三:工作队列
一:概念
在工作队列中,其会避免立刻去执行耗时且需要等待执行结果的任务,相反我们可以将其稍后执行,我们将任务封装成一个个消息加入到队列中,一个在后台执行的任务进程会接收任务并最终执行任务,当你使很多工人(worker)运行的时候,多个任务由多个(worker)共同执行,提升效率
这个概念在web应用中尤其有用,因为在一次短期的HTTP请求中处理复杂任务几乎是不可能的。
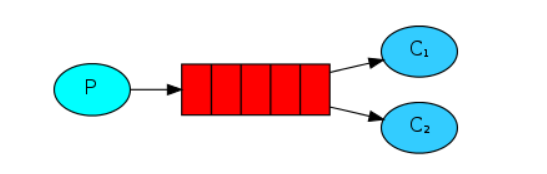
PS:此时一个有一个任务发送者P,两个任务处理者C1,C2
消息产生者
import pika # 引入mq包 import time credentials = pika.PlainCredentials('SR', '123456') # 如果需要远程连接mq服务需要传入用户名密码进行验证 connection = pika.BlockingConnection(pika.ConnectionParameters(host='127.0.0.1', port=5672)) # 创建mq的连接 channel = connection.channel() # 创建一个中间件人broker res = channel.queue_declare(queue='test_mq') # 创建一个队列 队列名称SR for i in range(3): message = 'hello world%s' % i # 向队列插入数值 routing_key是队列名 # body传入的数据 channel.basic_publish(exchange='', routing_key='test_mq', body=message) connection.close() # 关闭链接通道
消息处理者
import pika import time credentials = pika.PlainCredentials('SR', '123456') # 如果需要远程连接mq服务需要传入用户名密码进行验证 connection = pika.BlockingConnection(pika.ConnectionParameters(host='127.0.0.1', port=5672)) # 创建mq的连接 channel = connection.channel() # 声明一个频道 res = channel.queue_declare(queue='test_mq') # 创建一个队列 队列名称SR 防止生产者没有队列 消费者不知道从哪个队列取数据 def callback(ch, method, properties, body): print(body) # 告诉rabbitmq,用callback来接收消息 channel.basic_consume( queue='test_mq', # 指定队列名 on_message_callback=callback # 从队列里获取消息 ) # 开始接收信息,并进入阻塞状态,队列里有信息才会调用callback进行处理 channel.start_consuming()
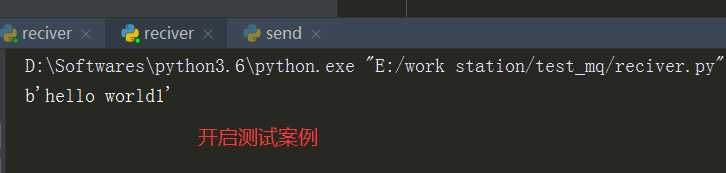
上图开辟一个生产者两个消费者
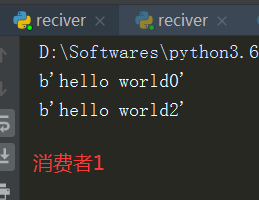
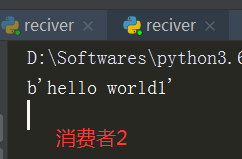
PS:
(1)开启三个任务两个消费者在队列中分别轮询进行任务调度
(2)任务队列帮助我们可以高效的进行高并发,更好的提升效率
二:队列缺点
一:影响
1:工作者的任务是否完成
2:当工作者挂掉之后,如何防止未完成的任务丢失,并且继续处理这些任务
3:RabbitMq自身出现问题(服务器宕机),此时如何防止丢失
4:任务有轻重缓急,如何实现公平调度
二:解决办法
1:消息确认机制(Message Acknowledgment)
当工作者(receiver)完成任务之后会发送消息告诉生产者(send)自己已经完成任务
def callback(ch, method, properties, body): print(body)
time.sleep(10) # 方便退出
print('工作者挂掉') # 当工作者完成任务后,会反馈给rabbitmq ch.basic_ack(delivery_tag=method.delivery_tag)
2:任务保留(no_ack=False)
当工作者挂掉之后 防止任务丢失
channel.basic_consume( queue='test_mq', # 指定队列名 on_message_callback=callback, # 从队列里获取消息 no_ack=False # 进行任务保留 当工作者任务执行到一半的时候挂掉了 保留当前的任务 )
