1, num_parallel_calls=None )
- 假定我们现在有一个Dataset——A
- 从该A中取出cycle_length个element,然后对这些element apply map_func,得到cycle_length个新的Dataset对象。
- 然后从这些新生成的Dataset对象中取数据,取数逻辑为轮流从每个对象里面取数据,每次取block_length个数据
- 当这些新生成的某个Dataset的对象取尽时,从原Dataset中再取cycle_length个element,,然后apply
- map_func,以此类推。
举例:
a = tf.data.Dataset.range(1, 6) # ==> [ 1, 2, 3, 4, 5 ] # NOTE: New lines indicate "block" boundaries. b=a.interleave(lambda x: tf.data.Dataset.from_tensors(x).repeat(6), cycle_length=2, block_length=4)
# ==> [1,1,1,1,
# 2,2,2,2,
# 1,1,
# 2,2,
# 3,3,3,3,
# 4,4,4,4,
# 3,3
# 4,4
# 5,5,5,5,
# 5,5
for item in b: print(item.numpy(),end=', ')
##1, 1, 1, 1, 2, 2, 2, 2, 1, 1, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4, 3, 3, 4, 4, 5, 5, 5, 5, 5, 5,
示意图:其中map_func在这里是重复6次-repeat(6)。

(2)读取文件例子:
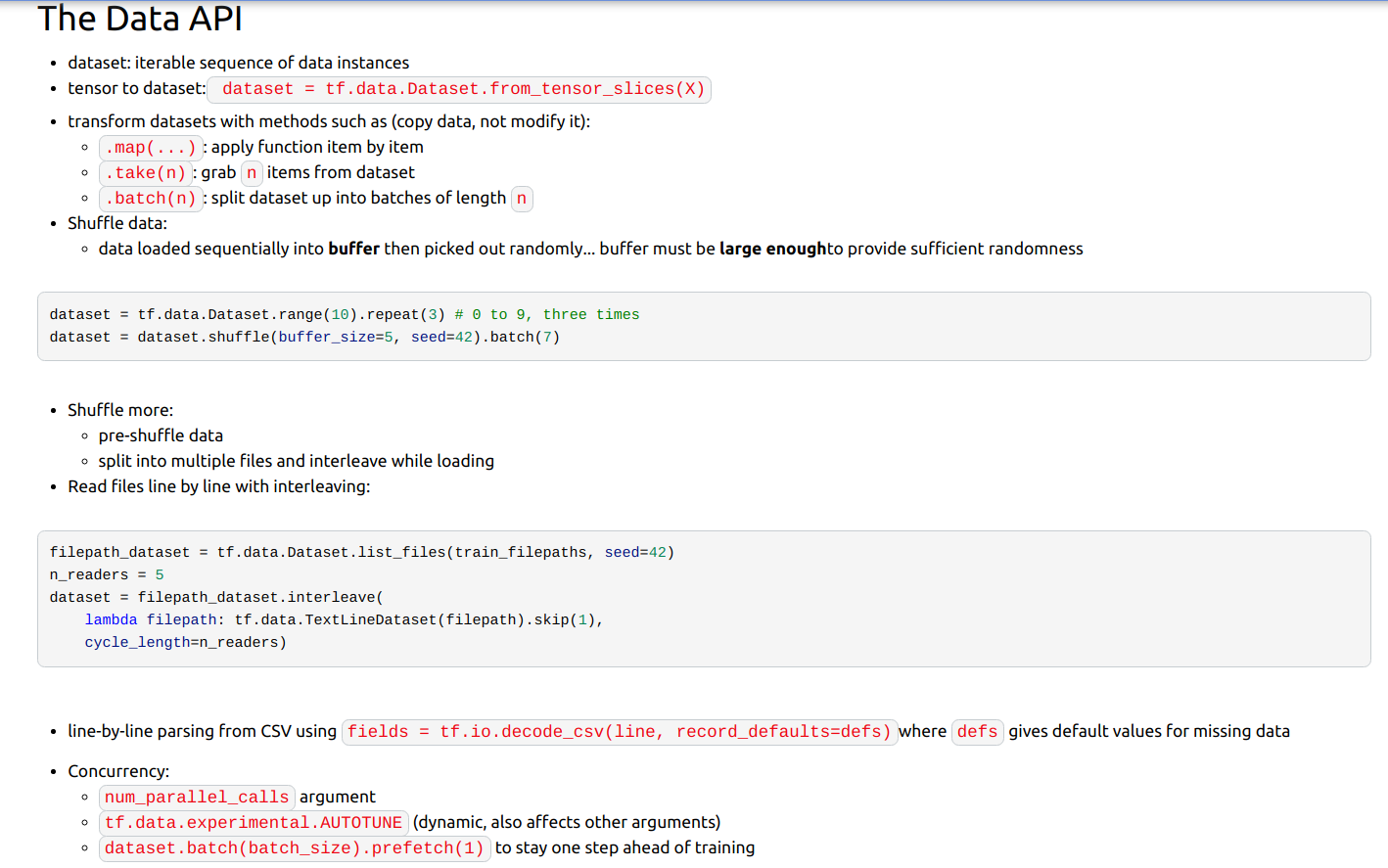

(如以下可以理解成有5个tfrecord文件,第一个有个样本---0到3,第二个有4个样本---4到7,……,第五个只有16和17。
interleave参数中cycle_length=2相当于同时获取tfrecord文件的数量为2个,block_length为从同一个tfrecord中连续获取的样本数量,可设为batch_size。)
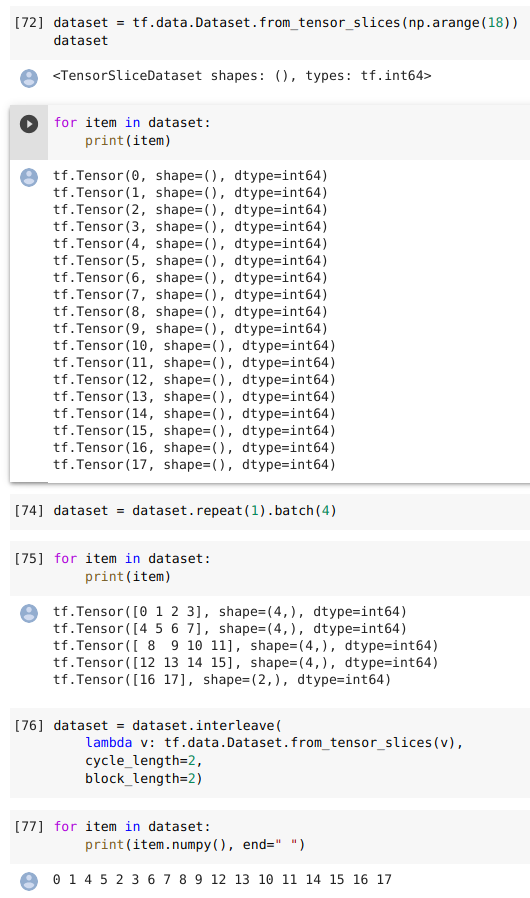
https://www.pythonheidong.com/blog/article/364273/
2、list_files
""" 压缩后:b'
d
5
x0efavorite_booksx12#
!
