文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 罗昭成
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
获取猫眼接口数据
作为一个长期宅在家的程序员,对各种抓包简直是信手拈来。在 Chrome 中查看原代码的模式,可以很清晰地看到接口,接口地址即为:
http://m.maoyan.com/mmdb/comments/movie/1208282.json?_v_=yes&offset=15
在 Python 中,我们可以很方便地使用 request 来发送网络请求,进而拿到返回结果:
1 def getMoveinfo(url): 2 session = requests.Session() 3 headers = { 4 "User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X)" 5 } 6 response = session.get(url, headers=headers) 7 if response.status_code == 200: 8 return response.text 9 return None
根据上面的请求,我们能拿到此接口的返回数据,数据内容有很多信息,但有很多信息是我们并不需要的,先来总体看看返回的数据:
1 { 2 "cmts":[ 3 { 4 "approve":0, 5 "approved":false, 6 "assistAwardInfo":{ 7 "avatar":"", 8 "celebrityId":0, 9 "celebrityName":"", 10 "rank":0, 11 "title":"" 12 }, 13 "authInfo":"", 14 "cityName":"贵阳", 15 "content":"必须十分,借钱都要看的一部电影。", 16 "filmView":false, 17 "id":1045570589, 18 "isMajor":false, 19 "juryLevel":0, 20 "majorType":0, 21 "movieId":1208282, 22 "nick":"nick", 23 "nickName":"nickName", 24 "oppose":0, 25 "pro":false, 26 "reply":0, 27 "score":5, 28 "spoiler":0, 29 "startTime":"2018-11-22 23:52:58", 30 "supportComment":true, 31 "supportLike":true, 32 "sureViewed":1, 33 "tagList":{ 34 "fixed":[ 35 { 36 "id":1, 37 "name":"好评" 38 }, 39 { 40 "id":4, 41 "name":"购票" 42 } 43 ] 44 }, 45 "time":"2018-11-22 23:52", 46 "userId":1871534544, 47 "userLevel":2, 48 "videoDuration":0, 49 "vipInfo":"", 50 "vipType":0 51 } 52 ] 53 } 54
如此多的数据,我们感兴趣的只有以下这几个字段:
nickName, cityName, content, startTime, score
接下来,进行我们比较重要的数据处理,从拿到的 JSON 数据中解析出需要的字段:
1 def parseInfo(data): 2 data = json.loads(html)['cmts'] 3 for item in data: 4 yield{ 5 'date':item['startTime'], 6 'nickname':item['nickName'], 7 'city':item['cityName'], 8 'rate':item['score'], 9 'conment':item['content'] 10 }
