文章目录
题目
- 请建立数学模型,解决下列三个问题:
(1)建立人脸位置判断的数学模型,判断人脸在照片中的大致位置,并在图1和图2中用你设计的模型“框出”人脸的大致位置。
(2)在问题(1)的基础上,建立人脸精确识别的数学模型,判断图2中各个人物的脸型、鼻型、眼型、唇形等。(提示:如果你在DIY过程中遇到了困难,不妨降低要求,比如说鼻型可以分为“大鼻子”和“小鼻子”。)
(3)在问题(2)的基础上,建立人脸匹配的数学模型,判断图2、图3中是否有人物与图1的人物是同一人,如果有,请在图片中框出具体是哪个人物与图1的人物一样。
图一:

图二:

图三:(hm…有一说一不吹不黑纯路人我寻思我都可以去TF家族照相了)

论文:DIY人脸识别技术
摘 要
- 本文针对机场的出租车问题进行了研究,建立了基于多属性的出租车司机接客决策树模型,通过基于Python的爬虫技术,获得了交通信息数据集,经过基于大数据的程序批量预处理后,作为验证集与其他不确定属性协同验证了模型的可行性,以此推广应用到出租车司机的收益问题上
- 针对问题一,概括为建立出租车司机选择的决策模型。其主要思想是:首先宏观分析出租车司机决策模型的本质影响机理:收益值;然后列举出影响收益值的下一级因素:排队时间,放空时间,接客收益时间,继续向下分析出影响时间的多个属性:等车乘客数及其增量,排队车辆数,机场续车池分批效率,最高效空载距离,以及其他不确定因素。从底层属性到决策结果建立出三层决策树模型。(如:附录一1.问题一)。
- 针对问题二,概括为验证模型并分析可行性和多属性因子的问题。首先基于问题一决策树模型底层影响属性,判断出影响司机决策的主观因素需要用到的验证集:该时间段航班数据集和最高效空载距离集;然后通过Python爬虫技术,获得成都双流机场到港航班的数据集和成都出租车GPS定位的打车需求量和出租车分布的特征数据集;再通过Python进行数据集清洗预处理,得到某一时间段航班数量表和最高效空载距离,通过类比推理的思想,验证了百度地图热度图的参考价值,将百度地图热度图数据作为短距离运输最高效空载距离参考;最后通过Python进行决策树构建以及大数据运算,得出每天每个时间段的出租车司机决策结果。(如:附录一2.问题二)
- 针对问题三,概括为人脸匹配问题。首先搜索出问题二的三个人分别50张图片作为训练集,其次通过主成分分析法(PCA)进行训练集降维,测试集通过问题一的人脸识别并提取后,使用KNN最邻近分类算法和SVM模型对训练集进行训练,然后调节训练参数并对测试集进行预测,在测试集图片中框出人脸并在之上标出预测结果。(如:附件一3.问题三)
- 针对问题四,概括为需要改善之前建立的决策树模型的时间距离收益属性,有针对的提供补偿措施。首先将问题二的基于GPS定位的打车需求量和出租车分布的特征数据集进行目的地概率预测,表现形式以平面-气泡图转化为热度图呈现,得出地点概率预测列表,得出距离概率期望值;然后求出问题一的决策树模型第二层的时间距离收益的拐点,找到即使比排队时早接客,但是由于空载原因使收益仍然低于排队的时间或距离区间;结合实际情况在这个区间
最后,本文对模型进行了误差分析,还对模型的优点和缺点进行了评价,分 别在广度和深度上对模型进行了推广。
关键词:Haar特征分类器;Adaboost算法;PCA主成分分析法;KNN最邻近分类算法;SVM模型;人脸匹配;图像处理;Python
1.问题的重述
1.1 问题的背景
曾经神秘的人脸识别技术,由于越来越贴近生活,现在也变得平常起来。美图秀秀等手机APP把人脸识别技术用于“一键美颜”,让留住的瞬间更加美丽;学校和公司逐步安装了人脸识别考勤机,方便管理人员进行考核和查勤;警方在刑事侦查时,也经常采用人脸识别技术从海量信息中寻找犯罪嫌疑人,使正义的力量得到技术的支持;交互式机器人通过人脸识别技术判断用户的心情。因此,人脸识别技术应用广泛,越来越深入我们的日常生活,本文认为对DIY人脸识别技术的研究十分重要。
1.2 问题的求解
常用的第一步人脸识别方法:第一步,确定人脸的位置;第二步,对人脸做一些技术处理;第三步,提取人脸的细节特征。本文在计算机上实现DIY人脸技术识别,根据提出的问题建立模型,并设计求解方案解决一下问题。
问题一:建立人脸位置判断的数学模型,判断人脸在照片中的大致位置,并在附件_图1和附件_图2中用你设计的模型“框出”人脸的大致位置。
问题二:在问题一的基础上,建立人脸精确识别的数学模型,判断图2中各个人物的脸型、鼻型、眼型、唇形等五官。
问题三:在问题二的基础上,建立人脸匹配的数学模型,判断附件_图2、附件_图3中是否有人物与附件_图1的人物是同一人,如果有,请在图片中框出具体是哪个人物与附件_图1的人物一样。
2.问题的分析
2.1 问题一的分析
本文需要我们建立模型设计出算法判断出人脸。判断人脸在图片中的大致位置,并能够用矩形框出图片中的人脸,附件中每张图片包含的人脸个数不唯一,并且人脸的位置和形状大小等特征差异很大,所以需要先对图片进行预处理,以准确获得完整清晰的人脸图像。由于每张人脸照片的信息量很大,进行识别前需要用主成分分析法提取主要的特征信息。
2.2 问题二的分析
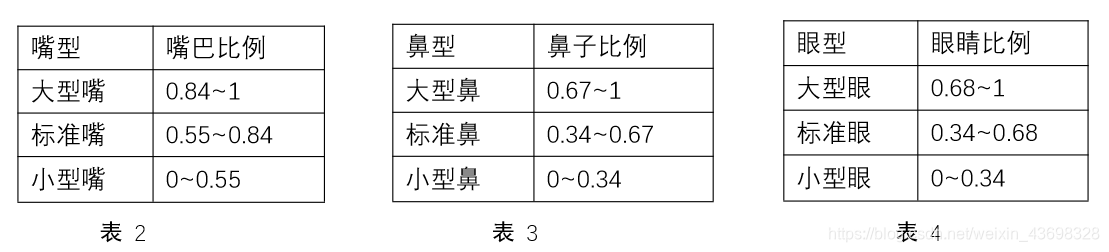
在问题一大致判断出人脸位置的基础上进行精确人脸识别,需要先提取人脸图片,在此基础上判断出各个人物的脸型、鼻型、眼型、唇形等五官。运用问题一所构建的模型和算法,对其进行人脸识别。关于人的五官特征比较,运用人脸五官位置黄金比例,和提取的五官位置比例比较,超出黄金值则为大,反正则为小。
