&*&:2017/6/16update,最近几天发现阅读这篇文章的朋友比较多,自己阅读发现,部分内容出现了问题,进行了更新。
一、什么是PCA:摘用一下百度百科的解释
PCA(Principal Component Analysis),主成分分析,是一种统计方法,通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。
二、PCA的用途及原理:
- 用途:数据降维
- 原理:线性映射(或线性变换),简单的来说就是将高维空间数据投影到低维空间上,那么在数据分析上,我们是将数据的主成分(包含信息量大的维度)保留下来,忽略掉对数据描述不重要的成分。即将主成分维度组成的向量空间作为低维空间,将高维数据投影到这个空间上就完成了降维的工作。
三、PCA的算法实现:
- 算法思想:选取数据差异最大的方向(方差最大的方向,方差反应的是数据与其方差(均值)之间的偏离程度,我们通常认为方差越大数据的信息量就越大)作为第一个主成分,第二个主成分选择方差次大的方向,并且与第一个主成分正交。不断重复这个过程直到找到n个主成分。
- 算法步骤:
- 输入:数据集D={x1,x2,x3,x4,....xm},低维空间维数 n(xi表示数据的第i维,m表示数据维度为m,n表示最终要变换的维度)
- 操作:1.对所有样本进行中心化,(对每个维度减去这个维度的数据均值)
- 2.计算样本的协方差矩阵
- 3.对协方差矩阵做特征值分解
- 4.选取前n个最大的特征值对应的的特征向量构成特征向量矩阵W
- 输出:Wm*n*Dh*m = D′(一个m*n的矩阵乘以数据集h*m的矩阵得到h*n的矩阵D′)D′就是降维后的数据集h*m->h*n(m<n)
- 算法实现:python3.6<机器学习实战代码>
-
# -*- coding:utf-8 -*- # Filename: pca.py # Author:Ljcx """ pca:(主成分分析)降维算法 """ from numpy import* import pandas as pd import matplotlib.pyplot as plt class PcaM(object): def __init__(self): pass """ 读取数据格式化成矩阵 """ def loadData(self, filename, delim=' '): data = pd.read_csv(filename) x = data[list(range(4))] print (x) return mat(x) def pca(self, dataMat, maxFeature=105): meanValue = mean(dataMat, axis=0) # 去中心,元数据减去均值,值得新的矩阵均值为0 dataRemMat = dataMat - meanValue # 求矩阵的协方差矩阵 covMat = cov(dataRemMat, rowvar=0) print ("-------covMatt------") print (covMat) # 求特征值和特徵向量 feaValue, feaVect = linalg.eig(mat(covMat)) print ("-------特征值-------") print (feaValue) print ("-------特征向量-------") print (feaVect) # 返回从小到大的索引值print "feaSort" + str(feaValueSort) feaValueSort = argsort(feaValue) feaValueTopN = feaValueSort[:-(maxFeature + 1):-1] redEigVects = feaVect[:, feaValueTopN] # 选择之后的特征向量矩阵 print ("--------TopN特征向量矩阵--------") print (redEigVects) print (shape(redEigVects)) lowDataMat = dataRemMat * redEigVects # 数据矩阵*特征向量矩阵 得到降维后的矩阵 reconMat = lowDataMat * redEigVects.T + meanValue #这一步做数据恢复,并没有看懂这么做的意义 print (lowDataMat) return lowDataMat, reconMat def plotW(self, lowDataMat, reconMat): fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(lowDataMat[:, 0], lowDataMat[:, 1], marker='*', s=90) ax.scatter(reconMat[:, 0], reconMat[:, 