x10machine laerning
deep learning
x0c
x03agex12x05x1ax03
x01x18
x1d
x05hoursx12x14x12x12
x10x00x00hAx00x00xa0Ax00x00x08Bx9ax99xf9A'"""
(2)生成tfrecord文件
#生成tfrecord文件
output_dir = os.path.join("tfrecord_basic")
if not os.path.exists(output_dir):
os.mkdir(output_dir)
filename = "test.tfrecords"
filename_full_path = os.path.join(output_dir,filename)
with tf.io.TFRecordWriter(filename_full_path) as wr:
for i in range(3):
wr.write(serialized_example)
(3)解析读取出来的文件
#1.定义features类型
expected_features = {
"favorite_books":tf.io.VarLenFeature(dtype=tf.string),
"hours":tf.io.VarLenFeature(dtype=tf.float32),
"age":tf.io.FixedLenFeature([],dtype=tf.int64),
}
#2.读取文件
dataset = tf.data.TFRecordDataset([filename_full_path])
for serialized_example_tensor in dataset:
example = tf.io.parse_single_example(serialized_example_tensor,
expected_features)
# print(example)#此时得到的是SparseTensor,还需要进一步解析
books = tf.sparse.to_dense(example["favorite_books"])
for book in books:
print(book.numpy().decode("UTF-8"))
"""
machine laerning
deep learning
machine laerning
deep learning
machine laerning
deep learning
"""
(4) 存储为zip格式并读取
#将tfrecord存储为压缩文件
filename_full_path_zip = filename_full_path + '.zip'
opt = tf.io.TFRecordOptions(compression_type = "GZIP")
with tf.io.TFRecordWriter(filename_full_path_zip,opt) as wr:
for i in range(3):
wr.write(serialized_example)
#读取压缩的tfrecord文件
expected_features = {
"favorite_books":tf.io.VarLenFeature(dtype=tf.string),
"hours":tf.io.VarLenFeature(dtype=tf.float32),
"age":tf.io.FixedLenFeature([],dtype=tf.int64),
}
dataset_zip = tf.data.TFRecordDataset([filename_full_path_zip],compression_type = "GZIP")#添加compression_type即可
for serialized_example_tensor in dataset_zip:
example = tf.io.parse_single_example(serialized_example_tensor,
expected_features)
books = tf.sparse.to_dense(example["favorite_books"])
for book in books:
print(book.numpy().decode("UTF-8"))
3.2 tfrecord应用
(1)通过dataset读取csv文件生成dataset
#获取文件名列表
source_dir = os.path.join("./generate_csv/")
def get_filenames_by_prefix(source_dir,prefix_name):
all_files = os.listdir(source_dir)
results = []
for filename in all_files:
if filename.startswith(prefix_name):
results.append(os.path.join(source_dir,filename))
return results
train_filenames = get_filenames_by_prefix(source_dir,"train")
valid_filenames = get_filenames_by_prefix(source_dir,"valid")
test_filenames = get_filenames_by_prefix(source_dir,"test")
#读取csv文件内容,并生成dataset
def parse_csv_line(line,n_fields=9):
defs = [tf.constant(np.nan)] * n_fields
parsed_fields = tf.io.decode_csv(line,record_defaults=defs)
x = tf.stack(parsed_fields[0:-1])
y = tf.stack(parsed_fields[-1:])
return x, y
def csv_reader_dataset(filenames,n_readers=5,batch_size=32,
n_parse_threads=5,shuffle_buffer_size=10000):
dataset = tf.data.Dataset.list_files(filenames)
dataset = dataset.repeat()
dataset = dataset.interleave(
lambda filename:tf.data.TextLineDataset(filename).skip(1),
cycle_length=n_readers)
dataset.shuffle(shuffle_buffer_size)
dataset = dataset.map(parse_csv_line,num_parallel_calls=n_parse_threads)
dataset = dataset.batch(batch_size)
return dataset
batch_size = 32
train_set = csv_reader_dataset(train_filenames,batch_size = batch_size)
valid_set = csv_reader_dataset(valid_filenames,batch_size = batch_size)
test_set = csv_reader_dataset(test_filenames,batch_size = batch_size)
(2)将dataset转化为tfrecord
#定义将样本转化为序列化example的函数
def serialize_example(x,y):
input_feature = tf.train.FloatList(value = x)
label_feature = tf.train.FloatList(value = y)
feats = tf.train.Features(
feature = {
"input_feature":tf.train.Feature(float_list = input_feature),
"label_feature":tf.train.Feature(float_list = label_feature)
}
)
example = tf.train.Example(features = feats)
return example.SerializeToString()
#定义将csv格式的dataset转化为tfrecord文件的函数
def csv_dataset_to_tfrecord(base_filename,dataset,n_shards,
steps_per_shard,compression_type = None):
