一.为什么要大数据学习?
这是一个大数据的时代,一个企业只有掌握了大数据才能把握住市场的命脉,一个人掌握了大数据就可以比较轻松的向机器学习、人工智能等方向发展。所以我们有必要去掌握大数据的技术同时也关注大数据的发展趋势,不能裹足不前。
二.关于本专题的学习
作为一个普通本科大学生,在校的大数据学习比较的“水”,普通大学嘛,大家都懂。在一个就是编程实战方向上的东西本来就该靠自学,而不是靠别人去教。我觉得大数据的学习是一个缓慢的过程,需要半年的时间去学习。我想在大二结束差不多就可以完成大数据最基本的学习了。(看看明年暑假能不能去个公司实习一下:-))因为这也是我也是第一次学习大数据,这一系列文章是我的学习笔记而不是我的工作经历总结,其中难免有部分错误,还望前辈们不啬赐教。
三.在阿里云上安装hadoop,同时集成6台云主机
3.1版本说明:1.Linux centos7
2.Java jdk1.8
3.Hadoop Hadoop2.7.3
3.2 安装Java
在这里我们使用的是Java 1.8,当然你也可以使用其他的版本,但是一定要是Linux版本的Java!
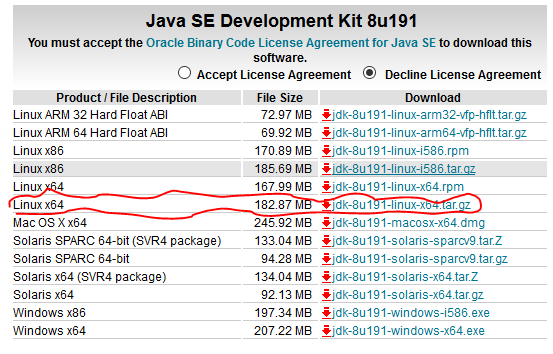 我们下载的压缩包格式,下载到本地后通过winscp上传到阿里云上
我们下载的压缩包格式,下载到本地后通过winscp上传到阿里云上
下载链接 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
我们在阿里云上的opt文件夹下创建Java文件夹和hadoop文件夹如图
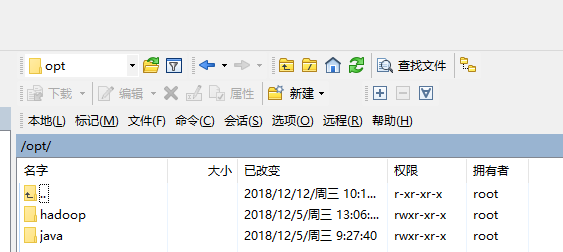
我们将我们的Java压缩包放到Java文件夹中去。
然后进入该文件夹执行解压操作
进入该文件夹 cd /opt/java
解压操作 tar -zxvf jdk-8u 191-linux-x64.tar.gz (注意你自己的jdk版本号和你自己的文件名)
解压完成后会看见一个文件夹如下
接下来我们呢就要去配置文件了
修改/etc/profile文件 使用命令符 vim /etc/profile
在文件的最后加上
export JAVA_HOME=/opt/java/jdk1.8.0_191 (注意你自己的版本号)
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
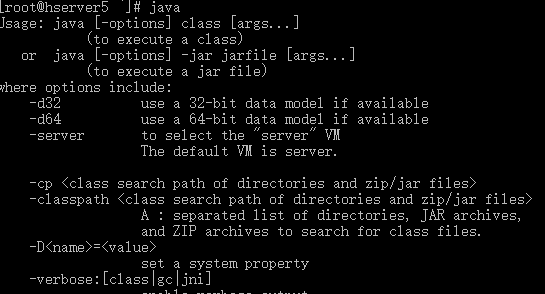
更改完后输入命令命令符 Java、 javac、java -version。
出现下面的字符说明安装成功:


3.3实现6个机子ssh免密码登录
检查机器名称
输入命令符 hostname 可以查看你们的机器名称,如图: 如果你没有改过你的hostname那么应该是一个乱码,那么我们使用命令来修改主机名称 hostname hserver1(1号一般为namenode)
如果你没有改过你的hostname那么应该是一个乱码,那么我们使用命令来修改主机名称 hostname hserver1(1号一般为namenode)其他的5台服务器也是分别为hserver2、hserver3、hserver4、hserver5、hserver6(这几个为datenode)
修改映射文件输入命令符vim /etc/hosts 将所有的服务器的主机ip地址和他们的hostname相对应
如图:
修改完成后我们检查一下是否能够发送成功。
ping -c 3 hserver2
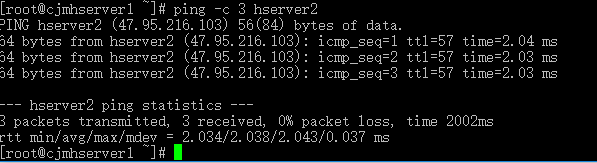
这样就说明成功了,当然剩下的5台服务器也测试后成功了。
配置ssh文件
输入命令 ssh-keygen -t rsa -P ''
在过程中需要输入回车
然后ls /root/.ssh/ 出现下图

查看id_rsa.pub vim id_rsa.pub
我们将所有主机中的id_rsa.pub 文件中的公匙复制到一个文件中authorized_keys,然后将authorized_keys放置到/root/.ssh/文件夹下
查看authorized_keys vim authorized_keys 如下:
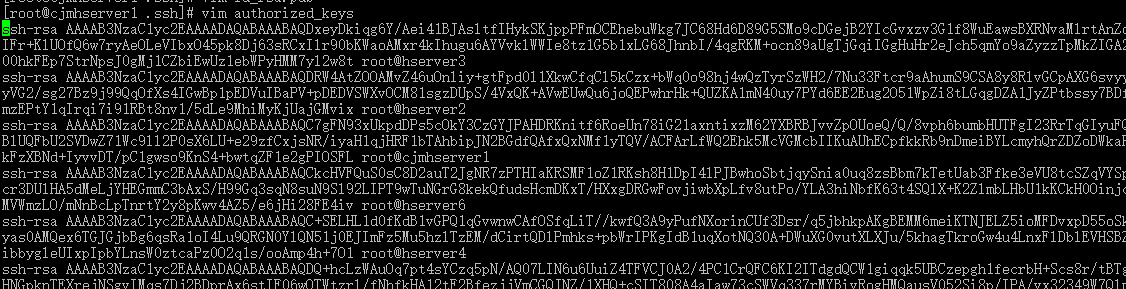
测试是否ssh配置成功
依次检查ssh hserver2 、3、4、5、6
 第一次输入一般会询问链接 输入yes
第一次输入一般会询问链接 输入yes
测试完后一定要关闭链接否者你在本机上的命令会在那一台机子上执行,
命令符 exit 退出
3.4安装hadoop
下载hadoop到本地然后上传到阿里云上,解压。资源网上都有可以去找 ,我这里使用的Hadoop版本为2.7.3下面解压后所有的路径你们根据你们的版本去修改。
我们的将Hadoop的压缩包放到/opt/hadoop/文件夹下:
然后我们进入该文件夹 cd /opt/hadoop/
接着执行 tar -xvf hadoop-2.7.3.tar.gz (注意你们的文件版本名)解压文件
解压完成后你会的得到一个文件夹

然后创建如下几个文件夹
mkdir /root/hadoop
mkdir /root/hadoop/tmp
mkdir /root/hadoop/var
mkdir /root/hadoop/dfs
mkdir /root/hadoop/dfs/name
mkdir /root/hadoop/dfs/data
修改配置文件:
vim /opt/hadoop/hadoop-2.7.3/etc/hadoop/core-site.xml
在<configuration>节点中写入:
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hserver1:9000</value>
</property>
</configuration>
注意如果你的namenode的hostname不为hserver1你要改成你的namenode的hostname
vim /opt/hadoop/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
将export JAVA_HOME=${JAVA_HOME}
修改为:
export JAVA_HOME=/opt/java/jdk1.8.0_191 (注意你自己的Java版本号)
vim /opt/hadoop/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
在<configuration>节点中写入:
<property>
<name>dfs.name.dir</name>
<value>/root/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>need not permissions</description>
</property>
在该版本中,有一个名为mapred-site.xml.template的文件,复制该文件,然后改名为mapred-site.xml,命令是:
cp /opt/hadoop/hadoop-2.8.0/etc/hadoop/mapred-site.xml.template /opt/hadoop/hadoop-2.7.3/etc/hadoop/mapred-site.xml
vim /opt/hadoop/hadoop-2.7.3/etc/hadoop/mapred-site.xml
在<configuration>节点内加入配置:
<property>
<name>mapred.job.tracker</name>
<value>hserver1:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/root/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
vim /opt/hadoop/hadoop-2.7.3/etc/hadoop/slaves
加入你的datenode的hostname
如下图:

vim /opt/hadoop/hadoop-2.7.3/etc/hadoop/yarn-site.xml
在<configuration>节点内加入配置
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hserver1</value>
</property>
<property>
<description>The address of the applications manager interface in the RM.</description>
<name>yarn.resourcemanager.address</name>
<value>0.0.0.0:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>0.0.0.0:8030</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>0.0.0.0:8088</value>
</property>
<property>
<description>The https adddress of the RM web application.</description>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>0.0.0.0:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>0.0.0.0:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>0.0.0.0:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
<discription>每个节点可用内存,单位MB,默认8182MB</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
四.初始化hadoop和执行hadoop
cd /opt/hadoop/hadoop-2.7.3/bin 进入文件夹
./hadoop namenode -format 初始化脚本
格式化成功后,可以在看到在/root/hadoop/dfs/name/目录多了一个current目录,而且该目录内有一系列文件
在namenode上去执行启动命令
cd /opt/hadoop/hadoop-2.8.0/sbin (进入文件夹)
./start-all.sh (执行命令)
过程中所有询问输入yes
五.测试hadoop是否成功
namenode的地址为39.105.201.218
关闭防火墙 systemctl stop firewalld.service 后
打开:
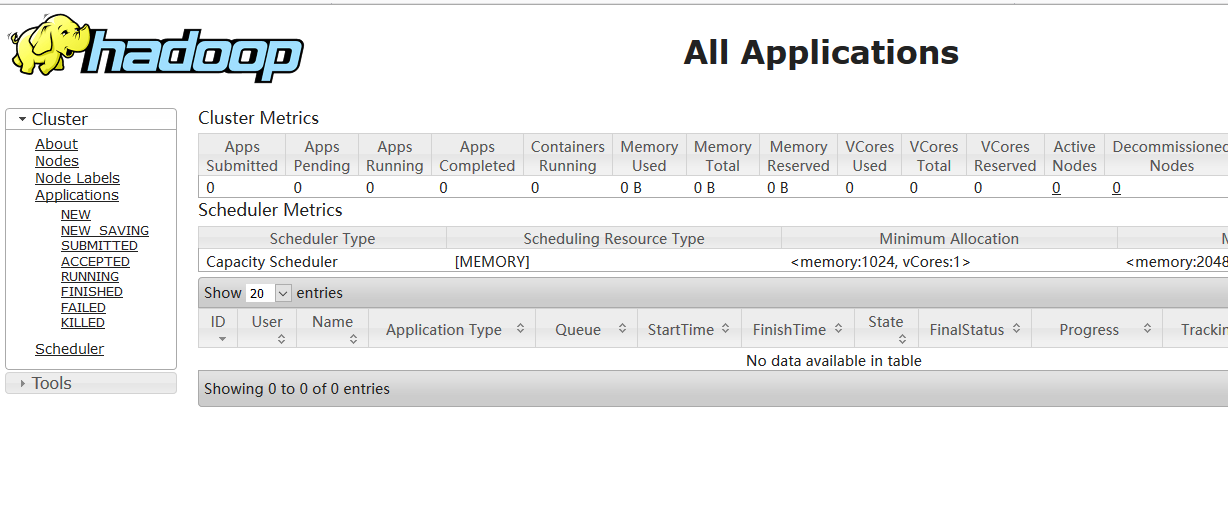
http://39.103.201.218:50090/(HDFS管理界面)

http://39.103.201.218:8088/ (cluster页面)
参考文章 https://blog.csdn.net/pucao_cug/article/details/71698903