Mirza M, Osindero S. Conditional Generative Adversarial Nets.[J]. arXiv: Learning, 2014.
@article{mirza2014conditional,
title={Conditional Generative Adversarial Nets.},
author={Mirza, Mehdi and Osindero, Simon},
journal={arXiv: Learning},
year={2014}}
引
GAN (Generative Adversarial Nets) 能够通过隐变量(z)来生成一些数据, 但是我们没有办法去控制, 因为隐变量(z)是完全随机的. 这篇文章便很自然地提出了条件GAN,增加一个输入(y)(比如类别标签)去控制输出. 比如在MNIST数据集上, 我们随机采样一个(z), 并给定
[y=[0, 0, 1, 0, 0, 0, 0, 0, 0, 0],
]
结果应当是数字2.
主要内容
文章的优化函数如下:
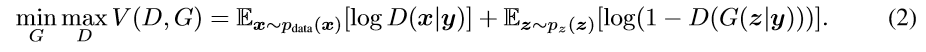
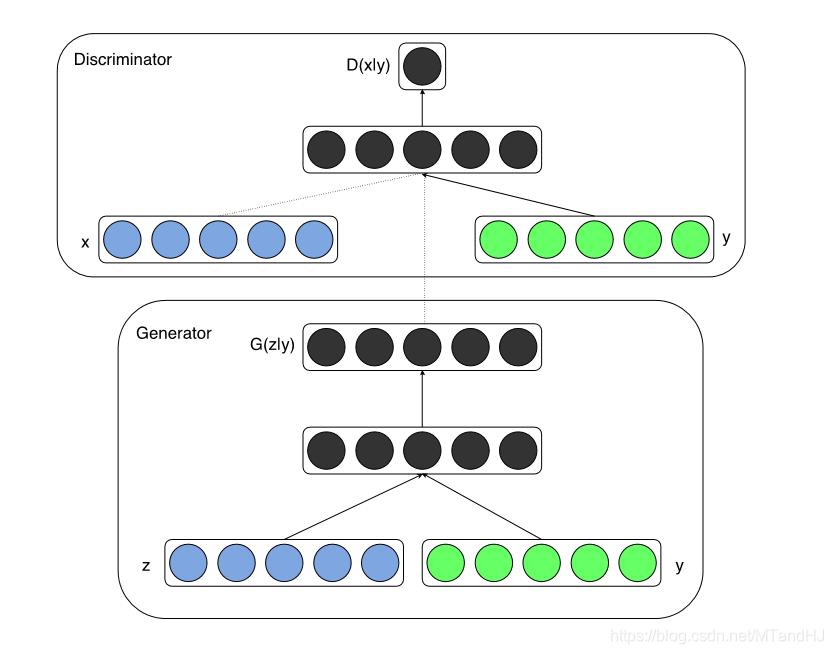
网络"结构"如下:


代码
"""
这个几乎就是照搬别人的代码
lr=0.0001,
epochs=50
但是10轮就差不多收敛了
"""
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import os
import matplotlib.pyplot as plt
class Generator(nn.Module):
"""
生成器
"""
def __init__(self, input_size=(100, 10), output_size=784):
super().__init__()
self.fc1 = nn.Sequential(
nn.Linear(input_size[0], 256),
nn.BatchNorm1d(256),
nn.ReLU()
)
self.fc2 = nn.Sequential(
nn.Linear(input_size[1], 256),
nn.BatchNorm1d(256),
nn.ReLU()
)
self.dense = nn.Sequential(
nn.Linear(512, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Linear(512, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Linear(1024, output_size),
nn.Tanh()
)
def forward(self, z, y):
"""
:param z: 随机隐变量
:param y: 条件隐变量
:return:
"""
z = self.fc1(z)
y = self.fc2(y)
out = self.dense(
torch.cat((z, y), 1)
)
return out
class Discriminator(nn.Module):
def __init__(self, input_size=(784, 10)):
super().__init__()
self.fc1 = nn.Sequential(
nn.Linear(input_size[0], 1024),
nn.LeakyReLU(0.2)
)
self.fc2 = nn.Sequential(
nn.Linear(input_size[1], 1024),
nn.LeakyReLU(0.2)
)
self.dense = nn.Sequential(
nn.Linear(2048, 512),
nn.BatchNorm1d(512),
nn.LeakyReLU(0.2),
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x, y):
x = self.fc1(x)
y = self.fc2(y)
out = self.dense(
torch.cat((x, y), 1)
)
return out
class Train:
def __init__(self, z_size=100, y_size=10, x_size=784,
criterion=nn.BCELoss(), lr=1e-4):
self.generator = Generator(input_size=(z_size, y_size), output_size=x_size)
self.discriminator = Discriminator(input_size=(x_size, y_size))
self.criterion = criterion
self.opti1 = torch.optim.Adam(self.generator.parameters(), lr=lr, betas=(0.5, 0.999))
self.opti2 = torch.optim.Adam(self.discriminator.parameters(), lr=lr, betas=(0.5, 0.999))
self.z_size = z_size
self.y_size = y_size
self.x_size = x_size
self.lr = lr
cpath = os.path.abspath('.')