opt = tf.io.TFRecordOptions(compression_type = compression_type)
all_filenames = []
for shard_id in range(n_shards):
filename_fullpath = os.path.join('{}_{:05d}_of_{:05d}'.format(
base_filename,shard_id,n_shards))
with tf.io.TFRecordWriter(filename_fullpath,opt) as wr:
for x_batch,y_batch in dataset.take(steps_per_shard):
for x_example,y_example in zip(x_batch,y_batch):
wr.write(serialize_example(x_example,y_example))
all_filenames.append(filename_fullpath)
return all_filenames
n_shards = 20
train_steps_per_shard = 11610 // batch_size // n_shards
valid_steps_per_shard = 3870 // batch_size // n_shards
test_steps_per_shard = 5170 // batch_size //n_shards
output_dir = os.path.join("generate_tfrecords")
if not os.path.exists(output_dir):
os.mkdir(output_dir)
train_basename = os.path.join(output_dir,"train")
valid_basename = os.path.join(output_dir,"valid")
test_basename = os.path.join(output_dir,"test")
train_tfrecord_filenames = csv_dataset_to_tfrecord(
train_basename,train_set,n_shards,train_steps_per_shard,None)
valid_tfrecord_filenames = csv_dataset_to_tfrecord(
valid_basename,valid_set,n_shards,valid_steps_per_shard,None)
test_tfrecord_filenames = csv_dataset_to_tfrecord(
test_basename,test_set,n_shards,test_steps_per_shard,None)
(3)生成压缩格式tfrecord
output_dir = os.path.join("generate_tfrecords_zip")
if not os.path.exists(output_dir):
os.mkdir(output_dir)
train_basename = os.path.join(output_dir,"train")
valid_basename = os.path.join(output_dir,"valid")
test_basename = os.path.join(output_dir,"test")
train_tfrecord_filenames = csv_dataset_to_tfrecord(
train_basename,train_set,n_shards,train_steps_per_shard,compression_type="GZIP")
valid_tfrecord_filenames = csv_dataset_to_tfrecord(
valid_basename,valid_set,n_shards,valid_steps_per_shard,compression_type="GZIP")
test_tfrecord_filenames = csv_dataset_to_tfrecord(
test_basename,test_set,n_shards,test_steps_per_shard,compression_type="GZIP")
#定义解析example特征字典
excepted_features = {
"input_feature":tf.io.FixedLenFeature([8],dtype=tf.float32),
"label_feature":tf.io.FixedLenFeature([1],dtype=tf.float32)
}
def parde_example(serialized_example):
example = tf.io.parse_single_example(serialized_example,excepted_features)
return example["input_feature"],example["label_feature"]
def tfrecord_reader_dataset(filenames,n_readers = 5,
batch_size = 32, n_parse_threads = 5,
shuffle_buffer_size = 10000):
dataset = tf.data.Dataset.list_files(filenames)
dataset = dataset.repeat()
dataset = dataset.interleave(
lambda filename:tf.data.TFRecordDataset(filename,compression_type = "GZIP"),
cycle_length= n_readers)
dataset.shuffle(shuffle_buffer_size)
dataset = dataset.map(parde_example,num_parallel_calls = n_parse_threads)
dataset = dataset.batch(batch_size)
return dataset
batch_size = 32
tfrecord_train_set = tfrecord_reader_dataset(train_tfrecord_filenames,batch_size = batch_size)
tfrecord_valid_set = tfrecord_reader_dataset(valid_tfrecord_filenames,batch_size = batch_size)
tfrecord_test_set = tfrecord_reader_dataset(test_tfrecord_filenames,batch_size = batch_size)
model = keras.models.Sequential([
keras.layers.Dense(30,input_shape = [8],activation = 'relu'),
keras.layers.Dense(1)])
opt = keras.optimizers.SGD(1e-3)
model.compile(loss = "mean_squared_error",
optimizer = opt)
callbacks = [keras.callbacks.EarlyStopping(patience=5,min_delta=1e-2)]
his = model.fit(tfrecord_train_set,epochs=100,
validation_data=tfrecord_valid_set,
steps_per_epoch = 11610 // batch_size,#由于每次只读取batch_size个数据,所以这个是每个epoch的步数,才能将所有数据遍历
validation_steps = 3870 //batch_size,
callbacks = callbacks)

推荐阅读更多精彩内容
-
tf.data API 能够让你创建简单的,可复用的,输入流程。例如,在一个分布式文件系统下,一个图片模型可能要聚...
-

-
转自: https://www.cnblogs.com/andre-ma/p/8458172.html 【写在前面...

-
姓名:白国乐 学号:17021210898 专业:信号与信息处理 转载自:http://blog.csdn.net...
-
tf.data可以创建复杂的数据输入流水线,实现图像、文字的导入。tf.data产生两个新的抽象类: tf.dat...






作者:七月七叶
链接:https://www.jianshu.com/p/e92a419e0181
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。