1], marker='*', s=50, c='red') plt.show() def replaceNanWithMean(self): datMat = self.loadData('testdata.txt', ' ') numFeat = shape(datMat)[1] for i in range(numFeat): # values that are not NaN (a number) meanVal = mean(datMat[nonzero(~isnan(datMat[:, i].A))[0], i]) # set NaN values to mean datMat[nonzero(isnan(datMat[:, i].A))[0], i] = meanVal print(datMat) return datMat if __name__ == "__main__": p = PcaM() dataMat = p.replaceNanWithMean() lowDataMat, reconMat = p.pca(dataMat, 2) p.plotW(dataMat, reconMat)
- 得到降维后数据分布与恢复之后的数据的分布作比较
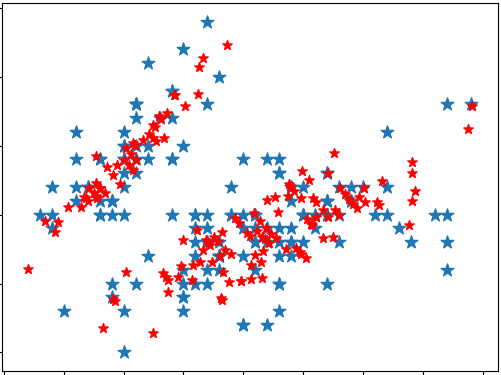
- 数据集data:采用的是150*4的鸢尾花数据集
-
 原始数据集
原始数据集5.1,3.5,1.4,0.2,Iris-setosa 4.9,3.0,1.4,0.2,Iris-setosa 4.7,3.2,1.3,0.2,Iris-setosa 4.6,3.1,1.5,0.2,Iris-setosa 5.0,3.6,1.4,0.2,Iris-setosa 5.4,3.9,1.7,0.4,Iris-setosa 4.6,3.4,1.4,0.3,Iris-setosa 5.0,3.4,1.5,0.2,Iris-setosa 4.4,2.9,1.4,0.2,Iris-setosa 4.9,3.1,1.5,0.1,Iris-setosa 5.4,3.7,1.5,0.2,Iris-setosa 4.8,3.4,1.6,0.2,Iris-setosa 4.8,3.0,1.4,0.1,Iris-setosa 4.3,3.0,1.1,0.1,Iris-setosa 5.8,4.0,1.2,0.2,Iris-setosa 5.7,4.4,1.5,0.4,Iris-setosa 5.4,3.9,1.3,0.4,Iris-setosa 5.1,3.5,1.4,0.3,Iris-setosa 5.7,3.8,1.7,0.3,Iris-setosa 5.1,3.8,1.5,0.3,Iris-setosa 5.4,3.4,1.7,0.2,Iris-setosa 5.1,3.7,1.5,0.4,Iris-setosa 4.6,3.6,1.0,0.2,Iris-setosa 5.1,3.3,1.7,0.5,Iris-setosa 4.8,3.4,1.9,0.2,Iris-setosa 5.0,3.0,1.6,0.2,Iris-setosa 5.0,3.4,1.6,0.4,Iris-setosa 5.2,3.5,1.5,0.2,Iris-setosa 5.2,3.4,1.4,0.2,Iris-setosa 4.7,3.2,1.6,0.2,Iris-setosa 4.8,3.1,1.6,0.2,Iris-setosa 5.4,3.4,1.5,0.4,Iris-setosa 5.2,4.1,1.5,0.1,Iris-setosa 5.5,4.2,1.4,0.2,Iris-setosa 4.9,3.1,1.5,0.1,Iris-setosa 5.0,3.2,1.2,0.2,Iris-setosa 5.5,3.5,1.3,0.2,Iris-setosa 4.9,3.1,1.5,0.1,Iris-setosa 4.4,3.0,1.3,0.2,Iris-setosa 5.1,3.4,1.5,0.2,Iris-setosa 5.0,3.5,1.3,0.3,Iris-setosa 4.5,2.3,1.3,0.3,Iris-setosa 4.4,3.2,1.3,0.2,Iris-setosa 5.0,3.5,1.6,0.6,Iris-setosa 5.1,3.8,1.9,0.4,Iris-setosa 4.8,3.0,1.4,0.3,Iris-setosa 5.1,3.8,1.6,0.2,Iris-setosa 4.6,3.2,1.4,0.2,Iris-setosa 5.3,3.7,1.5,0.2,Iris-setosa 5.0,3.3,1.4,0.2,Iris-setosa 7.0,3.2,4.7,1.4,Iris-versicolor 6.4,3.2,4.5,1.5,Iris-versicolor 6.9,3.1,4.9,1.5,Iris-versicolor 5.5,2.3,4.0,1.3,Iris-versicolor 