2.3 问题三的分析
在问题一、二的基础上,识别出人脸,由于识别出的人脸并没有特征人物比较对象,需要通过建立训练集,将多个同种人物脸型做比较,建立人脸匹配模型,与待识别的人脸进行特征比较并预测匹配。
3.模型的假设与符号说明
3.1 模型的假设
(1)假设不存在长相完全一样的两个人
(2)假设人脸图像符合要求且真实有效,具有研究价值
(3)假设人脸图像的各项参数值在电脑的可运行范围之内。
3.2 符号说明
符号说明表

4.模型的准备
4.1 基于Adaboost算法的Haar强特征级联分类器
Haar特征是一种反映图像的灰度变化的,像素分模块求差值的一种特征。它分为三类:边缘特征、线性特征、中心特征和对角线特征。用黑白两种矩形框组合成特征模板,在特征模板内用黑色矩形像素和减去白色矩形像素和来表示这个模版的特征值。例如:脸部的一些特征能由矩形模块差值特征简单的描述,如:眼睛要比脸颊颜色要深,鼻梁两侧比鼻梁颜色要深,嘴巴比周围颜色要深等。但矩形特征只对一些简单的图形结构,如边缘、线段较敏感,所以只能描述在特定方向(水平、垂直、对角)上有明显像素模块梯度变化的图像结构如图1。
Haar特征像卷积的内核一样,每个特征是通过从黑色矩形下的像素之和减去白色矩形下的像素之和而获得的单个值。因此图片中的眼睛,鼻梁和嘴巴是我们的目标特征,也就是黑色区域,我们需要提取减去白色区域后的黑色区域。

图1 Haar特征区域
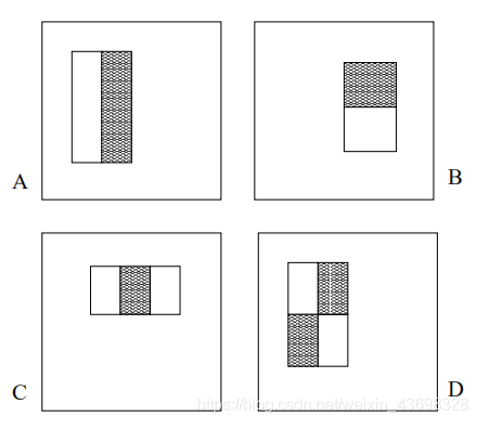
图2 图片中的Haar特征情况
对于图1中的A,B和E这类特征,特征数值计算公式为:S=∑▒S_白-∑▒S_黑,
而对于C,D,计算公式则是S=∑▒S_白-2*∑▒S_黑;
为了使两种矩形区域中像素数目一致,把黑色区域像素和乘2,我们希望当把矩形放到人脸区域计算出来的特征值和放到非人脸区域计算出来的特征值相差得越大越理想,因为这样可以用来区分人脸和非人脸两个区域。
4.2Adaboost算法的原理
Boosting, 也称为增强学习或提升法,是一种重要的集成学习技术,能够将预测精 度仅比随机猜度略高的弱学习器增强为预测精度高的强学习器,这在直接构造强学习器 非常困难的情况下,为学习算法的设计提供了一种有效的新思路和新方法。其中最为成 功应用的是,YoavFreund 和 RobertSchapire 在 1995 年提出的 AdaBoost 算法。 AdaBoost 是英文"AdaptiveBoosting"(自适应增强)的缩写,它的自适应在于:前 一个基本分类器被错误分类的样本的权值会增大,而正确分类的样本的权值会减小,并 再次用来训练下一个基本分类器。同时,在每一轮迭代中,加入一个新的弱分类器,直 到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数才确定最终的强分 类器。 其中每一个 stage 都代表一级强分类器。当检测窗口通过所有的强分类器时才被认 为是正样本(含人脸),否则拒绝。
实际上,不仅强分类器是树状结构,强分类器中的每一个弱分类器也是树状结构。 由于每一个强分类器对负样本(不含人脸)的判别准确度非常高,所以一旦发现检测到的 目标位负样本,就不在继续调用下面的强分类器,减少了很多的检测时间。因为一幅图 像中待检测的区域很多都是负样本,这样由级联分类器在分类器的初期就抛弃了很多负 样本的复杂检测,因此级联分类器的工作速度是非常快的;只有正样本才会送到下一个 强分类器进行再次检验,这样就保证了最后输出的正样本的伪正的可能性非常低。
5.模型的建立与求解
5.1 问题一的模型建立与求解
题目所给的图片包含了14个人脸,共12个身份。通过对这些图片进行初步分析可知, 每张图片中人脸的个数不唯一,面部特征有一定相似度,但又具备各自的特点,并且由 于拍摄角度,距离以及拍摄时的光线不同,不同图片中的同一个人的脸所在位置和大小 等特征都可能不同。所以人脸识别的第一步就是人脸检测和灰度化,即通过一系列预处 理,在输入图像中锁定人脸,并准确定位其位置和大小。 5.1.1 问题一模型的建立 5.1.1.1 基于 Adaboost 算法的 Haar 强级联分类器进行人脸识别框取 积分图用于计算 Haar 的特征值提取,它的主要的思想是将图像从起点开始到各个点 所形成的矩形区域像素之和作为一个数组的元素保存在内存中,当要计算某个区域的像 素和时可以直接索引数组的元素,不用重新计算这个区域的像素和,从而加快了计算(这 有个相应的称呼,叫做动态规划算法)。积分图能够在多种尺度下,使用相同的时间(常 数时间)来计算不同的特征。 积分图和 Haar 是两个独立的概念,本文采用积分图的方法加速计算 Haar 特征。积 分图是(Integral Image)类似动态规划的方法,主要的思想是将图像从起点开始到各个点 所形成的矩形区域像素之存在数组中,当要计算某个区域的像素和时可以直接从数组中 索引,不需要重新计算这个区域的像素和,从而加快了计算的速度。
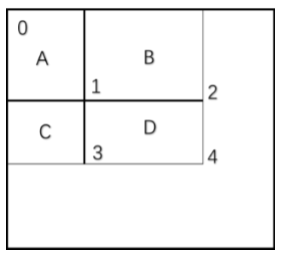
图 3
图4中有四个区域A,B,C,D我们将左上角的点记为0,区域A的所有点像素值的和记为〖sum〗_A,点0与1之间的积分图记为〖integral〗_0,1那么根据积分图的定义:
〖sum〗A=〖integral〗0,1
〖sum〗(A+B+C+D)=〖integral〗(0,A)
