Hive基础
一、Hive是什么?
Hive的本质就是:将HQL/SQL转化为MapReduce程序在Hadoop上运行,可以看成是一个SQL解析引擎
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
Hive表是HDFS的文件目录,一个表对应一个目录名,如果有分区的话, 则分区值对应子目录。
Hive教程:hive wiki
二、Hive的体系结构:
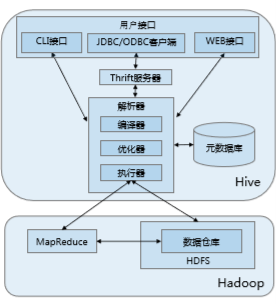
1.用户接口:
(1) CLI:启动时会同时启动一个Hive副本
(2) JDBC客户端:封装了Thrift,java应用程序,可以通过指定的主机和端口连接到在另一个进程中运行的hive服务器
(3) ODBC客户端::ODBC驱动允许支持ODBC协议的应用程序连接到Hive。
2.Thrift服务器:基于socket通讯,支持跨语言
3.解析器(解析要执行的语句):
(1) 编译器:解析语句,进行语法分析、编译、制定查询计划等工作
(2) 优化器:演化组件,规则:列修建,谓词下压
(3) 执行器:会顺序执行所有的Job。
4.元数据库:
Hive的数据由两部分组成:数据文件和元数据。元数据用于存放Hive库的基础信息,它存储在关系数据库中,如 mysql、derby。元数据包括: 数据库信息、表的名字,表的列和分区及其属性,表的属性,表的数据 所在目录等。
三、Hive的运行机制
1.用户通过用户接口连接Hive,发布Hive SQL;
2.Hive解析查询并制定查询计划;
3.Hive将查询转换成MapReduce作业;
4.Hive在Hadoop上执行MapReduce作业。
四、Hive的优缺点
定位是数据仓库,偏向数据分析和计算方向
1.优点:
(1).适合大数据的批量处理
(2).充分利用集群的CPU计算资源、存储资源,实现并行计算
(3).类SQL,自动生成MapReduce
(4).扩展性强
2.缺点:
(1).Hive的HQL表达能力有限
(2).Hive效率低:Hive自动生成MR作业,通常不够智能;HQL 调优困难,粒度较粗;可控性差。
针对效率低下问题: SparkSQL 的出现则有效的提高了 Sql在Hadoop 上的分析运行效率。
五、Hive适用场景
1.海量数据存储及数据分析
2.数据挖掘
3.不适合复杂算法和计算,不适合实时查询
六、使用Hive
(一).连接Hive
使用HiveServer2、Beeline、Cli连接
(二).Hive数据类型
|
分类 |
类型 |
描述 |
示例 |
|
原始类型 |
BOOLEAN |
true/false |
TRUE |
|
TINYINT |
1字节的有符号整数 -128~127 |
1Y |
|
|
SMALLINT |
2个字节的有符号整数,-32768~32767 |
1S |
|
|
INT |
4个字节的带符号整数 |
1 |
|
|
BIGINT |
8字节带符号整数 |
1L |
|
|
FLOAT |
4字节单精度浮点数1.0 |
||
|
DOUBLE |
8字节双精度浮点数 |
1.0 |
|
|
DEICIMAL |
任意精度的带符号小数 |
1.0 |
|
|
STRING |
字符串,变长 |
“a”,’b’ |
|
|
VARCHAR |
变长字符串 |
“a”,’b’ |
|
|
CHAR |
固定长度字符串 |
“a”,’b’ |
|
|
BINARY |
字节数组 |
无法表示 |
|
|
TIMESTAMP |
时间戳,纳秒精度 |
122327493795 |
|
|
DATE |
日期 |
‘2016-03-29’ |
|
|
复杂类型 |
ARRAY |
有序的的同类型的集合 |
array(1,2) |
|
MAP |
key-value,key必须为原始类型,value可以任意类型 |
map(‘a’,1,’b’,2) |
|
|
STRUCT |
字段集合,类型可以不同 |
struct(‘1’,1,1.0), named_stract(‘col1’,’1’,’col2’,1,’clo3’,1.0) |
|
|