3:消息持久化(Message durability)
声明持久化存储
channel.queue_declare(queue='test_mq',durable=True) # durable=True 声明消息持久化存储
在发送任务时,用delivery_mode=2来标记任务为持久化存储:
channel.basic_publish(exchange='', routing_key='test_mq', body=message ,properties=pika.BasicProperties( delivery_mode=2 ))
4:公平调度(Fair dispatch)
使用basic_qos设置prefetch_count=1,使得rabbitmq不会在同一时间给工作者分配多个任务,即只有工作者完成任务之后,才会再次接收到任务
channel.basic_qos(prefetch_count=1)
三:完整代码
生产者端
import pika import random hostname = '127.0.0.1' parameters = pika.ConnectionParameters(hostname) connection = pika.BlockingConnection(parameters) # 创建通道 channel = connection.channel() # 如果rabbitmq自身挂掉的话,那么任务会丢失。所以需要将任务持久化存储起来,声明持久化存储: channel.queue_declare(queue='task_queue_mq_test1', durable=True) for i in range(3): number = random.randint(1, 1000) message = 'hello world:%s' % number # 在发送任务的时候,用delivery_mode=2来标记任务为持久化存储: channel.basic_publish(exchange='', routing_key='task_queue_mq_test1', body=message, properties=pika.BasicProperties( delivery_mode=2, )) print (" [x] Sent %r" % (message,)) connection.close()
接受者端
import pika import time hostname = '127.0.0.1' parameters = pika.ConnectionParameters(hostname) connection = pika.BlockingConnection(parameters) # 创建通道 channel = connection.channel() # durable=True后将任务持久化存储,防止任务丢失 channel.queue_declare(queue='task_queue_mq_test1', durable=True) # ch.basic_ack为当工作者完成任务后,会反馈给rabbitmq def callback(ch, method, properties, body): print (" [x] Received %r" % (body,)) time.sleep(20) print (" [x] Done") # 当工作者完成任务后,会反馈给rabbitmq ch.basic_ack(delivery_tag=method.delivery_tag) # basic_qos设置prefetch_count=1,使得rabbitmq不会在同一时间给工作者分配多个任务, # 即只有工作者完成任务之后,才会再次接收到任务。 channel.basic_qos(prefetch_count=1) # 去除no_ack=True参数或者设置为False后可以实现 # 一个工作者ctrl+c退出后,正在执行的任务也不会丢失,rabbitmq会将任务重新分配给其他工作者。 channel.basic_consume(queue='task_queue_mq_test1',on_message_callback=callback , auto_ack=False) # 开始接收信息,按ctrl+c退出 print (' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming()
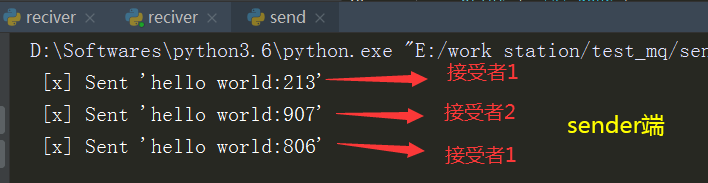
如上图:先启动发生产者端,生产者分别将不同的消息发送到接受者端

接受者1:接受者1在处理hello world806的时候挂掉了
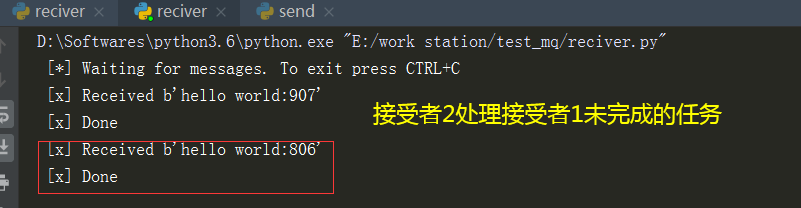
PS:上述接受者二 完成接受者一未完成的任务