区域D的像素值和〖sum〗D就应该为〖integral〗(0,A),但是注意,自积分图中是没有从点1到点4的概念的,它所有的起点都应该是点0,所以:
〖sum〗_D=〖integral〗_1,4=〖integral〗_0,4-〖integral〗_0,2-〖integral〗0,3+〖integral〗0,1
转化一下就是如下等式
〖sum〗D=〖sum〗(A+B+C+D)-〖sum〗(A+B)-〖sum〗(A+C)+〖sum〗_A
上面的内容就是积分图,比如说我们要求〖sum〗_D,并不需要从点1到点4做行列的遍历,因为这个遍历过程的时间复杂度是O(mn)的。我们只需要在存在下来从0到点1,2,3,4的积分图,然后做一个简单的加减法就好了,这个时间复杂度仅仅为O(1)。当然了,存储的过程是消耗空间复杂度的,这是很典型的空间换时间的套路。这就是上面提到的积分图加速计算的过程。那么它和Haar有啥关系呢?本文积分图是在计算一个区域内所有点的像素值的和,Haar的特征提取过程也是这样。
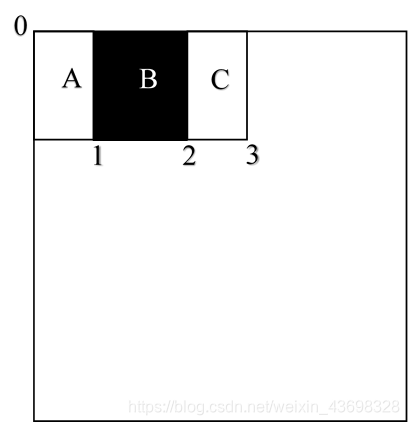
图 4
此时的 Haar 特征,它是区域 A+C 的像素值的和减去区域 B:
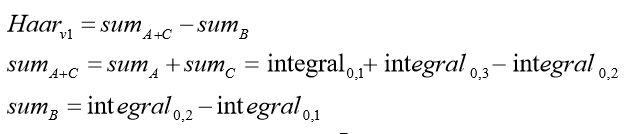
这样就计算出 Haar 的特征。
OpenCV 中的 Adaboost 级联分类器和弱分类器如图 5
图 5
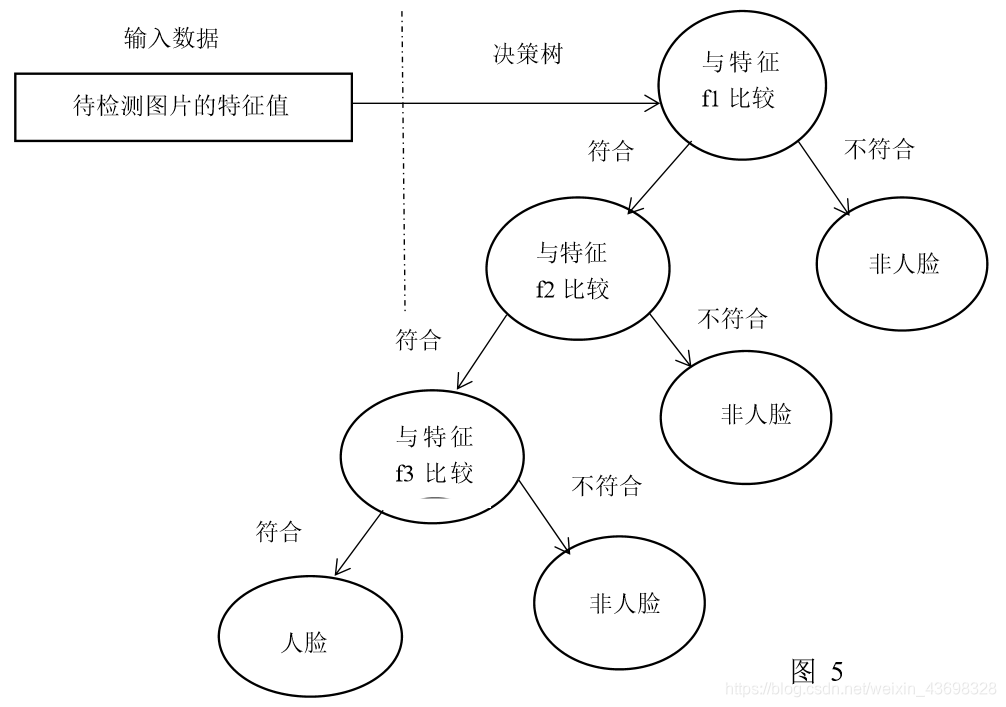
级联分类器的训练方法如下。首先需要训练出每一个弱分类器,然后把每个弱分类 器按照一定的组合策略,得到一个强分类器,我们训练出多个强分类器,然后按照级联 的方式把它们组合在一块,就会得到我们最终想要的 Haar 分类器。一个弱分类器就是 一个基本和上图类似的决策树,最基本的弱分类器只包含一个 Haar-like 特征,也就是它 的决策树只有一层,被称为树桩。以规格为 20*20 的图像为例,78,460 个特征,如果直 接利用 AdaBoost 训练,那么工作量是极其极其巨大的。所以必须有个筛选的过程,筛 选出T个优秀的特征值(即最优弱分类器),然后把这个T个最优弱分类器传给AdaBoost 进行训练。
5.1.1.2Haar 特征提取模型
基本的 Haar 最原始的 Haar-like 特征在 2002 年的《Ageneralframeworkforobject detection》提出,它定义了四个基本特征结构,如下 A,B,C,D 所示,可以将它们理 解成为一个窗口,这个窗口将在图像中做步长为 1 的滑动,最成比例地放大,再重复之 前的遍历的步骤,直到放大到最后一个比例后结束。 问题是如何确定可以放大的比例系数呢?设在宽终遍历整个图像.比较特殊的一点 是,当每一次遍历结束后,窗口将在宽度或长度上度上可以放大的最大倍数是KW,高度上可以放大的最大倍数是KH,KW计算公式如下:
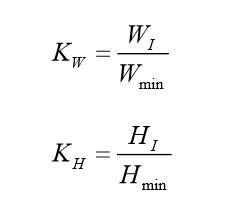
其中, WI 和 HI 是整个图像的宽高, W min 和 H min 是 Haar 窗口的初始宽高,可以放大的倍数是 KW*KH
5.1.1.3 基于 Adaboost 算法的特征比较决策树模型
AdaBoost 是英文"AdaptiveBoosting"(自适应增强)的缩写,它的自适应在于:前 一个基本分类器被错误分类的样本的权值会增大,而正确分类的样本的权值会减小,并 再次用来训练下一个基本分类器。同时,在每一轮迭代中,加入一个新的弱分类器,直 到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数才确定最终的强分 类器。具体说来,整个 Adaboost 迭代算法就 3 步: 1) 初始化训练数据的权值分布。如果有 N 个样本,则每一个训练样本最开始时都 被赋予相同的权值:1/N。 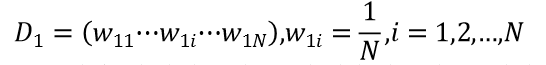
2 ) 训练弱分类器。使用具有权值分布具体训练过程中,如果某个样本点已经被准 确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个 样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样 本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
3) 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后, 加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决 定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起 着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较 大,否则较小。
5.1.2 问题一模型的求解
本文按照题目要求实现用矩形标出附件中的图一和图二的人脸的大致位置。 首先导入 OpenCV 计算机视觉识别库,读取图片再做灰度化处理,将灰度化处理的 图片传入 OpenCV 库中训练的 haarcascades_frontalface 人脸 Haar 特征分类器,处理成一 个 Haar 特征值积分图,将 Haar 特征值积分图通过基于 Adaboost 算法决策树的 Haar 特 征分类器,并返回脸部特征区域的值,在图片上建立坐标系,将脸部特征区域的值输入进坐标系,建立合适的矩形的长度和宽度来标记人脸的位置。