拿到数据后,我们就可以开始数据分析了。但是为了避免频繁地去猫眼请求数据,需要将数据存储起来,在这里,笔者使用的是 SQLite3,放到数据库中,更加方便后续的处理。存储数据的代码如下:
1 def saveCommentInfo(moveId, nikename, comment, rate, city, start_time) 2 conn = sqlite3.connect('unknow_name.db') 3 conn.text_factory=str 4 cursor = conn.cursor() 5 ins="insert into comments values (?,?,?,?,?,?)" 6 v = (moveId, nikename, comment, rate, city, start_time) 7 cursor.execute(ins,v) 8 cursor.close() 9 conn.commit() 10 conn.close()
数据处理
因为前文我们是使用数据库来进行数据存储的,因此可以直接使用 SQL 来查询自己想要的结果,比如评论前五的城市都有哪些:
SELECT city, count(*) rate_count FROM comments GROUP BY city ORDER BY rate_count DESC LIMIT 5
结果如下:
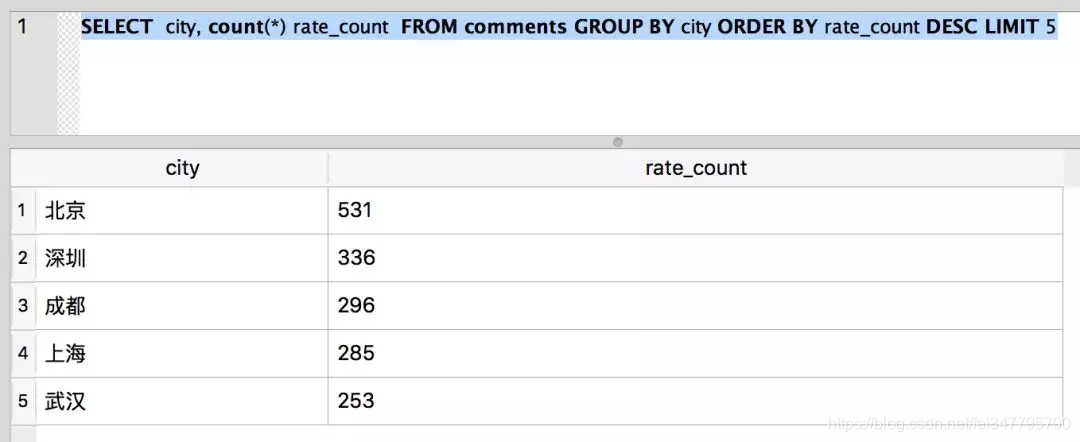
从上面的数据, 我们可以看出来,来自北京的评论数最多。
不仅如此,还可以使用更多的 SQL 语句来查询想要的结果。比如每个评分的人数、所占的比例等。如笔者有兴趣,可以尝试着去查询一下数据,就是如此地简单。
而为了更好地展示数据,我们使用 Pyecharts 这个库来进行数据可视化展示。
根据从猫眼拿到的数据,按照地理位置,直接使用 Pyecharts 来在中国地图上展示数据:
1 data = pd.read_csv(f,sep='{',header=None,encoding='utf-8',names=['date','nickname','city','rate','comment']) 2 city = data.groupby(['city']) 3 city_com = city['rate'].agg(['mean','count']) 4 city_com.reset_index(inplace=True) 5 data_map = [(city_com['city'][i],city_com['count'][i]) for i in range(0,city_com.shape[0])] 6 geo = Geo("GEO 地理位置分析",title_pos = "center",width = 1200,height = 800) 7 while True: 8 try: 9 attr,val = geo.cast(data_map) 10 geo.add("",attr,val,visual_range=[0,300],visual_text_color="#fff", 11 symbol_size=10, is_visualmap=True,maptype='china') 12 13 except ValueError as e: 14 e = e.message.split("No coordinate is specified for ")[1] 15 data_map = filter(lambda item: item[0] != e, data_map) 16 else : 17 break 18 geo.render('geo_city_location.html')
注:使用 Pyecharts 提供的数据地图中,有一些猫眼数据中的城市找不到对应的从标,所以在代码中,GEO 添加出错的城市,我们将其直接删除,过滤掉了不少的数据。