6.5,2.8,4.6,1.5,Iris-versicolor 5.7,2.8,4.5,1.3,Iris-versicolor 6.3,3.3,4.7,1.6,Iris-versicolor 4.9,2.4,3.3,1.0,Iris-versicolor 6.6,2.9,4.6,1.3,Iris-versicolor 5.2,2.7,3.9,1.4,Iris-versicolor 5.0,2.0,3.5,1.0,Iris-versicolor 5.9,3.0,4.2,1.5,Iris-versicolor 6.0,2.2,4.0,1.0,Iris-versicolor 6.1,2.9,4.7,1.4,Iris-versicolor 5.6,2.9,3.6,1.3,Iris-versicolor 6.7,3.1,4.4,1.4,Iris-versicolor 5.6,3.0,4.5,1.5,Iris-versicolor 5.8,2.7,4.1,1.0,Iris-versicolor 6.2,2.2,4.5,1.5,Iris-versicolor 5.6,2.5,3.9,1.1,Iris-versicolor 5.9,3.2,4.8,1.8,Iris-versicolor 6.1,2.8,4.0,1.3,Iris-versicolor 6.3,2.5,4.9,1.5,Iris-versicolor 6.1,2.8,4.7,1.2,Iris-versicolor 6.4,2.9,4.3,1.3,Iris-versicolor 6.6,3.0,4.4,1.4,Iris-versicolor 6.8,2.8,4.8,1.4,Iris-versicolor 6.7,3.0,5.0,1.7,Iris-versicolor 6.0,2.9,4.5,1.5,Iris-versicolor 5.7,2.6,3.5,1.0,Iris-versicolor 5.5,2.4,3.8,1.1,Iris-versicolor 5.5,2.4,3.7,1.0,Iris-versicolor 5.8,2.7,3.9,1.2,Iris-versicolor 6.0,2.7,5.1,1.6,Iris-versicolor 5.4,3.0,4.5,1.5,Iris-versicolor 6.0,3.4,4.5,1.6,Iris-versicolor 6.7,3.1,4.7,1.5,Iris-versicolor 6.3,2.3,4.4,1.3,Iris-versicolor 5.6,3.0,4.1,1.3,Iris-versicolor 5.5,2.5,4.0,1.3,Iris-versicolor 5.5,2.6,4.4,1.2,Iris-versicolor 6.1,3.0,4.6,1.4,Iris-versicolor 5.8,2.6,4.0,1.2,Iris-versicolor 5.0,2.3,3.3,1.0,Iris-versicolor 5.6,2.7,4.2,1.3,Iris-versicolor 5.7,3.0,4.2,1.2,Iris-versicolor 5.7,2.9,4.2,1.3,Iris-versicolor 6.2,2.9,4.3,1.3,Iris-versicolor 5.1,2.5,3.0,1.1,Iris-versicolor 5.7,2.8,4.1,1.3,Iris-versicolor 6.3,3.3,6.0,2.5,Iris-virginica 5.8,2.7,5.1,1.9,Iris-virginica 7.1,3.0,5.9,2.1,Iris-virginica 6.3,2.9,5.6,1.8,Iris-virginica 6.5,3.0,5.8,2.2,Iris-virginica 7.6,3.0,6.6,2.1,Iris-virginica 4.9,2.5,4.5,1.7,Iris-virginica 7.3,2.9,6.3,1.8,Iris-virginica 6.7,2.5,5.8,1.8,Iris-virginica 7.2,3.6,6.1,2.5,Iris-virginica 6.5,3.2,5.1,2.0,Iris-virginica 6.4,2.7,5.3,1.9,Iris-virginica 6.8,3.0,5.5,2.1,Iris-virginica 5.7,2.5,5.0,2.0,Iris-virginica 5.8,2.8,5.1,2.4,Iris-virginica 6.4,3.2,5.3,2.3,Iris-virginica 6.5,3.0,5.5,1.8,Iris-virginica 7.7,3.8,6.7,2.2,Iris-virginica 7.7,2.6,6.9,2.3,Iris-virginica 6.0,2.2,5.0,1.5,Iris-virginica 6.9,3.2,5.7,2.3,Iris-virginica 