今天将Mybatis的执行器部分做一下简单手记。
一、java原生JDBC
众所周知,Mybatis是一个半自动化ORM框架。其实说白了,就是将java的rt.jar的JDBC操作进行了适度的封装。所以落到根本,肯定离不开JDBC的基本操作。我们来一起复习一下JDBC的基本操作。这里以java.sql.PreparedStatement为例。
1 public void jdbcTest() throws SQLException { 2 // 1、获取连接 3 connection = DriverManager.getConnection(URL, USERNAME, PASSWORD); 4 // 2、预编译 5 String sql = "SELECT * FROM users WHERE `name`=?"; 6 PreparedStatement sql1 = connection.prepareStatement(sql); 7 sql1.setString(1, "了了在小"); 8 // 3、执行SQL 9 sql1.execute(); 10 // 4、获取结果集 11 ResultSet resultSet = sql1.getResultSet(); 12 while (resultSet.next()) { 13 System.out.println(resultSet.getString(1)); 14 } 15 resultSet.close(); 16 sql1.close();; 17 }
其实、总结一下,原生JDBC操作流程如图:

其中,这里边的Connection、PreparedStatement、ResultSet这些API都是Java.sql包下约定的API。其中还有Statement、CallableStatement等API。不同的数据库驱动分别对其进行实现即可。本节既然讲执行器,这里简单罗列一下Java.sql包下所有的执行器接口定义:

如图,在java.sql给出的 JDBC执行器规范接口中,Statement作为顶级接口,PreparedStatement、CallableStatement分别是基于Statemtment的增强和扩展。这三个API各有侧重点。如图标识。
在使用层面:
Statement可以支持重用执行多个静态SQL,并可以设置addBatch、setFetchSize等操作。Statement的每次执行都是给数据库发送一个静态SQL。多次执行,即发送多个静态SQL。
PreparedStatement可以对SQL进行预编译,可以有效防止SQL注入(参数转义话在数据端执行,并非在Applicattion)。并且,每次执行都是给数据库发送一个SQL,加上若干组参数。
CallableStatement集成以上两个接口的基础上,扩展了返回结果的读写。
二、Mybatis执行体系
Mybatis作为封装JDBC操作的半自动框架,肯定也离不开JDBC的基本流程,以及java.sql给出的规范。如下以Mysql为例。列举一下Mybatis的简明流程。
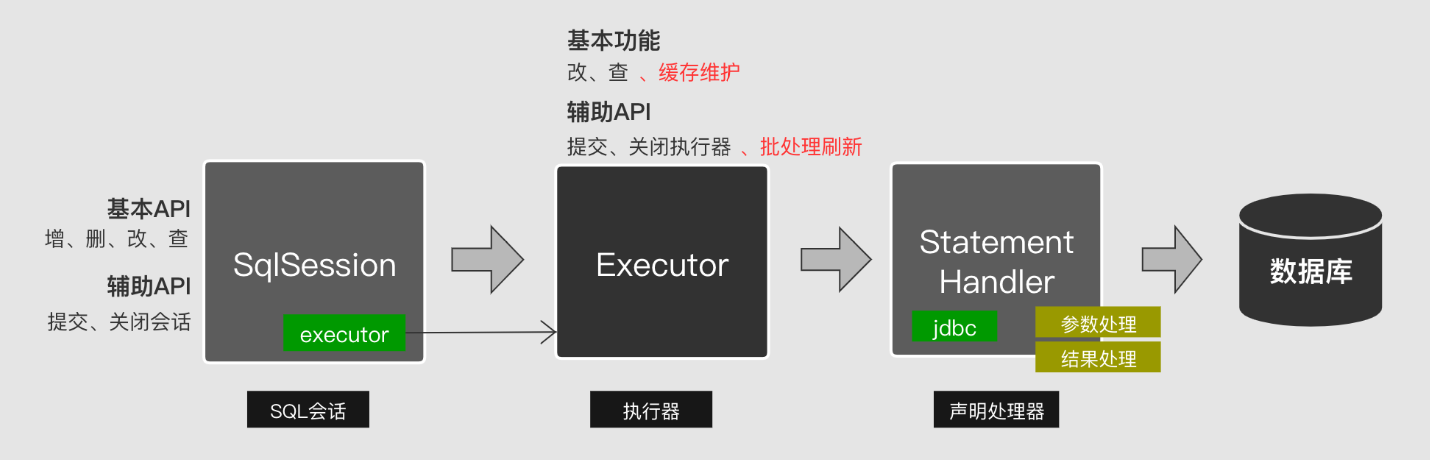
对照JDBC的标准流程,Mybatis将Connection对象维护交由SqlSession这个环节来处理,将SQL预编译与执行交给Executor这个环节来处理,将结果集提取交给StatemntHandler来处理。今天我们重点来看下Executor这个环节。
三、Mybatis执行器Executor
Executor接口作为Mybatis执行器的顶级接口,约定了修改(增删改)、查询、提交、回滚、缓存的基本规范。其实现的子类根据分工对其做个差异实现。类图如图:
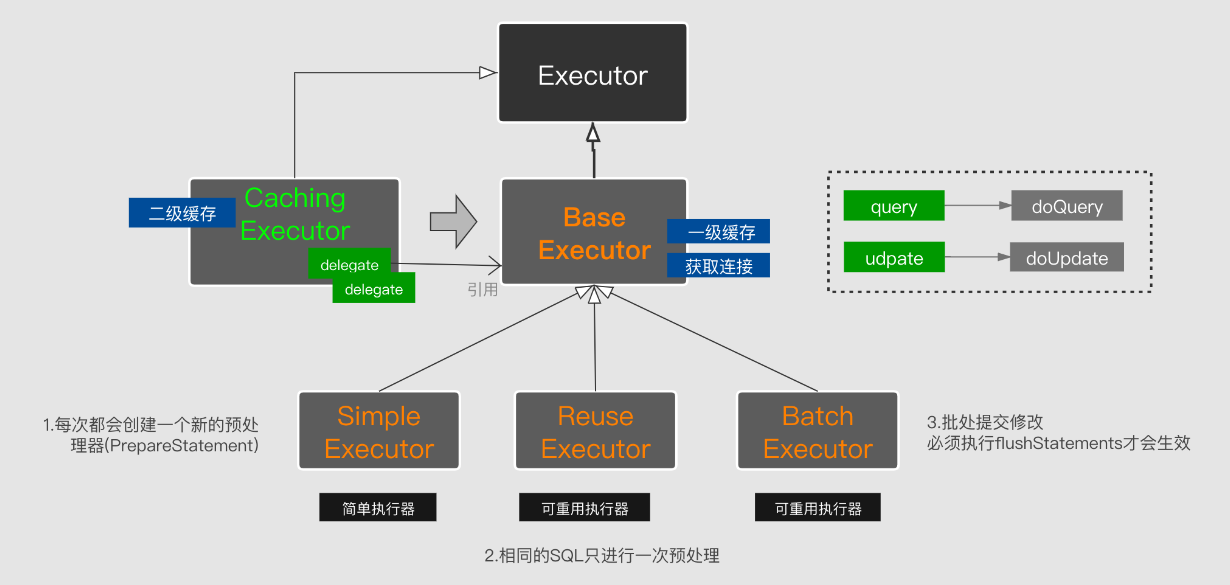
BaseExecutor:作为Executor的基本抽象实现,里边提取了连接维护、一级缓存的公有功能,供子类复用。并放出了doQuery、doUpdate的抽象方法下放到子类做差异实现。
CachingExecutor:作为BaseExecutor的一个装饰器,用来负责二级缓存功能。而JDBC相关操作都是丢给BaseExecutor来操作。