UNION |
在有限取值范围内的一个值 |
create_union(1,’a’,63) |
(三).Hive表及其操作
存储的数据+元数据组成
Hive也有数据库,可以通过CREATE DATABASE创建数据库。默认库是default库。
1.包括托管表和外部表两种
(1).数据存储
托管表:数据存储在仓库目录下。
外部表:数据存储在任何HDFS目录下。
(2).数据删除
托管表:删除元数据和数据。
外部表:只删除元数据。
(3).创建表
托管表:CREATE TABLE table_name(attr1 STRING) ;
外部表:CREATE EXTERNAL TABLE table_name(attr1 STRING) LOCATION ‘path’;
一种将数据分片的方式,可以加快查询速度。表->分区->桶。
2.分区(文件夹级别进行的分类)
(1) 分区列并非实际存储的列数据,分区只是表目录下嵌套的目录。
例:
![]()
数据:

(2)可以按照各种维度对表进行分区(上面的例子就是按照风机编号来分区的)。
(3)分区可以缩小查询范围,提高查询效率。
(4)分区是在创建表的时候用PARTITION BY子句定义的。
(5)加载数据到分区使用LOAD语句,且要显示的指定分区值。
(6)使用SHOW PARTITIONS语句查看Hive表下有哪些分区。
(7)使用SELECT语句中指定分区查看数据,Hive只扫描指定分区数据。
(8)Hive表分区分为两种,静态分区和动态分区。静态分区和动态分区的区别在于导入数据时,是手动输入分区名称,还是通过数据来判断数据分区(一般是通过按照hive的分区命名规范由hive来帮我们自动生成分区)。对于大数据批量导入来说,显然采用动态分区更为简单方便

3.桶(在文件内部进行拆分分类)
(1)桶是表上附加的额外结构,可以提高查询效率。有利于做map-side-join()
(2)使用取样更方便高效
(3)使用CLUSTER BY子句来指定划分桶所用的列和要划分桶的个数。
create table bucketed_user(id int,name string) clustered by (id) into 4 buckets;
(4)对桶中的数据可以做排序。使用SORTED BY子句。
create table bucketed_user(id int, name string) clustered by(id) sorted by (id asc) into 4 buckets;
(5)不建议我们自己分桶,建议让Hive划分桶。
(6) 向分桶中填充数据前,需要设置hive.enforce.bucketing设置为true。(创建桶是从其他表中查询出数据时插入到桶中,动态过程)
insert overwrite table bucket_users select * from users;
(7) 实际上桶对应于MapReduce的输出文件分区:一个作业产生的桶和reduce任务个数相同。
4.存储格式
Hive从两个维度对表的存储进行管理:“行格式”(row format)和“文件格式”(file format)。
(1)行格式:
一行中数据的存储格式。按照hive的术语,行格式的定义由SerDe定义,即序列化和反序列化。也就是查询数据时,SerDe将文件中字节形式的数据行反序列化为Hive内部操作数据行时使用的对象形式。Hive向表中插入数据时,序列化工具会将Hive的数据行内部表示形式序列化为字节形式并写到输出文件中去。
(2)文件格式
最简单的文件格式是纯文本文件,但是也可以使用面向列的和面向行的二进制文件格式。 二进制文件可以是顺序文件、Avro、RCFile、ORC、parquet文件。
5.导入数据
(1)Insert方式导入数据:多表插入、动态分区插入。
(2)Load方式导入
(3)CATS方式:把数据查询出来,创建表
6.表的修改和删除
Hive使用“读时模式”,所以在创建表之后,它非常灵活的支持对表定义的修改。但一般需要警惕, 在很多情况下,要由你来确保修改数据以符合新的结构。
(1)重命名表
(2)修改列定义
(3)删除表
(4)截断表(保存表结构,清空表内数据)