一、安装配置
在官网下载Es,注意版本号,不同大版本号之间差异很大。我安装的是7.14.0版本
1.1 安装成服务
cmd 进入bin目录下执行
elasticsearch-service.bat install
1.2 安装插件
ik分词器,分词器的版本和ES版本需要一致
elasticsearch-plugin.bat install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.14.0/elasticsearch-analysis-ik-7.14.0.zip
1.3 配置账号密码
修改config目录下面的elasticsearch.yml文件,在里面添加如下内容,并重启。
xpack.security.enabled: true xpack.license.self_generated.type: basic xpack.security.transport.ssl.enabled: true
执行:
elasticsearch-setup-passwords interactive
然后配置每个账户密码。
通过账号密码链接: http://username:password@127.0.0.1:9200
二、基础概念
2.1 文档元数据
|
节点 |
说明 |
|
_index |
文档存储的地方,必须小写,不能以下划线开头,不能包含逗号 |
|
_type |
文档代表的对象的类,命名可以是大写或者小写,但是不能以下划线或者句号开头,不应该包含逗号 |
|
_id |
文档的唯一标识 |
2.2 索引
一个 索引 类似于传统关系数据库中的一个 数据库 ,是一个存储关系型文档的地方。事实上,我们的数据被存储在分片(shards)中,索引只是一个把一个或多个分片分组在一起的逻辑空间。
2.3 文档
文档指最顶层结构或根对象序列化的JSON数据(以唯一Id标识并存储于ES中),相当于关系数据的行。在版本7.0中已经没有文档了,统一为“_doc”。
三、数据的物理存储
ES为什么能搜索和存储海量数据呢?是因为它的水平拓展,它内部分将整个数据进行分片,每个分片存储部分数据。

如图:将整个数据分为5片,每一片都有一个副本,5个主分片分别存储在不同节点。每个节点就是一个ElasticSearch实例。
3.1 数据是怎么存储到分片中的?
在创建索引时,主分片的数量和其副本的数量已经确定了,当创建文档时,Es会根据文档的Id值选择一个主分片,可能这个主分片,在另一个节点。文档被发送到主分片和该主分片所有的副分片中。在新建一个文档的时候, Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下面这个公式决定的:
shard = hash(routing) % number_of_primary_shards
routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。这就解释了为什么我们要在创建索引的时候就确定好主分片的数量 并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
新建、索引、删除操作,必须在主分片上完成后才能被复制到相关副分片。
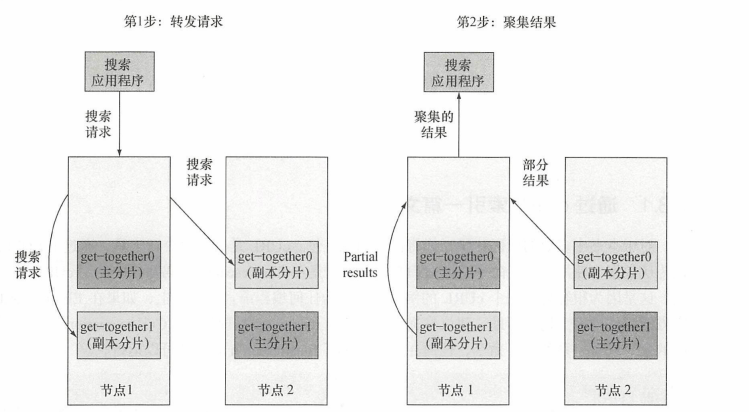
3.2 多个节点查询的过程
当其中一个节点接收到搜索请求时,会将请求转发到其他节点,然后将每个节点的结果聚集返回。在默认情况下,搜索请求通过round-robin轮询机制选中主分片和副分片。
3.3 为什么ElasticSearch查询快?
Es为了查询速度,使用的是倒排索引。假如存储的两个个文档中Content字段值为:
1:My nickname is Microheart.