SimpleExecutor、ReuseExecutor、BatchExecutor:三个具体的实现均是实际操作JDBC的对象,可以通过Mapper接口注解(@Options(statementType=StatementType.STATEMENT))来指定Statement。里边默认使用PreparedStatement来处理JDBC操作,如图:
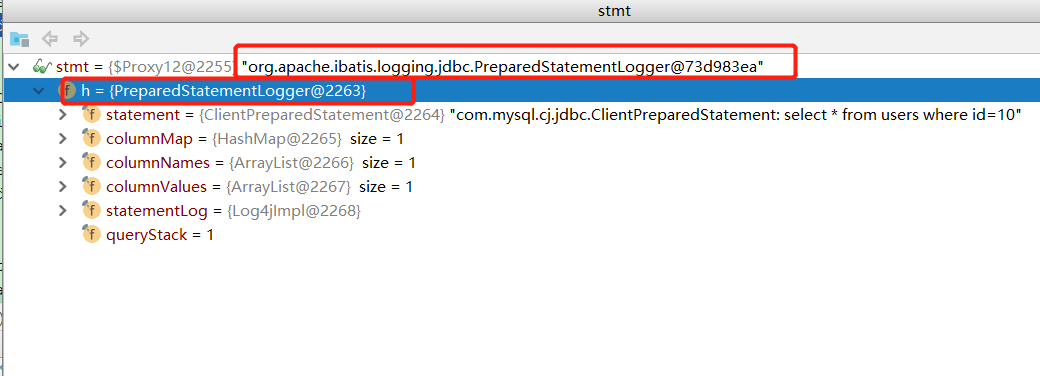
可以在mybatis-config.xml里边指定使用可重用执行器,默认为SimpleExecutor。
1 <settings> 2 <setting name="defaultExecutorType" value="REUSE"/> 3 </settings>
这里需要说明一下。Java的JDBC规范的执行器有三种:Statement、PreparedStatement、CallableStatement。而JDBC的执行器跟Mybatis的执行器不是一个概念。Mybatis的执行器有主要有三种,SimpleExecutor、ReuseExecutor、BatchExecutor。而且默认情况下,Mybatis的三种执行器都底层都调用PreparedStatement。可以通过Mapper接口方法增加参数来指定需要使用JDBC的哪种执行器(指定方式 ,见上一小节)。
四、可重用执行器ReuseExecutor
可重用执行器,其实底层就是维护了一个Map<String sql,Statement stmt> 来捕捉到相同的SQL,则直接取对应缓存的Statement进行执行,所以对于相同SQL(包括query、update),不同参数,则只进行一次预编译。就可以复用设置参数来执行。来,上源码:
1 public class ReuseExecutor extends BaseExecutor { 2 private final Map<String, Statement> statementMap = new HashMap(); 3 private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException { 4 BoundSql boundSql = handler.getBoundSql(); 5 String sql = boundSql.getSql(); 6 Statement stmt; 7 if (this.hasStatementFor(sql)) { 8 stmt = this.getStatement(sql); 9 this.applyTransactionTimeout(stmt); 10 } else { 11 Connection connection = this.getConnection(statementLog); 12 stmt = handler.prepare(connection, this.transaction.getTimeout()); 13 this.putStatement(sql, stmt); 14 } 15 16 handler.parameterize(stmt); 17 return stmt; 18 } 19 20 private boolean hasStatementFor(String sql) { 21 try { 22 return this.statementMap.keySet().contains(sql) && !((Statement)this.statementMap.get(sql)).getConnection().isClosed(); 23 } catch (SQLException var3) { 24 return false; 25 } 26 } 27 28 private Statement getStatement(String s) { 29 return (Statement)this.statementMap.get(s); 30 } 31 32 private void putStatement(String sql, Statement stmt) { 33 this.statementMap.put(sql, stmt); 34 } 35 }