5.6,2.8,4.9,2.0,Iris-virginica 7.7,2.8,6.7,2.0,Iris-virginica 6.3,2.7,4.9,1.8,Iris-virginica 6.7,3.3,5.7,2.1,Iris-virginica 7.2,3.2,6.0,1.8,Iris-virginica 6.2,2.8,4.8,1.8,Iris-virginica 6.1,3.0,4.9,1.8,Iris-virginica 6.4,2.8,5.6,2.1,Iris-virginica 7.2,3.0,5.8,1.6,Iris-virginica 7.4,2.8,6.1,1.9,Iris-virginica 7.9,3.8,6.4,2.0,Iris-virginica 6.4,2.8,5.6,2.2,Iris-virginica 6.3,2.8,5.1,1.5,Iris-virginica 6.1,2.6,5.6,1.4,Iris-virginica 7.7,3.0,6.1,2.3,Iris-virginica 6.3,3.4,5.6,2.4,Iris-virginica 6.4,3.1,5.5,1.8,Iris-virginica 6.0,3.0,4.8,1.8,Iris-virginica 6.9,3.1,5.4,2.1,Iris-virginica 6.7,3.1,5.6,2.4,Iris-virginica 6.9,3.1,5.1,2.3,Iris-virginica 5.8,2.7,5.1,1.9,Iris-virginica 6.8,3.2,5.9,2.3,Iris-virginica 6.7,3.3,5.7,2.5,Iris-virginica 6.7,3.0,5.2,2.3,Iris-virginica 6.3,2.5,5.0,1.9,Iris-virginica 6.5,3.0,5.2,2.0,Iris-virginica 6.2,3.4,5.4,2.3,Iris-virginica 5.9,3.0,5.1,1.8,Iris-virginica

- 协方差矩阵cov(方阵4*4):
-
[[ 0.68656811 -0.0372787 1.27036233 0.51534691] [-0.0372787 0.18792128 -0.31673091 -0.11574868] [ 1.27036233 -0.31673091 3.09637221 1.28912434] [ 0.51534691 -0.11574868 1.28912434 0.57956557]]
- 特征值featValue(4):
-
[ 4.20438706 0.24314579 0.07905128 0.02384304]
- 特征向量矩阵featVet(方阵4*4):(每一列特征值对应一个特征向量)
-
[[ 0.36263433 -0.6558202 -0.58115529 0.3172613 ] [-0.08122848 -0.73001455 0.59619427 -0.32408808] [ 0.85629752 0.17703033 0.07265649 -0.47972477] [ 0.35868209 0.07509244 0.54911925 0.75111672]]
- 根据特征值可以看出前2个特征值占比重比较大,所以选择前两个特征值对应的特征向量组正特征向量矩阵
- topX特征向量矩阵redEigVects:
-
[[ 0.36263433 -0.6558202 ] [-0.08122848 -0.73001455] [ 0.85629752 0.17703033] [ 0.35868209 0.07509244]]
- 降维后的数据集:data(m*n)*redEigVects(n*x)=data(m*x)原数据集乘以选择后的特征向量矩阵得到降维后的数据集
-
降维后的数据集
[[-2.73363445 0.16331092] [-2.90803676 0.13076902] [-2.76491784 0.30475856] [-2.7461081 -0.34027983] [-2.29679724 -0.75348469] [-2.83904793 0.0755604 ] [-2.64423265 -0.17657389] [-2.90682876 0.56422248] [-2.69199575 0.10050325] [-2.52354747 -0.65790634] [-2.63112977 -0.02770681] [-2.80576609 0.2213837 ] [-3.24397251 0.4961847 ] [-2.65975154 -1.19234788] [-2.39988069 -1.3506441 ] [-2.63931625 -0.82429682] [-2.66585361 -0.32535115] [-2.21575231 -0.88473854] [-2.6045924 -0.52665249] [-2.32791942 -0.4034959 ] [-2.56060135 -0.44614179] [-3.23368084 -0.14876388] [-2.32098224 -0.11122065] [-2.37424051 0.02540228] [-2.52611151 0.13313497] [-2.48686648 -0.14385237] [-2.57982864 -0.38073938] [-2.65733554 -0.32544096] [-2.6511475 0.18387812] [-2.60676122 0.19129755] [-2.42744251 -0.42388348] [-2.66443393 -0.82625736] [-2.61352803 -1.10619867] [-2.69199575 0.10050325] [-2.88487621 -0.08368008] [-2.64229784 -0.61289151] [-2.69199575 0.10050325] [-3.00058136 0.47351799] [-2.60796922 -0.24215591] [-2.7877468 -0.27747216] [-2.87158978 0.9264554 ] [-3.01682706 0.32751508] [-2.42325291 -0.20183533] [-2.22620519 -0.44833111] [-2.73402967 0.23640219] [-2.55483086 -0.5164587 ] [-2.85867044 0.21405407] [-2.5598109 -0.59232432] [-2.72173956 -0.12127547] [ 1.26785226 -0.6856034 ] [ 0.91488037 -0.3200081 ] [ 1.44683939 -0.50410462] [ 0.16172993 0.82370953] [ 1.06926494 -0.07588127] [ 0.62179131 0.41605337] [ 1.0776218 -0.28451223] [-0.7709864 0.99775123] [ 1.02566911 -0.22948323] [-0.0293133 0.71825598] [-0.53097208 1.2595811 ] [ 0.49291964 0.10079581] [ 0.24356531 0.54627315] [ 0.96584991 0.12363915] [-0.19326273 0.24930664] [ 0.91029555 -0.46896498] [ 0.6410186 0.35065097] [ 0.21605396 0.33013295] [ 0.92358198 0.54117049] [ 0.0243815 0.57940308] [ 1.09805709 0.08353883] [ 0.33869628 0.06521013] [ 1.27799588 0.32739624] [ 0.90223634 0.18162211] [ 0.69625299 -0.15142829] [ 0.88215497 -0.33038151] [ 1.31344654 -0.24473051] [ 1.53980154 -0.2672176 ] [ 0.79419518 0.16132435] [-0.32586514 0.36249822] [-0.08938884 0.70028352] [-0.2108868 0.67507124] [ 0.11653087 0.30974537] [ 1.3600876 0.4210547 ] [ 0.56849174 0.48181501] [ 0.78944915 -0.19617369] [ 1.20305302 -0.40834664] [ 0.7943564 0.3698655 ] [ 0.22676318 0.26482035] [ 0.14548423 0.67770662] [ 0.44401218 0.66800805] [ 0.87209731 0.03293466] [ 0.21028347 0.40044986] [-0.72660012 1.00517067] [ 0.33676147 0.50152775] [ 0.31278815 0.20943212] [ 0.35677921 0.28994282] [ 0.62372612 -0.02026425] [-0.92760343 0.74798588] [ 0.27927231 0.34524124] [ 2.51362245 0.0132104 ] [ 1.39516536 0.57474647] [ 2.59899587 -0.34018141] [ 1.95251737 