self.gen_path = os.path.join(cpath, 'generator3.pt')
self.dis_path = os.path.join(cpath, 'discriminator3.pt')
self.imgspath = lambda i: os.path.join(cpath, 'image3', 'fig{0}'.format(i))
#self.loading()
def transform_y(self, labels):
return torch.eye(self.y_size)[labels]
def sampling_z(self, size):
return torch.randn(size)
def showimgs(self, imgs, order):
n = imgs.size(0)
imgs = imgs.data.view(n, 28, 28)
fig, axs = plt.subplots(10, 10)
for i in range(10):
for j in range(10):
axs[i, j].get_xaxis().set_visible(False)
axs[i, j].get_yaxis().set_visible(False)
for i in range(10):
for j in range(10):
t = i * 10 + j
img = imgs[t]
axs[i, j].cla()
axs[i, j].imshow(img.data.view(28, 28).numpy(), cmap='gray')
fig.savefig(self.imgspath(order))
for i in range(10):
for j in range(10):
t = i * 10 + j
img = imgs[t]
axs[i, j].cla()
axs[i, j].imshow(img.data.view(28, 28).numpy() / 2 + 0.5, cmap='gray')
fig.savefig(self.imgspath(order+1))
#plt.show()
#plt.cla()
def train(self, trainloader, epochs=50, classes=10):
order = 2
for epoch in range(epochs):
running_loss_d = 0.
running_loss_g = 0.
if (epoch + 1) % 5 is 0.:
self.opti1.param_groups[0]['lr'] /= 10
self.opti2.param_groups[0]['lr'] /= 10
print("learning rate change!")
if (epoch + 1) % order is 0.:
self.showimgs(fake_imgs, order=order)
self.showimgs(real_imgs, order=order+2)
order += 4
for i, data in enumerate(trainloader):
real_imgs, labels = data
real_imgs = real_imgs.view(real_imgs.size(0), -1)
y = self.transform_y(labels)
d_out = self.discriminator(real_imgs, y).squeeze()
z = self.sampling_z((y.size(0), self.z_size))
fake_y = self.transform_y(torch.randint(classes, size=(y.size(0),)))
fake_imgs = self.generator(z, fake_y).squeeze()
g_out = self.discriminator(fake_imgs, fake_y).squeeze()
# 训练判别器
loss1 = self.criterion(d_out, torch.ones_like(d_out))
loss2 = self.criterion(g_out, torch.zeros_like(g_out))
d_loss = loss1 + loss2
self.opti2.zero_grad()
d_loss.backward()
self.opti2.step()
# 训练生成器
z = self.sampling_z((y.size(0), self.z_size))
fake_y = self.transform_y(torch.randint(classes, size=(y.size(0),)))
fake_imgs = self.generator(z, fake_y).squeeze()
g_out = self.discriminator(fake_imgs, fake_y).squeeze()
g_loss = self.criterion(g_out, torch.ones_like(g_out))
self.opti1.zero_grad()
g_loss.backward()
self.opti1.step()
running_loss_d += d_loss
running_loss_g += g_loss
if i % 10 is 0 and i != 0:
print("[epoch {0:<d}: d_loss: {1:<5f} g_loss: {2:<5f}]".format(
epoch, running_loss_d / 10, running_loss_g / 10
))
running_loss_d = 0.
running_loss_g = 0.
torch.save(self.generator.state_dict(), self.gen_path)
torch.save(self.discriminator.state_dict(), self.dis_path)
def loading(self):
self.generator.load_state_dict(torch.load(self.gen_path))
self.generator.eval()
self.discriminator.load_state_dict(torch.load(self.dis_path))
self.discriminator.eval()
结果

此时判别器对这些图片进行判别, 但部分都是0.5以下, 也就是说这些基本上都被认为是伪造的图片.