可以看出,ReuseExecutor也维护了一个Statement的缓存,这是Mybatis里边除了一级缓存、二级缓存以外的又一处缓存。一般来说将执行器指定为ReuseExecutor,也是一种提升性能的方案。
五、批处理执行器BatchExecutor
批处理执行器,其实底层依赖的就是JDBC的Statement.addBatch接口规范。所以,BatchExecutor的使用必须是以addBatch开始,并以doFlushStatement结束。不同的是,BatchExecutor并不是单调的直接使用addBatch,而是对其扩展了缓存,复用的能力。上源码:
1 public class BatchExecutor extends BaseExecutor { 2 public static final int BATCH_UPDATE_RETURN_VALUE = -2147482646; 3 private final List<Statement> statementList = new ArrayList(); 4 private final List<BatchResult> batchResultList = new ArrayList(); 5 private String currentSql; 6 private MappedStatement currentStatement; 7 public BatchExecutor(Configuration configuration, Transaction transaction) { 8 super(configuration, transaction); 9 } 10 public int doUpdate(MappedStatement ms, Object parameterObject) throws SQLException { 11 Configuration configuration = ms.getConfiguration(); 12 StatementHandler handler = configuration.newStatementHandler(this, ms, parameterObject, RowBounds.DEFAULT, (ResultHandler)null, (BoundSql)null); 13 BoundSql boundSql = handler.getBoundSql(); 14 String sql = boundSql.getSql(); 15 Statement stmt; 16 if (sql.equals(this.currentSql) && ms.equals(this.currentStatement)) { 17 int last = this.statementList.size() - 1; 18 stmt = (Statement)this.statementList.get(last); 19 this.applyTransactionTimeout(stmt); 20 handler.parameterize(stmt); 21 BatchResult batchResult = (BatchResult)this.batchResultList.get(last); 22 batchResult.addParameterObject(parameterObject); 23 } else { 24 Connection connection = this.getConnection(ms.getStatementLog()); 25 stmt = handler.prepare(connection, this.transaction.getTimeout()); 26 handler.parameterize(stmt); 27 this.currentSql = sql; 28 this.currentStatement = ms; 29 this.statementList.add(stmt); 30 this.batchResultList.add(new BatchResult(ms, sql, parameterObject)); 31 } 32 handler.batch(stmt); 33 return -2147482646; 34 } 35 }
从源码可以看出,BatchExecutor维护了StatementList、batchResultList用来分别存放addBatch加入的Statement以及每个Statement执行后返回的结果集。另外每次执行一个Statement时都会去看上次执行的SQL(currentSql)与上次执行的Statement(currentStatement)能否复用,如果能复用就不在创建Statement,即省去了重复预编译过程。上一段测试代码:
1 public void sessionBatchTest(){ 2 SqlSession sqlSession = factory.openSession(ExecutorType.BATCH,true); 3 UserMapper mapper = sqlSession.getMapper(UserMapper.class); 4 mapper.setName(10,"道友友谊永存"); 5 User user = Mock.newUser(); 6 mapper.addUser(user); 7 mapper.addUser(user); 8 mapper.setName(user.getId(),"小鲁班"); 9 mapper.addUser(user); 10 List<BatchResult> batchResults = sqlSession.flushStatements(); 11 }
对于这段代码,通过源码分析,可以轻而易举的知道,batchResults.size()是4。这段测试用例,总共发起了5次调用,分别在第4、6、7、8、9行,其中第7行能复用第六行的Statement,所以第7行调用的时候就省去了预编译的步骤,而且将自己的结果集与第六行合并了。所以最终的结果集长度为4。这里如果将代码改成这样:
1 public void sessionBatchTest(){ 2 SqlSession sqlSession = factory.openSession(ExecutorType.BATCH,true); 3 User user = Mock.newUser(); 4 UserMapper mapper = sqlSession.getMapper(UserMapper.class); 5 mapper.setName(10,"道友友谊永存"); 6 mapper.setName(user.getId(),"小鲁班"); 7 mapper.addUser(user); 8 mapper.addUser(user); 9 mapper.addUser(user); 10 List<BatchResult> batchResults = sqlSession.flushStatements(); 11 }
那么,batchResult.size()就是2了,原因就不在赘述。这里简单总结一下:相同SQL && 相同Mapper && 连续执行 才能复用相同的JDBC Statement。
六、Executor执行器的线程安全问题
从ReuseExecutor、BatchExecutor的源码不难看出,里边涉及到大量JDBC的Statement缓存复用的逻辑,而且这些对象都是简单成员变量,并未做任何线程安全处理,所以Executor的操作是不可以跨线程的。Executor与SqlSession是一对一的关系,进而可以推导出,SqlSession也不能跨线程调用。但是一个线程是可以调用多个SqlSession、Executor的。
以上、感谢源码阅读网-鲁班大叔,以及Mybatis源码J10集团军所有道友。
源码地址:https://gitee.com/llzx/coderead_mybatis_executor.git