0.18183938] [ 2.33165373 0.04311693] [ 3.37972129 -0.54417028] [ 0.49952523 1.18975088] [ 2.91455996 -0.35005959] [ 2.301322 0.24692319] [ 2.90125455 -0.77832912] [ 1.64426335 -0.2418257 ] [ 1.78400546 0.21666042] [ 2.14768656 -0.21424748] [ 1.32538608 0.77613761] [ 1.56638355 0.53929124] [ 1.88686405 -0.11830988] [ 1.93129164 -0.04002915] [ 3.4724999 -1.16855166] [ 3.77710179 -0.24961889] [ 1.27920388 0.7608497 ] [ 2.41070022 -0.37540785] [ 1.17912435 0.60501224] [ 3.48199197 -0.4535556 ] [ 1.36935481 0.20392106] [ 2.25831409 -0.33226376] [ 2.59703873 -0.55659104] [ 1.23933878 0.17879859] [ 1.2724594 0.11608073] [ 2.10450828 0.21178655] [ 2.37028851 -0.46101268] [ 2.82355495 -0.37053698] [ 3.2164011 -1.36784329] [ 2.14037649 0.21929579] [ 1.42488684 0.14379794] [ 1.76088622 0.50197081] [ 3.05957239 -0.68324898] [ 2.12711239 -0.13811243] [ 1.88690536 -0.04744858] [ 1.15056621 0.16395972] [ 2.0901974 -0.37053399] [ 2.29653466 -0.18143615] [ 1.90504456 -0.4086246 ] [ 1.39516536 0.57474647] [ 2.54569629 -0.27441977] [ 2.40178693 -0.30222678] [ 1.92627029 -0.18675607] [ 1.50709846 0.37513625] [ 1.7461388 -0.07811976] [ 1.88372124 -0.11544572] [ 1.37119204 0.28265084]]
四、PCA算法原理:
- 一句话总结这个算法的精髓:
数据集D乘一个矩阵W,使得m*n的矩阵变成了m*x的矩阵,数据从n维降到了x维。
- 那么如何找到这个W矩阵很关键。这里找的前x个最大的特征值对应的特征向量构成的矩阵作为w。
我们先来看一下W*D,两个矩阵相乘的意义:
就是将右矩阵投影(变换)在以左矩阵作为基的空间中,原理中也说到它就是一种线性映射(线性变换)。(这里所说的左右矩阵跟我们数据是列向量还是行向量有关,如果是行向量那么久恰好相反,事实上并不用在意这个是行向量还是列向量,我们只要知道矩阵的数据是在行上还是列上,维度在行上还是列上,就很容易搞清楚。)
- 为什么要算协方差矩阵?
根据方差和协方差的计算公式可以看出当均值为0的时候,协方差矩阵=A*AT,这也是为什么要对数据要进行中心化(数据减去均值)的原因(极大简化了协方差矩阵的计算),协方差矩阵是个方阵且是个对称阵,它的的对角线就是方差。方差是反映数据信息量的大小,我们通常说的方差指的是数据在平行于坐标轴上的信息量传播。也就是说每个维度上信息量的传播。这是在二维数据上,如果实在多维数据上,我们要度量数据在多个维度上信息的传播量以及非平行于坐标轴放方向上数据的传播,就是要用协方差表示,从矩阵中我们可以观察到数据在每一个维度上的传播。数据的协方差确定了传播的方向,而方差确定了传播的大小,当然方差和协方差是正相关的。所以说,方差最大的方向就是协方差最大的方向。而协方差的特征向量topX总是指向最大方差的方向,特征向量正交,所以作为一组变换基向量很合适(其实这种逆向推到很蹩脚)。
说实话,看的明白,很多东西讲不清楚,工科出身,数学功底差的一塌糊涂。PCA思想很简单,用Python实现也很简单,几个步骤照着做就好了,但是用特征向量做线性变换这是个核心的地方。最后的目的都是向最大方差靠近。当然为什么要求协方差矩阵,我也是理解了很久。
看到的一些很好的文章给大家,希望对大家有所启发。
协方差矩阵的集合解释:http://www.cnblogs.com/nsnow/p/4758202.html
PCA的数学原理:http://blog.csdn.net/xiaojidan2011/article/details/11595869