2:Hello Microheart
为了创建倒排索引,Es首先将每个文档的 content 值拆分成单独的词(也就是tokens),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。
|
my |
1 |
|
nickname |
1 |
|
is |
1 |
|
microheart |
1,2 |
|
hello |
2 |
3.4 相关性
上面的例子,提到了相关性,相关性主要根据下面三个有关:
- 检索词频率:检索词在该字段出现的频率,出现频率越高,相关性也越高。 字段中出现过 5 次要比只出现过 1 次的相关性高。
- 反向文档频率:每个检索词在索引中出现的频率,频率越高,相关性越低。检索词出现在多数文档中会比出现在少数文档中的权重更低。
- 字段长度准则:字段的长度是多少?长度越长,相关性越低。 检索词出现在一个短的 title 要比同样的词出现在一个长的 content 字段权重更大。
3.5 映射
域映射:域最重要的属性是type,就是字段类型。对于非string的域,只需要设置type
string域映射有两个重要的属性 index和 analyzer
Index:控制怎样索引字符串
- analyzed :首先分析字符串,然后索引它。换句话说,以全文索引这个域。
- not_analyzed:索引这个域,所以它能够被搜索,但索引的是精确值。不会对它进行分析。
- no:不索引这个域。这个域不会被搜索到。
analyzer:指定分词器
上面的例子中,为什么会按照单词拆词呢?因为默认不指定分词器,就是standard分词器,它会按照英文单词拆词。分词器有:snowball、standard、keyword、ik_smart、ik_max_word。其中ik_smart和ik_max_word是中文的分词
ES 2.x版本中只有string类型,ES 5.x以后,只有text 和 keyword字段。
比如一篇博客,有标题和内容两个字段,指定为ik_smart。假如标题为 “.Net Core中使用ElasticSearch”,就会被拆词为 “net”、“core”、 "中"、“使用”、“elasticsearch”。如果用户搜索“.net core”,应该对用户的搜索词也进行拆词,拆分为 “net”、“core”,那么标题就会命中。
/// <summary> /// 标题 /// </summary> [Text(Analyzer = "ik_smart")] public string Title { get; set; } /// <summary> /// 内容 /// </summary> [Text(Analyzer = "ik_smart")] public string Content { get; set; }
四、增删改查
操作ElasticSearch是通过Resful api请求,所以我们可以通过Postman来实践,也可以通过专业工具kibana操作
4.1 添加
POST product/_doc
{
"id": 2,
"partNo": "KF2EDGK-5.08-5P",
"brandName": "KEFA(科发)",
"brandAlias": "KEFA(科发) 科发 KF科发 慈溪科发 KEFA"
}
POST product/_doc/3
{
"id":3
"partNo": "KF2EDGK-5.08-5P",
"brandName": "KEFA(科发)",
"brandAlias": "KEFA(科发) 科发 KF科发 慈溪科发 KEFA"
}
两种区别在于第一种未指定_id ,ElasticSearch会自动生成。第二种指定了_id的值 为3。
添加的数据会被ElasticSearch当做 “_source”字段的值存储,除了_source字段,还有 _Index 、_type、_id 字段。
{
"_index" : "product",
"_type" : "_doc",
"_id" : "FHgny3wBBWoDytZQONAG",
"_score" : 1.0,
"_source" : {
"id" : 2,
"partNo" : "KF2EDGK-5.08-5P",
"brandName" : "KEFA(科发)",
"brandAlias" : "KEFA(科发) 科发 KF科发 慈溪科发 KEFA"
}
},
{
"_index" : "product",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"id" : 3,
"partNo" : "KF2EDGK-5.08-5P",
"brandName" : "KEFA(科发)",
"brandAlias" : "KEFA(科发) 科发 KF科发 慈溪科发 KEFA"
}
}
4.2 修改
PUT product/_doc/3 //更新整个文档
{
"id":3,
"partNo": "123456",
"brandName": "科发",
"brandAlias": "KEFA(科发) 科发 KF科发 慈溪科发 KEFA"
}
POST product/_doc/3/_update //更新部分文档
{
"doc": {
"partNo": "654321"
}
}
4.3 删除
DELETE product //删除整个索引 DELETE product/_doc/1 //删除_id为1的文档
4.4 查询
GET product/_doc/_search //查询所有
{
"query": {
"match_all": {}
}
}
GET product/_doc/3 //查询_id为3的文档
查询关联的比较多,比较复杂,后面我们在慢慢聊。