转载请注明出处:http://www.cnblogs.com/Peyton-Li/
在求解机器学习算法的优化问题时,梯度下降是经常采用的方法之一。
梯度下降不一定能够找到全局最优解,有可能是一个局部最优解。但如果损失函数是凸函数,梯度下降法得到的一定是全局最优解。
梯度下降的相关概念:
1、步长或学习率(learning rate):步长和学习率是一个东西,只是在不同的地方叫法不一样,以下叫做步长。步长决定了在梯度下降过程中,每一步沿梯度负方向前进的长度。
2、假设函数(hypothesis function):也就是我们的模型学习到的函数,记为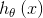 。
。
3、损失函数(loss function):为了评估模型的好坏,通常用损失函数来度量拟合的程度。在线性回归中,损失函数通常为样本label和假设函数输出的差的平方,比如对样本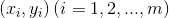 ,采用线性回归,损失函数为:
,采用线性回归,损失函数为:
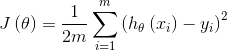
梯度下降算法:
1、先决条件:确认优化模型的假设函数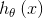 和损失函数
和损失函数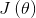
2、参数的初始化:初始化假设函数的参数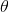 (
(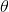 是一个向量),算法终止距离
是一个向量),算法终止距离 以及步长
以及步长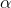
3、算法过程:
1)确定当前位置的损失函数的梯度,对于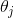 ,其梯度如下:
,其梯度如下:
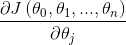
2)确定是否所有的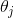 ,梯度下降的距离都小于
,梯度下降的距离都小于 ,如果小于
,如果小于 则算法终止,当前所有的
则算法终止,当前所有的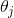 即为最终结果。否则进入步骤3
即为最终结果。否则进入步骤3
3)更新所有的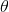 ,对于
,对于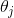 ,其更新表达式如下。更新完毕后进入步骤1
,其更新表达式如下。更新完毕后进入步骤1
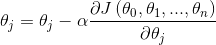
以上为梯度下降算法。
梯度下降法关于参数更新方式的不同又可分为:
1、批量梯度下降法(Batch Gradient Descent(BGD))
2、随机梯度下降法(Stochastic Gradient Descent(SGD))
3、小批量梯度下降法(Mini-batch Gradient Descent(MBGD))
1、批量梯度下降法(Batch Gradient Descent(BGD)):
批量梯度下降法是梯度下降法最原始的形式,它的具体思路是在更新每一参数时都使用所有的样本来进行更新,其数学形式如下:
1)对上述的损失函数求偏导:
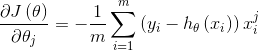
2)由于是最小化风险函数,所以按照每个参数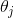 的梯度负方向来更新每个
的梯度负方向来更新每个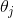 :
:
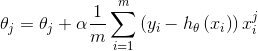
具体的伪代码形式为:
repeat{
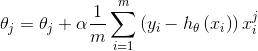
(for every j=0,...,n)
}
从上面的公式可以看出,它得到的是一个全局最优解,但是每迭代一次,都要用到训练集所有的数据,如果样本数目m很大,那么这种迭代速度将会很慢。
优点:全局最优解;易于并行实现
缺点:当样本数目很多时,训练过程会很慢
从迭代次数上来看,BGD迭代的次数相对较少。
2、随机梯度下降法(Stochastic Gradient Descent(SGD)):
由于批量梯度下降法在更新每一个参数时,都需要所有的训练样本,训练过程会随着样本数量的加大而变得异常缓慢。随机梯度下降法正是为了解决批量梯度下降法这一弊端而提出的。
将损失函数写为如下形式:
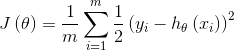
利用每个样本的损失函数对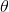 求偏导得到对应的梯度,来更新
求偏导得到对应的梯度,来更新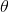 :
:
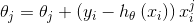
具体的伪代码形式为:
1、Randomly shuffle dataset;
2、repeat{
for i=1,...,m{
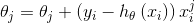
(for j=0,...,n)
}
}
随机梯度下降是通过每个样本来迭代更新一次,如果样本量很大的情况(例如几十万),那么可能只用其中几万条或者几千条的样本,就已经将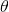 迭代到最优解了,对比上面的批量梯度下降,迭代一次要用到所有的训练样本,一次迭代不可能最优。而且,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。
迭代到最优解了,对比上面的批量梯度下降,迭代一次要用到所有的训练样本,一次迭代不可能最优。而且,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。
优点:训练速度快
缺点:准确度下降,并不是全局最优;不易于并行实现
从迭代次数上看,SGD迭代的次数较多,在解空间的搜索过程看起来有些盲目。
SGD方法的一个缺点是,其更新方向完全依赖于当前的batch,因而其更新十分不稳定。解决这一问题的一个简单的做法便是引入momentum。
momentum即动量,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。这样一来,可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力:
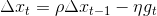
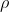 即momentum,表示要在多大程度上保留原来的更新方向,这个值在0-1之间,在训练开始时,由于梯度可能会很大,所以初始值一般选为0.5;当梯度不那么大时,改为0.9。
即momentum,表示要在多大程度上保留原来的更新方向,这个值在0-1之间,在训练开始时,由于梯度可能会很大,所以初始值一般选为0.5;当梯度不那么大时,改为0.9。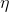 是学习率,即当前batch的梯度多大程度上影响最终更新方向,跟普通的SGD含义相同。
是学习率,即当前batch的梯度多大程度上影响最终更新方向,跟普通的SGD含义相同。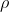 和
和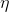 之和不一定为1。
之和不一定为1。3、小批量梯度下降法(Mini-batch Gradient Descent(MBGD)):
由上述的两种梯度下降法可以看出,其各自均有优缺点。而小批量梯度下降法(Mini-batch Gradient Descent(MBGD))则在这两种方法的性能之间取得一个折中,即算法的训练过程比较快,而且也保证最终参数训练的准确率。
MBGD在每次更新参数时使用b个样本(b一般为10),其具体的伪代码形式为:
set b=10, m=1000
Repeat{
for i=1,11,21,31,991{
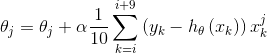
(for every j=0,...,n)
}
}
参考博客:
http://www.cnblogs.com/pinard/p/5970503.html
http://www.cnblogs.com/maybe2030/p/5089753.html