HDUOJ题目HTML的爬取
封装好的exe/app的GitHub地址:https://github.com/Rhythmicc/HDUHTML 按照系统选择即可。
其实没什么难度,先爬下来一个题目的html,然后正则匹配一波塞个标签上去就好了。
下图运行效果:
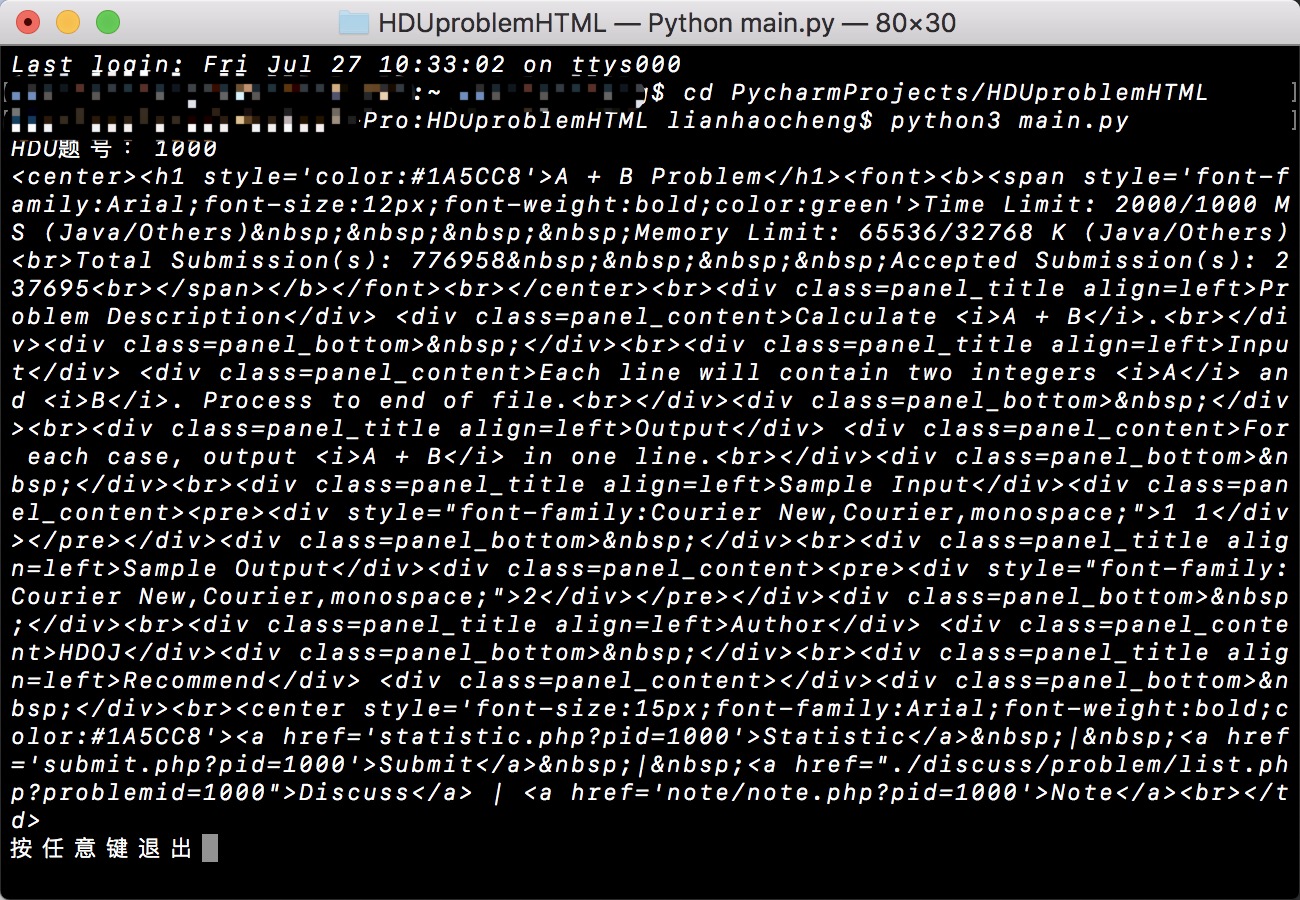
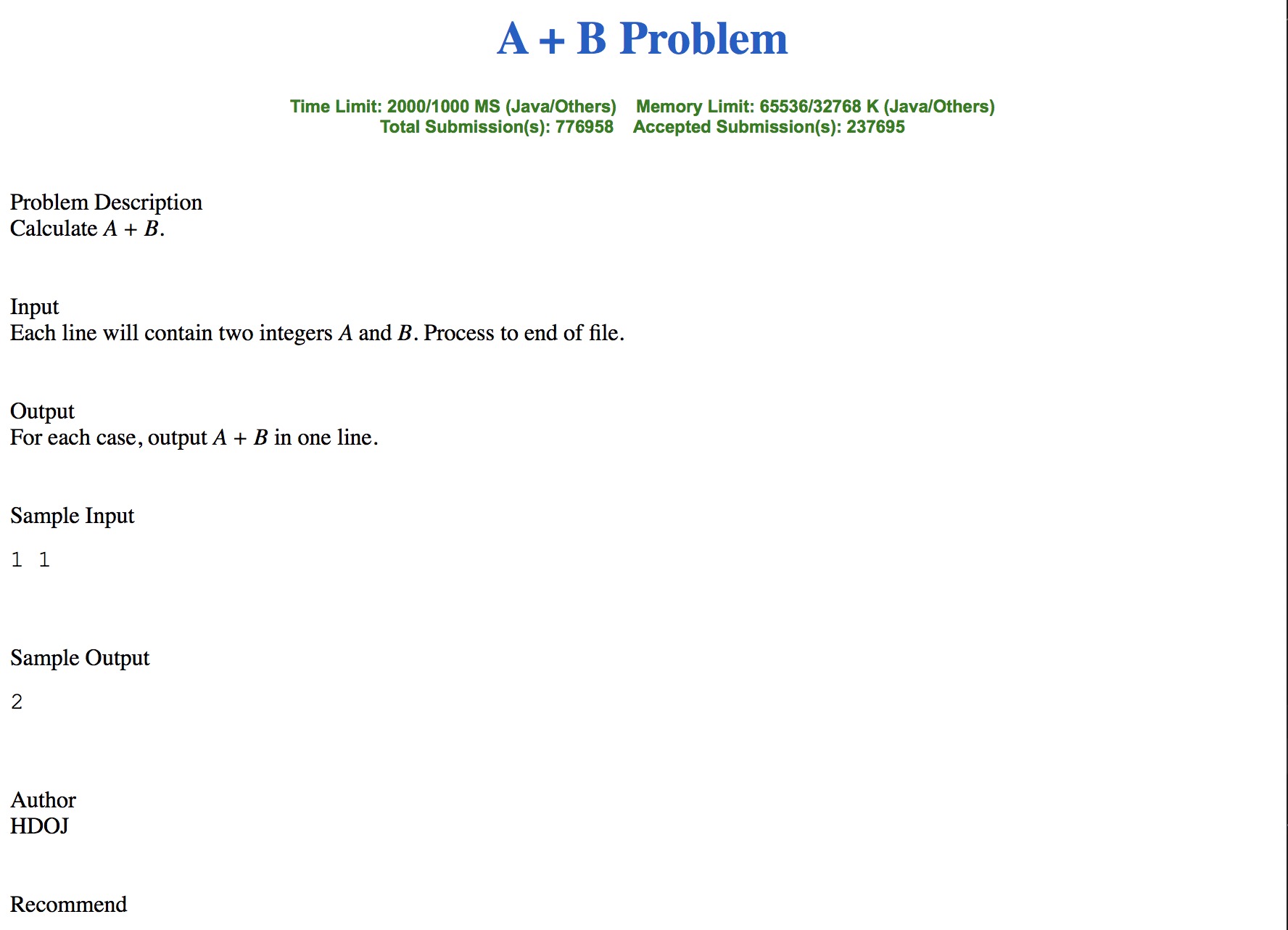
下面是爬取下的HTML运行效果:
源码:


import re import requests from requests.exceptions import RequestException url = "http://acm.hdu.edu.cn/showproblem.php?pid=" + input("HDU题号:") headers = { 'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/11.1.2 Safari/605.1.15"} def get_one_page(url, headers): try: response = requests.get(url, headers=headers) if response.status_code == 200: response.encoding = 'utf-8' return response.text return None except RequestException: return None html = get_one_page(url, headers=headers) tmp=re.findall('<tr><td align=center>(.*?)</tr>',html,re.S)[0] ans=re.findall('<h1 (.*?)<br><div class=panel_title(.*)',tmp,re.S)[0] print('<center><h1 '+ans[0]+'</center><br><div class=panel_title'+ans[1]) ask=input('按任意键退出')
求求你们放过我的博客吧,转载要注明出处呀。。