WebSpider
网络爬虫:.网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。请求网站并提取数据的自动化程序,可以理解为在网络上爬来爬去的一只蜘蛛,互联网可以比喻成一张大网,爬虫在这张大网爬,遇到一些自己感兴趣的网站资源,就可以模拟浏览器把它抓取下来,之后存入到CSV 数据库等
请求网站:就是要用程序实现这个过程,就需要写代码来实现模拟浏览器向服务器发送一个请求,来获取这些网络资源,获取到的是一串html代码,然后我们从里面提取数据存入数据库完成数据采集的过程!.
自动化:我们写完程序之后就让他一直运行,他可以代替浏览器向服务器发送请求, 不停的循环运行就可以批量的、大量的获取一些数据,这些就是网络爬虫运行的基本流程.
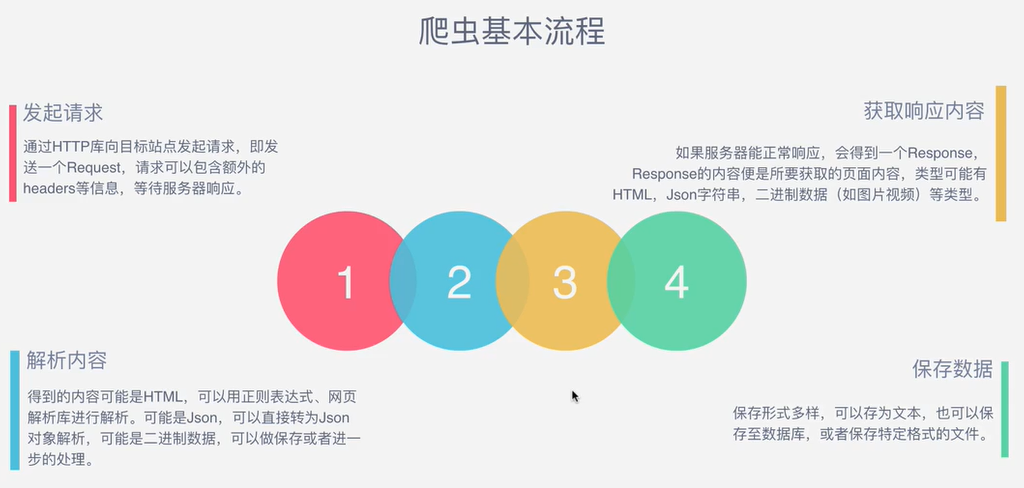
发起请求:通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器响应.
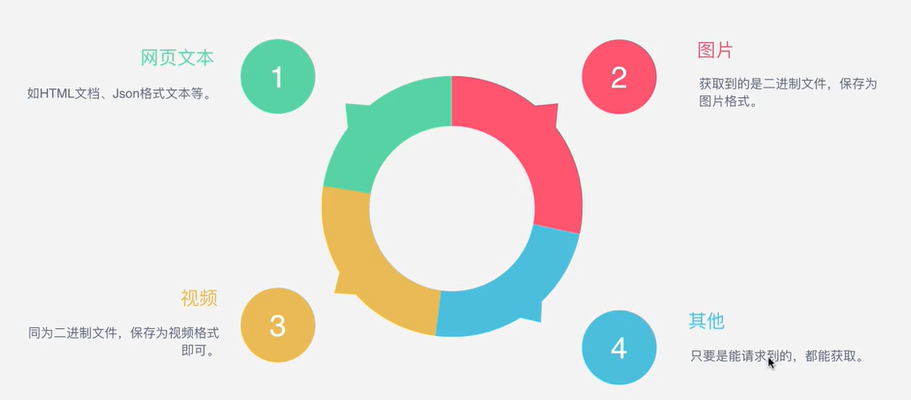
获取响应内容:如果服务器能正常响应,会得到一个Response,Response的内容便是所要获取的页面内容,内容可以有HTML,json字符串,二进制数据(如图片视频)等类型.
解析内容:得到的内容可能是HTML,可以用正则表达式、网页解析库进行解析.可能是json,可以直接转为json对象解析,可能是二进制数据,可以做保存或者进一步的处理.
保存数据:保存形式多样,可以存为文本,也可以保存至数据库,或者保存特定格式的文件.
Request与Response的区别:
①浏览器就发送消息给该网址所在服务器,这个过程叫HTTP Request.
②服务器收到浏览器发送的消息后,能够根据浏览器发送消息的内容,做相应处理,然后把消息回传给浏览器.
③浏览器收到服务器响应的Response信息后,会对信息进行相应处理,然后展示.

Request包含:
①请求方式:主要有GET、POST两种类型,另外还有HEAD、PUT、DELETE、OPTIONS等.POST请求需要构造一个表单提交才可以构造一个POST请求.
②请求URL:URL全称统一资源定位符,如一个网页文档,一张图片,一个视频等都可以用URL唯一来确定.
③请求头:包含一些浏览器重要的配置信息,请求时的头部信息,如User-Agent、Host、Cookies等信息,用来保证我们的程序是可以正常运行的.User-Agent用来指定浏览器请求头,有头之后服务器识别浏览器返回响应,如果不携带请求头服务器可能会认为你是一个非法的请求,不会给你返回页面.
④请求体:请求时额外携带的数据,如表单提交时的表单数据.在GET方式请求的时候请求体是不会携带任何内容的,POST请求Form Data会把表单提交时的一些参数通过配置传给服务器,比如做登录窗口、文件上传的时候这些配置都会被附加到请求体.

Response包含:
①响应状态:有多种响应状态,如200代表成功,301代表跳转,404表示找不到页面,502服务器错误.
HTTP状态码分类
HTTP状态码(status code)由三个十进制数字组成,第一个十进制数字定义了状态码的类型,后两个数字没有分类的作用。HTTP状态码共分为5种类型:
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
| 状态码 | 状态码英文名称 | 中文描述 |
|---|---|---|
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议 |
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 201 | Created | 已创建。成功请求并创建了新的资源 |
| 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
| 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本 |
| 204 | No Content | 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 205 | Reset Content | 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
| 206 | Partial Content | 部分内容。服务器成功处理了部分GET请求 |
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy | 使用代理。所请求的资源必须通过代理访问 |
| 306 | Unused | 已经被废弃的HTTP状态码 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required | 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的PUT请求是可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed | 服务器无法满足Expect的请求头信息 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 充当网关或代理的服务器,从远端服务器接收到了一个无效的请求 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
②响应头:如内容类型,内容长度,服务器信息,设置cookie等等.
③响应体:最主要的部分,包含了请求资源的内容,如网页HTML,图片等二进制数据等.

理论上,只要能看的到的数据,都可以抓取.
解析方式
1.直接解析:用来处理一些简单直接的网页.
2.json解析:有的网站数据是用ajax加载的,通常返回的是一些json格式的字符串,我们需要把json字符串解析 转换成json对象,然后提取我们需要的数据
3.正则表达式:就是一个规则字符串,把HTML代码里面相应的文本提取出来
4.Beautifulsoup:解析库
5.PyQuery:解析库
6.xpath:解析库

如何解决JavaScript渲染问题
1.分析ajax请求返回json格式的字符串,方便我们提取数据
2.Selenuim/WebDriver驱动一个浏览器来模拟加载网页
3.splash
4.PyV8.Ghost.py 等
如何保存数据
1.纯文本json,xml等
2.关系型数据库 MySQL Oracle SQL server等具有结构化表结构形式存储
3.非关系型数据库 MongoDB Redis等key-value形式存储
4.二进制文件,如图片视频音频等直接保存成特定格式即可.