"""
lr=0.001,
SGD,
网络结构简化了
"""
class Generator(nn.Module):
"""
生成器
"""
def __init__(self, input_size=(100, 10), output_size=784):
super().__init__()
self.fc1 = nn.Sequential(
nn.Linear(input_size[0], 128),
nn.BatchNorm1d(128),
nn.ReLU()
)
self.fc2 = nn.Sequential(
nn.Linear(input_size[1], 128),
nn.BatchNorm1d(128),
nn.ReLU()
)
self.dense = nn.Sequential(
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Linear(512, output_size),
nn.BatchNorm1d(output_size),
nn.Tanh()
)
def forward(self, z, y):
"""
:param z: 随机隐变量
:param y: 条件隐变量
:return:
"""
z = self.fc1(z)
y = self.fc2(y)
out = self.dense(
torch.cat((z, y), 1)
)
return out
class Discriminator(nn.Module):
def __init__(self, input_size=(784, 10)):
super().__init__()
self.fc1 = nn.Sequential(
nn.Linear(input_size[0], 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2)
)
self.fc2 = nn.Sequential(
nn.Linear(input_size[1], 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2)
)
self.dense = nn.Sequential(
nn.Linear(2048, 512),
nn.BatchNorm1d(512),
nn.LeakyReLU(0.2),
nn.Linear(512, 1),
nn.Sigmoid()
)
def forward(self, x, y):
x = self.fc1(x)
y = self.fc2(y)
out = self.dense(
torch.cat((x, y), 1)
)
return out
class Train:
def __init__(self, z_size=100, y_size=10, x_size=784,
criterion=nn.BCELoss(), lr=1e-3, momentum=0.9):
self.generator = Generator(input_size=(z_size, y_size), output_size=x_size)
self.discriminator = Discriminator(input_size=(x_size, y_size))
self.criterion = criterion
self.opti1 = torch.optim.SGD(self.generator.parameters(), lr=lr, momentum=momentum)
self.opti2 = torch.optim.SGD(self.discriminator.parameters(), lr=lr, momentum=momentum)
self.z_size = z_size
self.y_size = y_size
self.x_size = x_size
self.lr = lr
cpath = os.path.abspath('.')
self.gen_path = os.path.join(cpath, 'generator2.pt')
self.dis_path = os.path.join(cpath, 'discriminator2.pt')
self.imgspath = lambda i: os.path.join(cpath, 'image', 'fig{0}'.format(i))
#self.loading()
def transform_y(self, labels):
return torch.eye(self.y_size)[labels]
def sampling_z(self, size):
return torch.randn(size)
def showimgs(self, imgs, order):
n = imgs.size(0)
imgs = imgs.data.view(n, 28, 28)
fig, axs = plt.subplots(10, 10)
for i in range(10):
for j in range(10):
axs[i, j].get_xaxis().set_visible(False)
axs[i, j].get_yaxis().set_visible(False)
for i in range(10):
for j in range(10):
t = i * 10 + j
img = imgs[t]
axs[i, j].cla()
axs[i, j].imshow(img.data.view(28, 28).numpy(), cmap='gray')
fig.savefig(self.imgspath(order))
def train(self, trainloader, epochs=5, classes=10):
order = 0
for epoch in range(epochs):
running_loss_d = 0.
running_loss_g = 0.
if (epoch + 1) % 5 is 0.:
self.opti1.param_groups[0]['lr'] /= 10
self.opti2.param_groups[0]['lr'] /= 10
print("learning rate change!")
for i, data in enumerate(trainloader):
real_imgs, labels = data
real_imgs = real_imgs.view(real_imgs.size(0), -1)
y = self.transform_y(labels)
d_out = self.discriminator(real_imgs, y).squeeze()
z = self.sampling_z((y.size(0), self.z_size))
fake_y = self.transform_y(torch.randint(classes, size=(y.size(0),)))
fake_imgs = self.generator(z, fake_y).squeeze()
g_out = self.discriminator(fake_imgs.detach(), fake_y).squeeze()
# 训练判别器
loss1 = self.criterion(d_out, torch.ones_like(d_out))
loss2 = self.criterion(g_out, torch.zeros_like(g_out))
d_loss = loss1 + loss2
self.opti2.zero_grad()
d_loss.backward()
self.opti2.step()
# 训练生成器
z = self.sampling_z((y.size(0), self.z_size))
fake_y = self.transform_y(torch.randint(classes, size=(y.size(0),)))
fake_imgs = self.generator(z, fake_y).squeeze()
g_out = self.discriminator(fake_imgs, fake_y).squeeze()
g_loss = self.criterion(g_out, torch.ones_like(g_out))
self.opti1.zero_grad()
g_loss.backward()
self.opti1.step()
running_loss_d += d_loss
running_loss_g += g_loss
if i % 10 is 0 and i != 0:
print("[epoch {0:<d}: d_loss: {1:<5f} g_loss: {2:<5f}]".format(
epoch, running_loss_d / 10, running_loss_g / 10
))
running_loss_d = 0.
running_loss_g = 0.
if (epoch + 1) % 2 is 0:
self.showimgs(fake_imgs, order=order)
order += 1
torch.save(self.generator.state_dict(), self.gen_path)
torch.save(self.discriminator.state_dict(), self.dis_path)
def loading(self):
self.generator.load_state_dict(torch.load(self.gen_path))
self.generator.eval()
self.discriminator.load_state_dict(torch.load(self.dis_path))
self.discriminator.eval()
结果, 不是特别好

SGD改成Adam之后的结果(50个epochs都训练完了, 结果居然有点好).