使用 Python,就是如此简单地生成了如下地图: 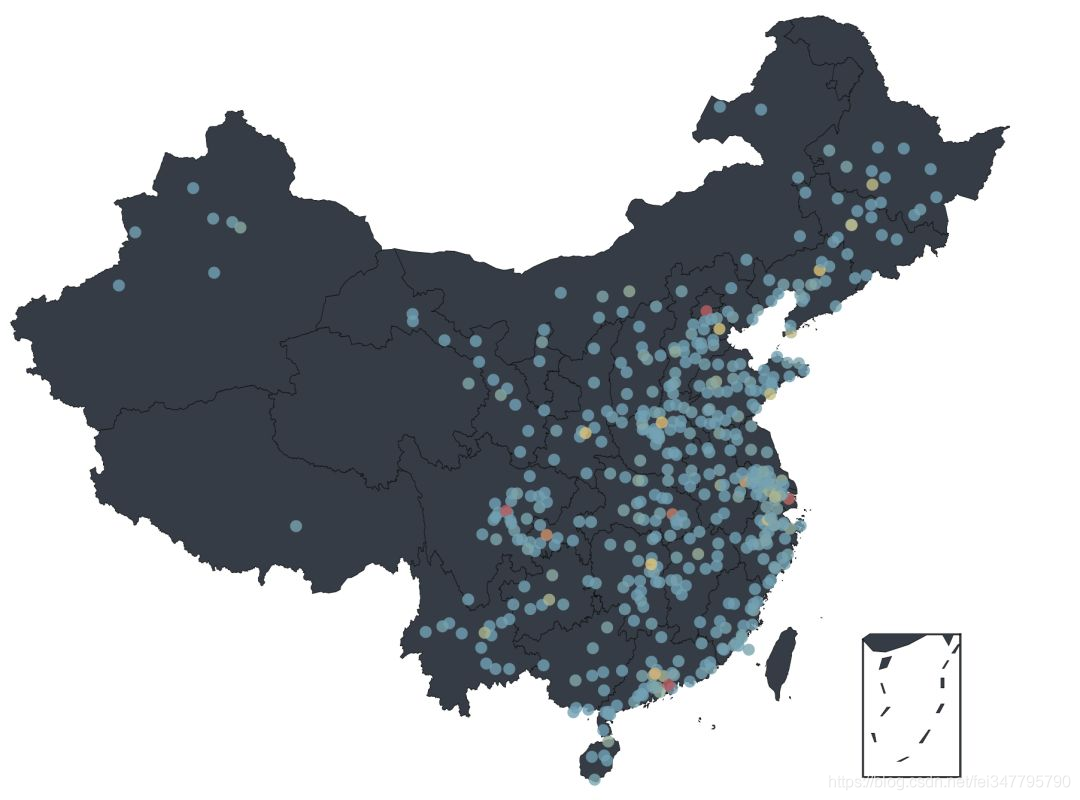
从可视化数据中可以看出,既看电影又评论的人群主要分布在中国东部,又以北京、上海、成都、深圳最多。虽然能从图上看出来很多数据,但还是不够直观,如果想看到每个省/市的分布情况,我们还需要进一步处理数据。
而在从猫眼中拿到的数据中,城市包含数据中具备县城的数据,所以需要将拿到的数据做一次转换,将所有的县城转换到对应省市里去,然后再将同一个省市的评论数量相加,得到最后的结果。
1 data = pd.read_csv(f,sep='{',header=None,encoding='utf-8',names=['date','nickname','city','rate','comment']) 2 city = data.groupby(['city']) 3 city_com = city['rate'].agg(['mean','count']) 4 city_com.reset_index(inplace=True) 5 fo = open("citys.json",'r') 6 citys_info = fo.readlines() 7 citysJson = json.loads(str(citys_info[0])) 8 data_map_all = [(getRealName(city_com['city'][i], citysJson),city_com['count'][i]) for i in range(0,city_com.shape[0])] 9 data_map_list = {} 10 for item in data_map_all: 11 if data_map_list.has_key(item[0]): 12 value = data_map_list[item[0]] 13 value += item[1] 14 data_map_list[item[0]] = value 15 else: 16 data_map_list[item[0]] = item[1] 17 data_map = [(realKeys(key), data_map_list[key] ) for key in data_map_list.keys()] 18 def getRealName(name, jsonObj): 19 for item in jsonObj: 20 if item.startswith(name) : 21 return jsonObj[item] 22 return name 23 def realKeys(name): 24 return name.replace(u"省", "").replace(u"市", "") 25 .replace(u"回族自治区", "").replace(u"维吾尔自治区", "") 26 .replace(u"壮族自治区", "").replace(u"自治区", "")
经过上面的数据处理,使用 Pyecharts 提供的 map 来生成一个按省/市来展示的地图:
1 def generateMap(data_map): 2 map = Map("城市评论数", width= 1200, height = 800, title_pos="center") 3 while True: 4 try: 5 attr,val = geo.cast(data_map) 6 map.add("",attr,val,visual_range=[0,800], 7 visual_text_color="#fff",symbol_size=5, 8 is_visualmap=True,maptype='china', 9 is_map_symbol_show=False,is_label_show=True,is_roam=False, 10 ) 11 except ValueError as e: 12 e = e.message.split("No coordinate is specified for ")[1] 13 data_map = filter(lambda item: item[0] != e, data_map) 14 else : 15 break 16 map.render('city_rate_count.html')