Step1 导入库 importcv2
Step2 加载图片,加载模型:待检测的图片路径,获取训练好的 Haar 脸部特征分类器的 参数数据:haarcascade_frontalface_alt2.xml,读取图片
Step3 对图片灰度化处理
Step4 调用 Haar 脸部特征分类器,设置分类器的参数,以及目标检测迭代次数(迭代次 数的不同会直接影响特征提取结果),来检测图片中的人脸特征
Step5 标记人脸,在原始图片的人脸上建立坐标,标出原点,标记人脸的高度,线的颜 色,线宽
Step6 显示图片
Step7 暂停窗口
Step8 销毁窗口
问题一代码见附录二代码
图 6 绿框表示识别结果


图 7 多个人脸的识别结果
5.2 问题二模型的建立与求解
5.2.1 基于问题一的 Haar 强级联分类模型的问题二求解
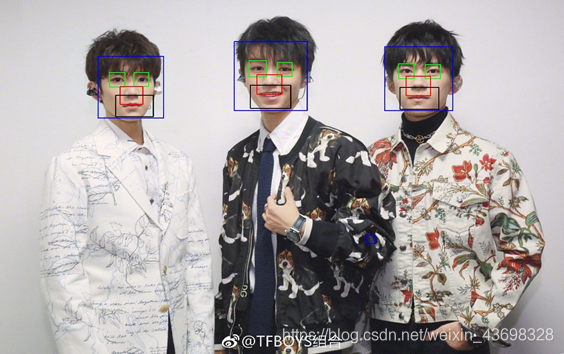
问题二是在问题一求解后的基础上,建立人脸精确识别模型。区别于问题一中只用 矩形标出图片中人脸的位置,问题二的目标是在输入的图像中不仅标出人脸的位置,还 能标出人的眼睛、嘴巴和鼻子。 问题二是在标记出人脸的位置的基础上继续寻找眼睛、鼻子和嘴巴的位置。 OpenCV 配有训练器和探测器。在级联分类器将处理检测。OpenCV 已包含许多预先训练的面部,眼睛,微笑等分类器。这些 XML 文件存储在 opencv/data/haarcascades/文件夹中。运行 时可用 OpenCV 导入面部和五官 Haar 特征分类器。首先,我们需要加载所需的 XML 分 类器和待检测的图像,然后灰度化以及一系列图像处理输入图像进特征分类器提取特 征,最后框出提取的特征区域。
5.2.2 基于问题一模型在问题二的补充
问题二应用的模型和问题一相同即前文的 5.1.1.2 Haar 特征提取模型和 5.1.1.3 基于 Adaboost 算法的特征比较决策树模型。问题二是基于问题一 Haar 脸部特征分类器 识别的脸部图片,进行进一步的 Haar 特征分类。例如眼睛 Haar 特征提取实现方式如图 9 所示。
而 OpenCV 中训练好的的 haarcascades 分类器文件内拥有对于眼睛,鼻子,嘴巴的 Haar 特征分类器,所以和问题一解决方法一致。
5.2.3 五官位置比例模型
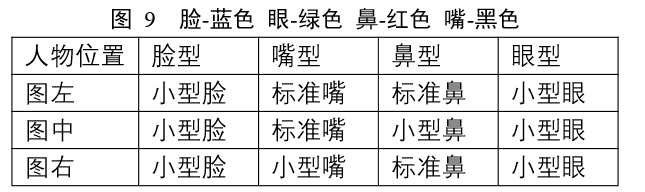
基于 Haar 特征分类器提取出的特征宽度,特征即人脸、眼睛、鼻子和嘴巴。本文 利用 Python 的 size 函数运行得出五官的数据。判断脸型的标准:通过计算眼睛、鼻子 和嘴巴的宽度和的比人脸的长度得到的比例大小,分类如下:
图 8 眼睛 Haar 特征提取实现方式
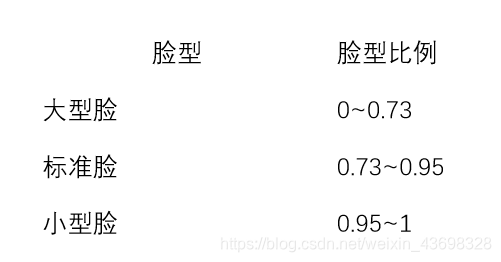
表 1
判断鼻型、嘴型、眼型的标准:分别用鼻子、嘴巴、眼睛的宽度除以脸宽度的比例 大小,分类如下:
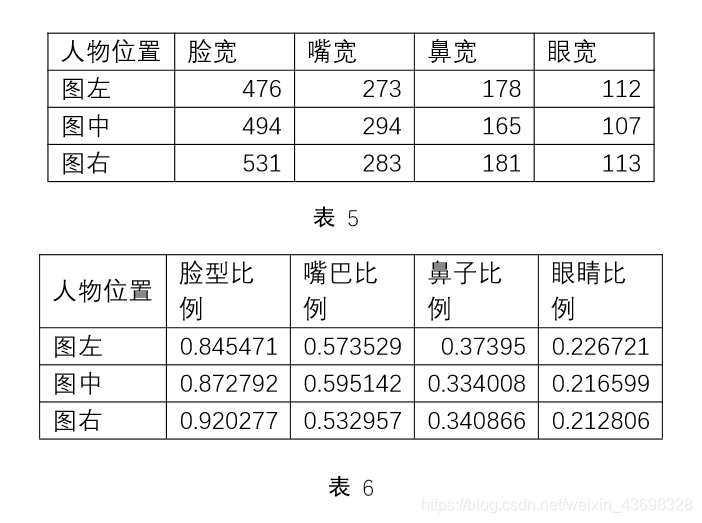
通过 python得到附件 2 中三个人的脸、鼻子、嘴巴、眼睛的宽度,进而通过鼻子、嘴巴、眼睛的宽度除以脸宽度的比例得到三个人的五官类型:
附件 2 中的三个人脸:

5.2.3 问题二模型的求解
算法步骤:
Step1 导入库 importcv2,获取训练好的人脸的参数数据
Step2 引入图片
Step3 读取图片
Step4 灰度化
Step5 (基于题一问题)调用 Haar 脸部特征分类器haarcascade_frontalface_alt2.xml,设 置分类器的参数,以及目标检测迭代次数(迭代次数的不同会直接影响特征提取结果), 来检测图片中的人脸特征。 Step6 在检测到的人脸特征图上继续调用 Haar 眼部特征分类器 haarcascade_eye.xml, Haar 鼻 部 特 征 分 类 器 haarcascade_mcs_nose.xml , Haar 嘴 部 特 征 分 类 器 haarcascade_mcs_mouth.xml,通过 xxx_cascade.detectMultiScale()函数实现五官特征值位 置提取。 (注:xx 特征分类器实现函数 xxx_cascade.detectMultiScale()函数内部参数设置:1.要检 测的输入图像,2.每次图像尺寸减小的比例,3.每一个目标至少要被检测到 3 次才算是 真的目标,4.要么使用默认值,要么使用 CV_HAAR_DO_CANNY_PRUNING,5.目标 的最小尺寸,6.目标的最大尺寸)
Step7 人脸提取并标注,在原始图片上分别以人脸、眼睛、鼻子和嘴巴作为坐标原点用 合适的矩形标出标记的高度
Step8 显示图片
Step9 暂停窗口
Step10 销毁窗口
第二题 Python 求解代码见附录二代码 2,
5.3 问题三的模型建立与求解
问题三的人脸匹配模型较复杂,需要从三张图片中找出相应的人脸,附录_图二和 图三中的人物较多,且从肉眼初步观测人脸的相似度较大,本文采取多种模型识别匹配 人脸的模型,通过匹配结果分析哪一种模型合适该题的求解。
5.3.1 问题三的模型建立
5.3.1.1 基于 KNN 的人脸识别模型
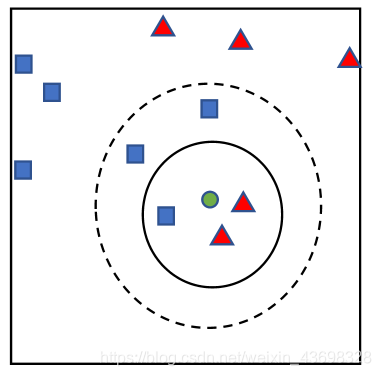
邻近算法,或者说 K 最近邻(KNN,k-NearestNeighbor)分类算法是数据挖掘分类技 术中最简单的方法之一。所谓 K 最近邻,就是 k 个最近的邻居的意思,说的是每个样本 都可以用它最接近的 k 个邻居来代表。Cover 和 Hart 在 1968 年提出了最初的邻近算法。 KNN 是一种分类算法,它输入基于实例的学习,属于懒惰学习即 KNN 没有显式的学习过程,也就是说没有训练阶段,数据集事先已有了分类和特征值,待收到新样本后直接 进行处理。与急切学习相对应。 KNN 是通过测量不同特征值之间的距离进行分类。思路是:如果一个样本在特征空 间中的 k 个最邻近的样本中的大多数属于某一个类别,则该样本也划分为这个类别。K NN 算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻 近的一个或者几个样本的类别来决定待分样本所属的类。如图 11 我们要确定绿点属于 哪个颜色(红色或者蓝色),要做的就是选出距离目标点距离最近的 k 个点,看这 k 个 点的大多数颜色是什么颜色。当 k 取 3 的时候,我们可以看出距离最近的三个,分别是 红色、红色、蓝色,因此得到目标点为红色。 KNN 算法的描述如下 :
图10
Step1 计算测试数据与各个训练数据之间的距离;
Step2 按照距离的递增关系进行排序;
Step3 选取距离最小的 K 个点;
Step4 确定前 K 个点所在类别的出现频率;
Step5 返回前 K 个点中出现频率最高的类别作为测试数据的预测分类。 K 是临近数,即在预测目标点时取几个临近的点来预测。 K 值的选取非常重要,原因如下: (1) 若当 K 的取值过小时,一旦有噪声得成分存在们将会对预测产生比较大影 响,例如取 K 值为 1 时,一旦最近的一个点是噪声,那么就会出现偏差, K 值的减小就意味着整体模型变得复杂,容易发生过拟合; (2) 若 K 的值取的过大时,就相当于用较大邻域中的训练实例进行预测,学习 的近似误差会增大。这时与输入目标点较远实例也会对预测起作用,使预 测发生错误。K 值的增大就意味着整体的模型变得简单; (3) 若 K==N 的时候,那么就是取全部的实例,即为取实例中某分类下最多的 点,就对预测没有实际的意义; (4) K 的取值尽量要取奇数,以保证在计算结果最后会产生一个较多的类别,如 果取偶数可能会产生相等的情况,不利于预测。
5.3.1.2 基于 SVM 的人脸识别模型
支持向量机(supportvectormachines)是一个二分类的分类模型(或者叫做分类器)。 如图 12。SVM 是二分类器,线性 SVM 分类是画出一条决策边界,使得到两个类样本 的最短距离最大。它分类的思想是,给定给一个包含正例和反例的样本集合,svm 的目的是寻找一个超平面来对样本根据正例和反例进行分割。
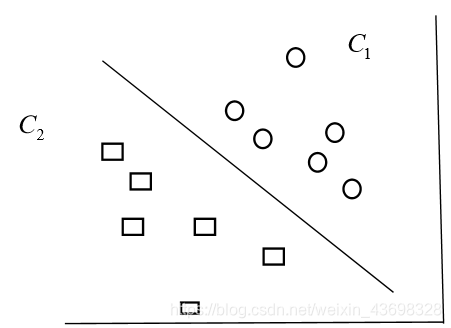
图 11 传统的支持向量机是通过对两类数据的学习寻找一个最优分类面,将两类数据无错 误地分开的同时还要使两类的分类间隔最大。而这里的人脸识别的数据库的类别为多类 问题,因此寻求有效的算法对传统支持向量机算法进行改进,使之能够对多类问题进行 分类。本文通过Python建立。
5.3.1.3 基于PCA的主成分分析法进行训练集降维
在人脸识别的科研领域里,如何能够有效地用低维提取和表示出人脸特征的信息一 直是研究的热点话题。而作为统计学方法的主成分分析法可以实现这样的功能,所以在 人脸识别领域发挥着重大的作用。 在计算机里每一张图像的存储方式是矩阵的形式,而为了构造人脸向量数据库以方 便求出平均脸和特征脸,则需将每一张图像对应的矩阵转换成列向量。设每张灰度图像 的行数为N, 列数为M,则灰度图像能够转换为一个NM 行,1 列的向量。从图片数据 库里选取L张图像,由这L 张图像的列向量组成一个nm 行,L 列的矩阵T。对矩阵T各 个列向量求取平均值得到m,m 也为NM 行,1列的向量。由均值m 可以还原回NM 的矩阵,从而做出平均人脸的图像。为了能够简单地展示平均人脸的效果,只随机选取 由在百度图片搜素的图片构成图像数据库中的若干张张图像,生成平均脸的该平均脸平 均综合反映了200 张人脸图像的信息,并不是普通意义下只针对一个人的人脸图像。 对一张图像进行特征信息提取,往往由于维数过高带来计算困难的难题。而PCA 能 够基于K-L 变换有效地实现对图像降维。经过查阅文献资料,将K-L 变换的原理简单 地阐述如下:在原图像的测量空间找出一组u 个正交矢量,要求这组正交矢量能最大程 度地反映出数据方差,然后将原图片模式矢量从w 维空间投影到这组正交矢量构成u维 子空间,则投影系数为构成原模式的特征矢量,由于要求u<w,所以PCA 能够实现维数 的压缩。
5.3.2 问题三模型的求解
Step1 下载训练集的3*50张图片放在三个带标签文件夹中
Step2 载入测试集,载入训练集和标签
Step3 进行图片预处理(大小统一,灰度化),通过PCA拟合并降维训练数据
Step4 利用人脸Haar分类器 haarcascade_frontalface_alt2 识别出人脸区域集合
Step5 提取人脸区域集合作为训练集,和测试集,训练集标签输入进SVM分类器
Step6 提取人脸区域集合作为训练集,和测试集,训练集标签输入进KNN分类器
Step7KNN分类器和SVM分类器返回预测标签值
Step8 根据预测标签值进行Step4分类后的脸部的框取以及标注
Step9 显示图片
Step10 关闭图片
第三题Python求解代码见附录二代码3
图 13 图二识别结果显示并标注标签
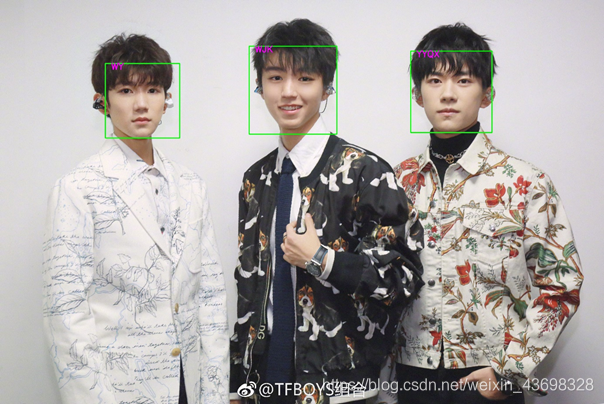
图 14 图三识别结果

6.模型结果的分析与检验
6.1 问题一
本题基于 Adaboost 算法将提取的 T 个 Haar 特征值进行决策树判断,进而实现人脸 识别。而 Haar 特征值提取时会有很多的误差,是可能识别出其他的图像噪声,对每一 个目标至少要被检测到 n 次,才能求出真的目标(因为周围的像素和不同的窗口大小都 可以检测到人脸),所以 Haar 特征值目标被检测的次数少会导致人脸识别结果少,而 Haar 特征值检测数设置太高会导致人脸识别结果偏大,合理的设置 Haar 特征值检测数 会减少结果误差。
6.2 问题二
本题通过分别对问题一检测到的每个人脸图片再次进行 Haar 五官特征分类,从问题 一中的人脸图片中框取五官。而五官的特殊性和图片大小以及框取人脸图片的像素清晰度,会导致识别的五官会有误差。
图 15 人数多图片像素低后识别的五官会有误差

6.3 问题三
6.3.1KNN 算法和 SVM 模型的比较
(1)knn 没有训练过程,他的基本原理就是找到训练数据集里面离需要预测的样本
点距离最近的 k 个值(距离可以使用比如欧式距离,k 的值需要自己调参),然后 把这 k 个点的 label 做个投票,选出一个 label 做为预测。对于 KNN,没有训练过程。 只是将训练数据与训练数据进行距离度量来实现分类。 SVM 需要超平面 wx+b 来分割数据集(此处以线性可分为例),因此会有一个 模型训练过程来找到 w 和 b 的值。训练完成之后就可以拿去预测了,根据函数 y=wx+b 的值来确定样本点 x 的 label,不需要再考虑训练集。对于 SVM,是先在训 练集上训练一个模型,然后用这个模型直接对测试集进行分类。
(2)根据上文第一条,KNN 和 SVM 两者效率差别极大。 KNN 没有训练过程,但是预测过程需要挨个计算每个训练样本和测试样本的距离, 当训练集和测试集很大时,预测效率感人。SVM 有一个训练过程,训练完直接得到 超平面函数,根据超平面函数直接判定预测点的 label,预测效率很高(一般我们更 关心预测效率)。 (3) 两者调参过程不一样。 KNN 只有一个参数 k,而 svm 的参数更多,在线性 不可分的情况下(这种情况更普遍),有松弛变量的系数,有具体的核函数。
7.模型的推广与改进方向
- 全文所有的人脸识别模型都是基于 Adaboost 算法决策树的 Haar 特征值分类器,该 模型和方法可以推广到人脸各个特征识别,甚至是其他的图片动物植物物体的特征 分类选区。
- SVM 和 KNN 是机器学习的简单特征分类器,可以用到机器学习的其他方面。
8.模型的优缺点
8.1 模型的优点 1. Haar 分类器速度快,效率比较高,可以在同一张图片上识别出多张人脸; 2. Adaboost 是一种有很高精度的分类器, 可以使用各种方法构建子分类器, 不 用做特征筛选。 3. KNN 算法简单且容易实现,比较适用于样本容量比较大的类域和类域的交 叉或重叠较多的待分样本集的自动分类 4. KNN 对于随机分布的数据集分类效果较差,对于类内间距小,类间间距大 的数据集分类效果好,而且对于边界不规则的数据效果好于线性分类器 8.2 模型的缺点
- 基于 Haar 如果图片中存在相似的两张脸,无法匹配正确的人脸
- 人脸在图片中有较大的倾斜度,无法标记并识别出人脸
- 当训练数据很大时,需要大量的存储空间,而且需要计算待测样本和训练数据 集中所有样本的距离,所以非常耗时。
- KNN 对于随机分布的数据集分类效果较差。
参考文献
[1] Paul Viola,Micheal Jones, Rapid Object Detection using a Boosted Cascade of SimpleFeatures,IEEE 会议论文,2001/06/15. [2] Papageorgiou, C.P., Oren, M, Poggio, T., A general framework for object detection,IEEE 会议论文,1998/06/15.
[3] CSDN,Adaboost 算法原理分析和实例+代码
原文链接:https://blog.csdn.net/guyuealian/article/details/70995333
2017/05/02.
[4] CSDN,Adaboost 算法的原理与推导 原文链接:https://blog.csdn.net/v_july_v/article/details/40718799 2014/11/02.
[5] CSDN,Haar-like 算法原理解析
原文链接:https://blog.csdn.net/qq_35860352/article/details/83827716
2018/11/07.
[6] JYRoy,KNN 算法:K 最近邻(KNN,K-NearestNeighbor)分类算法
原文链接:https://www.cnblogs.com/jyroy/p/9427977.html 2018/08/06.
10.附录
附录一 附件图片 附件_图一

附件_图二

附录二 识别结果演示
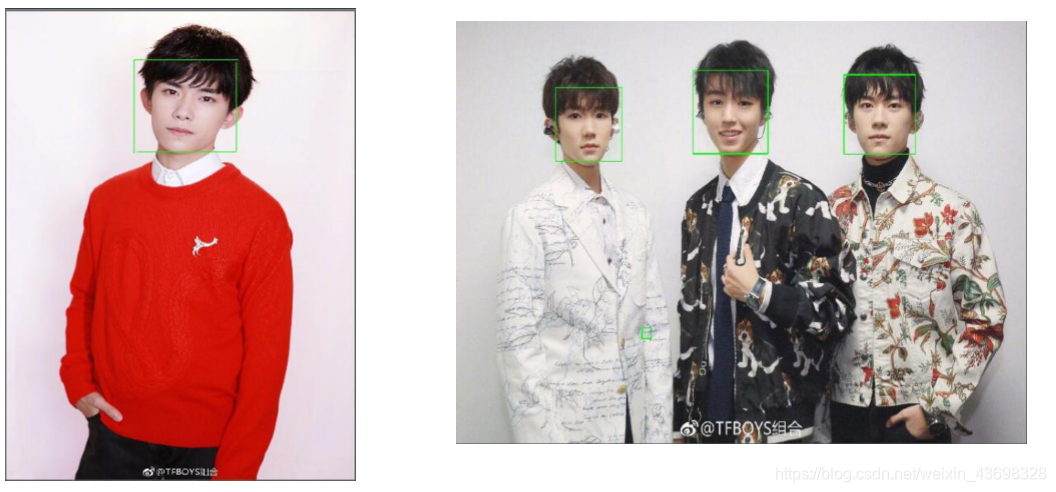
1.问题一:图一图二的识别结果
2.问题二:图二的识别结果
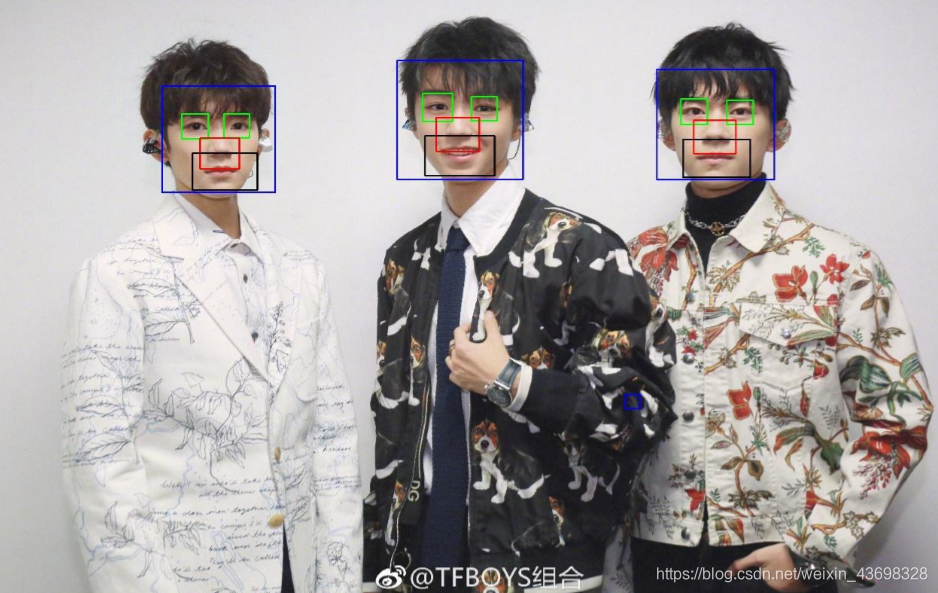
3.问题三:图二图三的识别结果
附录二 代码演示
代码 1 问题一代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: haotian time:2019/8/19
import cv2
from PIL import Image
import matplotlib.pyplot as plt
import sys
# 1.导入库
import cv2
# 2.加载图片,加载模型
# 待检测的图片路径
imagepath = r'./Trained_Face/pic3.jpg'
# 获取训练好的人脸的参数数据,这里直接使用默认值
pathf = r'./haarcascade_frontalface_alt2.xml'
face_cascade = cv2.CascadeClassifier(pathf)
# 读取图片
image = cv2.imread(imagepath)
# 3.对图片灰度化处理
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 4.检测人脸,探测图片中的人脸
faces = face_cascade.detectMultiScale(
gray,
scaleFactor=1.15,
minNeighbors=5,
minSize=(5, 5),
# flags=cv2.cv.CV_HAAR_SCALE_IMAGE
)
print("发现{0}个人脸!".format(len(faces)))
# 5.标记人脸
for (x, y, w, h) in faces:
# 1.原始图片 2.人脸坐标原点 3.标记的高度 4,线的颜色 5,线宽
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 5)
# 6.显示图片
cv2.imshow("Find Faces!", image)
cv2.imwrite('1.jpg',image)
# 7.暂停窗口
cv2.waitKey()
# 8.销毁窗口
cv2.destroyAllWindows()
代码 2 问题二代码 1.
# 1.导入库
import cv2
# 获取训练好的人脸的参数数据
face_cascade_path = ".\haarcascades\haarcascade_frontalface_alt2.xml"
face_cascade = cv2.CascadeClassifier(face_cascade_path)
eye_cascade_path = ".\haarcascades\haarcascade_eye.xml"
eye_cascade = cv2.CascadeClassifier(eye_cascade_path)
nose_cascade_path = ".\haarcascades\haarcascade_mcs_nose.xml"
nose_cascade = cv2.CascadeClassifier(nose_cascade_path)
mouth_cascade_path = ".\haarcascades\haarcascade_mcs_mouth.xml"
mouth_cascade = cv2.CascadeClassifier(mouth_cascade_path)
# 2.引入图片
input_image1_path = './Trained_Face/pic1.jpg'
input_image2_path = './Trained_Face/pic2.jpg'
input_image3_path = './Trained_Face/pic3.jpg'
# 3.读取图片
image = cv2.imread(input_image2_path)
# 4.灰度化
# 5.标记人脸
# xxx_cascade.detectMultiScale()
# 1.要检测的输入图像
# 2.每次图像尺寸减小的比例
# 3.每一个目标至少要被检测到3次才算是真的目标(因为周围的像素和不同的窗口大小都可以检测到人脸
# 4.要么使用默认值,要么使用CV_HAAR_DO_CANNY_PRUNING,如果设置为
# CV_HAAR_DO_CANNY_PRUNING,那么函数将会使用Canny边缘检测来排除边缘过多或过少的区域,因此这些区域通常不会是人脸所在区域;
# 5.目标的最小尺寸
# 6.目标的最大尺寸
faces = face_cascade.detectMultiScale(image,1.1,15,cv2.CASCADE_SCALE_IMAGE,(50,50))
print("发现{0}个人脸!".format(len(faces)))
count = 0
for (x, y, w, h) in faces:
print('第'+str(count+1)+'个人脸中心坐标' + ' x: '+str(x)+' y: '+str(y))
print('宽度: ' + str(w))
# # 1.原始图片 2.人脸坐标原点 3.标记的高度 4,线的颜色 5,线宽
cv2.rectangle(image, (x, y), (x + w, y + h), (255, 0, 0), 5,8,0)
# 人脸切割
roi_gray = image[y:y + h, x:x + w]
roi_color = image[y:y + h, x:x + w]
eyes = eye_cascade.detectMultiScale(roi_gray, 1.1, 5, cv2.CASCADE_SCALE_IMAGE, (100, 100))
num = 1
for (ex, ey, ew, eh) in eyes:
print('第' + str(num) + '个眼睛中心坐标'+' x: '+str(ex)+' y: '+str(ey))
# 1.原始图片 2.人脸坐标原点 3.标记的高度 4,线的颜色 5,线宽
cv2.rectangle(roi_color, (ex, ey), (ex + ew, ey + eh), (0, 255, 0), 5)
print('宽度: ' + str(ew) + ' 长度: ' + str(eh))
num = num+1
num=1
noses = nose_cascade.detectMultiScale(roi_gray, 1.1, 5, cv2.CASCADE_SCALE_IMAGE, (125, 125))
for (nx, ny, nw, nh) in noses:
print('第' + str(num) + '个鼻子中心坐标'+' x: '+str(nx)+' y: '+str(ny))
print('宽度: ' + str(nw) + ' 长度: ' + str(nh))
# 1.原始图片 2.人脸坐标原点 3.标记的高度 4,线的颜色 5,线宽
cv2.rectangle(roi_color, (nx, ny), (nx + nw, ny + nh), (0, 0, 255), 5)
num = num + 1
num = 1
mouths = mouth_cascade.detectMultiScale(roi_gray, 1.1, 5, cv2.CASCADE_SCALE_IMAGE, (150, 150))
for (mx, my, mw, mh) in mouths:
print('第' + str(num) + '个嘴巴中心坐标'+' x: '+str(mx)+' y: '+str(my))
print('宽度: ' + str(mw) + ' 长度: ' + str(mh))
# 1.原始图片 2.人脸坐标原点 3.标记的高度 4,线的颜色 5,线宽
cv2.rectangle(roi_color, (mx, my), (mx + mw, my + mh), (0, 0, 0), 5)
num = num + 1
print('
')
count = count+1
# 6.显示图片
cv2.imshow("Find Faces!", image)
cv2.imwrite('1.jpg',image)
# 7.暂停窗口
cv2.waitKey()
# 8.销毁窗口
cv2.destroyAllWindows()
代码 3 问题 3 的代码
import numpy as np
from sklearn.decomposition import PCA
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
import cv2
from PIL import Image
from imblearn.over_sampling import SMOTE
IMAGE_SIZE = 224
def LoadData(): #载入训练数据集
data = []
label = []
num = 20
path_cwd = "train/"
for j in range(1, 4):
path = path_cwd + 's' + str(j)
for number in range(num):
path_full = path + '/' + str(number) +'.png'
image = Image.open(path_full).convert('L')
image = image.resize((IMAGE_SIZE, IMAGE_SIZE), Image.ANTIALIAS)
img = np.reshape(image, (1, IMAGE_SIZE*IMAGE_SIZE))
data.extend(img)
label.extend(np.ones(num, dtype=np.int) * j)
data = np.reshape(data, (num*j, IMAGE_SIZE*IMAGE_SIZE))
return np.matrix(data), np.matrix(label).T #返回数据和标签
def svm(trainDataSimplified, trainLabel, testDataSimplified):
clf3 = SVC(C=0.001,gamma=25.0) # C为分类数目
# sm = SMOTE(random_state=42) # 处理过采样的方法
# trainDataSimplified, trainLabel = sm.fit_sample(trainDataSimplified, trainLabel.ravel())
clf3.fit(trainDataSimplified, trainLabel)
return clf3.predict(testDataSimplified)
def knn(neighbor, traindata, trainlabel, testdata):
neigh = KNeighborsClassifier(n_neighbors=neighbor)
# sm = SMOTE(random_state=42) # 处理过采样的方法
# traindata, trainlabel = sm.fit_sample(traindata, trainlabel.ravel())
neigh.fit(traindata, trainlabel)
return neigh.predict(testdata)
if __name__ == '__main__':
Data, Label = LoadData()
pca = PCA(0.9, True, True) # 建立pca类,设置参数,保留90%的数据方差
trainDataS = pca.fit_transform(Data) # 拟合并降维训练数据
#框住人脸的矩形边框颜色
color = (0, 255, 0)
#捕获指定摄像头的实时视频流
# cap = cv2.VideoCapture(0)
#人脸识别分类器本地存储路径
cascade_path = "./haarcascades/haarcascade_frontalface_alt.xml"
i=0
#循环检测识别人脸
while i==0:
frame = cv2.imread('./Trained_Face/pic2.jpg')
# frame_gray = frame
#图像灰化,降低计算复杂度
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
#使用人脸识别分类器,读入分类器
cascade = cv2.CascadeClassifier(cascade_path)
#利用分类器识别出哪个区域为人脸
faceRects = cascade.detectMultiScale(frame_gray, scaleFactor = 1.2, minNeighbors = 5, minSize = (32, 32))
if len(faceRects) > 0:
for faceRect in faceRects:
x, y, w, h = faceRect
#截取脸部图像提交给模型识别这是谁
m = frame_gray[y - 10: y + h + 10, x - 10: x + w + 10]
top, bottom, left, right = (0, 0, 0, 0)
image = m
# 获取图像尺寸
h, w = image.shape
# 对于长宽不相等的图片,找到最长的一边
longest_edge = max(h, w)
# 计算短边需要增加多上像素宽度使其与长边等长
if h < longest_edge:
dh = longest_edge - h
top = dh // 2
bottom = dh - top
elif w < longest_edge:
dw = longest_edge - w
left = dw // 2
right = dw - left
else:
pass
BLACK = [0]
# 给图像增加边界,是图片长、宽等长,cv2.BORDER_CONSTANT指定边界颜色由value指定
constant = cv2.copyMakeBorder(image, top, bottom, left, right, cv2.BORDER_CONSTANT, value=BLACK)
# 调整图像大小并返回
image = cv2.resize(constant, (IMAGE_SIZE, IMAGE_SIZE))
img_test = np.reshape(image, (1, IMAGE_SIZE * IMAGE_SIZE))
testDataS = pca.transform(img_test) # 降维测试数据
# result = svm(trainDataS, Label, testDataS) # 使用SVM进行分类
result = knn(31,trainDataS, Label, testDataS) # 使用KNN进行分类,5为最近邻居数
faceID = result[0]
#如果是“谁”
if faceID == 1:
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness = 5)
#文字提示是谁
cv2.putText(frame,'YYQX',
(x + 30, y + 30), #坐标
cv2.FONT_HERSHEY_SIMPLEX, #字体
2, #字号
(255,0,255), #颜色
5) #字的线宽
elif faceID == 2:
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness = 5)
#文字提示是谁
cv2.putText(frame,'WY',
(x + 30, y + 30), #坐标
cv2.FONT_HERSHEY_SIMPLEX, #字体
2, #字号
(255,0,255), #颜色
5)
elif faceID == 3:
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness = 5)
#文字提示是谁
cv2.putText(frame,'WJK',
(x + 30, y + 30), #坐标
cv2.FONT_HERSHEY_SIMPLEX, #字体
2, #字号
(255,0,255), #颜色
5)
else :
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness=2)
# 文字提示是谁
cv2.putText(frame, 'NONE',
(x + 30, y + 30), # 坐标
cv2.FONT_HERSHEY_SIMPLEX, # 字体
10, # 字号
(255, 0, 255), # 颜色
5)
i = 1
cv2.imwrite('1.jpg', frame)
cv2.imshow("find me", frame)
cv2.waitKey()
cv2.destroyAllWindows()