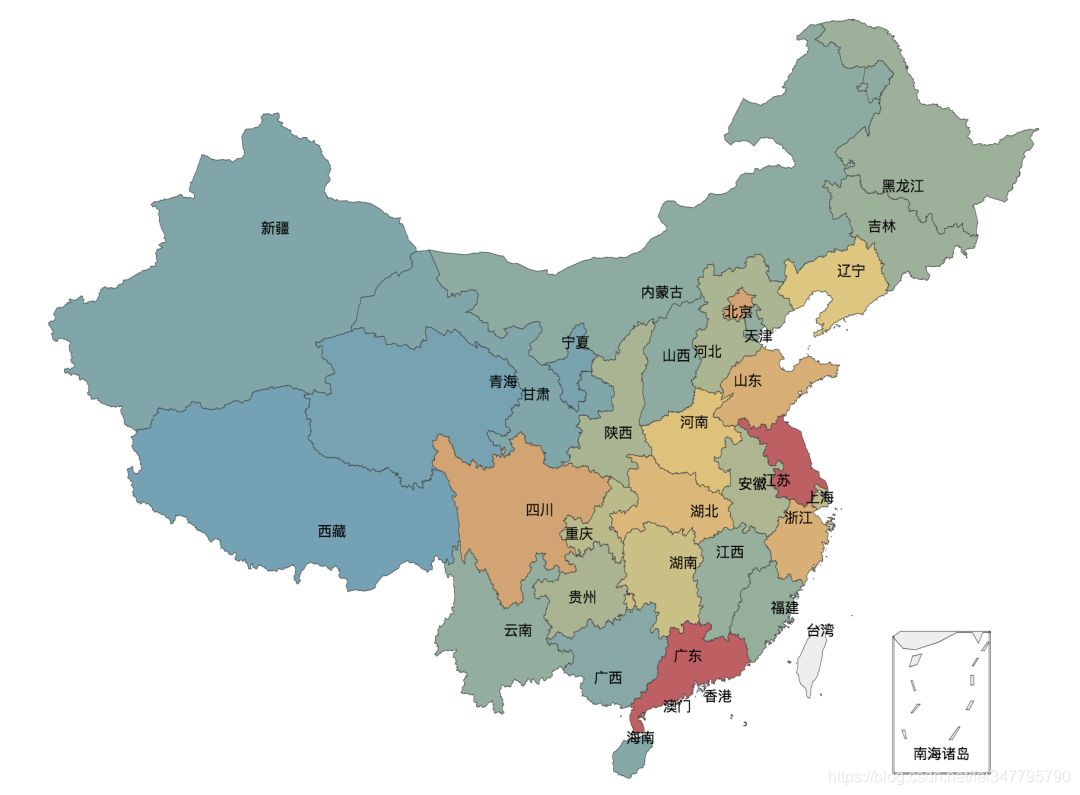
当然,我们还可以来可视化一下每一个评分的人数,这个地方采用柱状图来显示:
1 data = pd.read_csv(f,sep='{',header=None,encoding='utf-8',names=['date','nickname','city','rate','comment']) 2 # 按评分分类 3 rateData = data.groupby(['rate']) 4 rateDataCount = rateData["date"].agg([ "count"]) 5 rateDataCount.reset_index(inplace=True) 6 count = rateDataCount.shape[0] - 1 7 attr = [rateDataCount["rate"][count - i] for i in range(0, rateDataCount.shape[0])] 8 v1 = [rateDataCount["count"][count - i] for i in range(0, rateDataCount.shape[0])] 9 bar = Bar("评分数量") 10 bar.add("数量",attr,v1,is_stack=True,xaxis_rotate=30,yaxix_min=4.2, 11 xaxis_interval=0,is_splitline_show=True) 12 bar.render("html/rate_count.html")
画出来的图,如下所示,在猫眼的数据中,五星好评的占比超过了 50%,比豆瓣上 34.8% 的五星数据好很多。
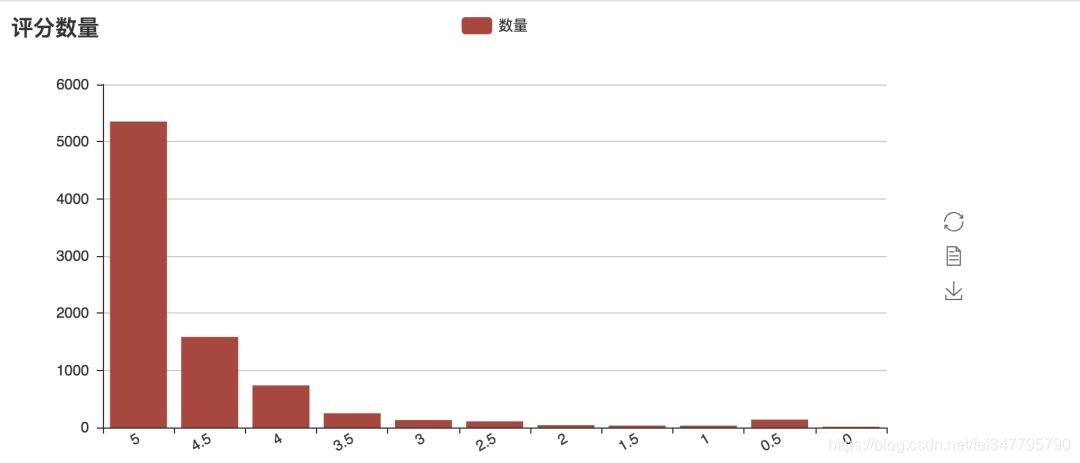
从以上观众分布和评分的数据可以看到,这一部剧,观众朋友还是非常地喜欢。前面,从猫眼拿到了观众的评论数据。现在,笔者将通过 jieba 把评论进行分词,然后通过 Wordcloud 制作词云,来看看,观众朋友们对《无名之辈》的整体评价:
1 data = pd.read_csv(f,sep='{',header=None,encoding='utf-8',names=['date','nickname','city','rate','comment']) 2 comment = jieba.cut(str(data['comment']),cut_all=False) 3 wl_space_split = " ".join(comment) 4 backgroudImage = np.array(Image.open(r"./unknow_3.png")) 5 stopword = STOPWORDS.copy() 6 wc = WordCloud(width=1920,height=1080,background_color='white', 7 mask=backgroudImage, 8 font_path="./Deng.ttf", 9 stopwords=stopword,max_font_size=400, 10 random_state=50) 11 wc.generate_from_text(wl_space_split) 12 plt.imshow(wc) 13 plt.axis("off") 14 wc.to_file('unknow_word_cloud.png')
导出:
