论文《TUPE》复现
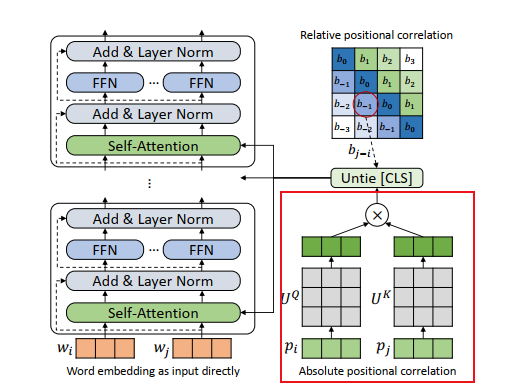
原有的注意力计算公式拆分为四部分后发现,中间两部分(word-to-position, position-to-word)对于识别并没有什么明显的作用,并且第一部分(word-to-word)和第四部分论文提出将位置信息与词嵌入信息分离开选择各自的权重矩阵来更新参数,提出的原因是由于将原有的注意力计算公式拆分为四部分后发现,中间两部分(word-to-position, position-to-word)对于识别并没有什么明显的作用,并且第一部分(word-to-word)和第四部分
论文提出将位置信息与词嵌入信息分离开选择各自的权重矩阵来更新参数,提出的原因是由于将原有的注意力计算公式拆分为四部分后发现,中间两部分(word-to-position, position-to-word)对于识别并没有什么明显的作用,并且第一部分(word-to-word)和第四部分
(position-to-position)选择的权重矩阵是相同的,但是位置信息与词嵌入信息应该代表不同的作用,应该选择不同的权重矩阵(position-to-position)选择的权重矩阵是相同的,但是位置信息与词嵌入信息应该代表不同的作用,应该选择不同的权重矩阵

因此,复现该论文需要引入新的参数,新的权重矩阵:
编码器 代码如下
点击查看代码
import torch.nn as nn
import torch
import numpy as np
from .attention import MultiHeadAttention #引进多头注意力模块
from .module import PositionalEncoding, PositionwiseFeedForward #位置编码和前馈网络
from .utils import get_non_pad_mask, get_attn_pad_mask #padding mask:填充补齐使得输入长度相同。attention mask:
class Encoder(nn.Module):
"""Encoder of Transformer including self-attention and feed forward.
"""
def __init__(self, d_input=320, n_layers=6, n_head=8, d_k=64, d_v=64,
d_model=512, d_inner=2048, dropout=0.1, pe_maxlen=5000):
super(Encoder, self).__init__()
# parameters
self.d_input = d_input #输入维度
self.n_layers = n_layers #编码解码层数
self.n_head = n_head #自注意力头数
self.d_k = d_k #键矩阵维度
self.d_v = d_v #值矩阵维度
self.d_model = d_model #模型维度
self.d_inner = d_inner #前馈网络隐层神经元个数(维度)
self.dropout_rate = dropout #信息漏失率
self.pe_maxlen = pe_maxlen #位置编码最大长度
# use linear transformation with layer norm to replace input embedding
self.linear_in = nn.Linear(d_input, d_model) #全连接,输入为320维 和输出512维
self.layer_norm_in = nn.LayerNorm(d_model) #层归一化
self.positional_encoding = PositionalEncoding(d_model, max_len=pe_maxlen) #位置编码
self.dropout = nn.Dropout(dropout) #dropout
self.w_pes1 = nn.Linear(d_model, n_head * d_v) #定义位置编码的权重矩阵
self.w_pes2 = nn.Linear(d_model, n_head * d_v)
nn.init.normal_(self.w_pes2.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_v))) #初始化权重
nn.init.normal_(self.w_pes1.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_v)))
self.layer_stack = nn.ModuleList([
EncoderLayer(d_model,d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
for _ in range(n_layers)]) #实现n_layers次编码器
#nn.ModuleList,它是一个储存不同 module,并自动将每个 module 的 parameters 添加到网络之中的容器。
def forward(self, padded_input, input_lengths, return_attns=False):
"""
Args:
padded_input: N x T x D
input_lengths: N
Returns:
enc_output: N x T x H
"""
enc_slf_attn_list = []
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
sz_b, len_v, _ = padded_input.size()
# Prepare masks
non_pad_mask = get_non_pad_mask(padded_input, input_lengths=input_lengths) #对输入数据填充
length = padded_input.size(1) #获得填充长度
slf_attn_mask = get_attn_pad_mask(padded_input, input_lengths, length) #注意力填充
# Forward
# 进入编码器前对数据的处理
# enc_output = self.dropout(
# self.layer_norm_in(self.linear_in(padded_input)) +
# self.positional_encoding(padded_input))
# 对数据线性变换(将320维的输入变为512维)后归一化,然后加上位置编码后的数据进行dropout
enc_output = self.dropout(self.layer_norm_in(self.linear_in(padded_input)))
pe = self.positional_encoding(padded_input)
pe1 = self.w_pes1(pe).view(sz_b, len_v, n_head, d_v)
pe2 = self.w_pes2(pe).view(sz_b, len_v, n_head, d_v)
pe1 = pe1.permute(2, 0, 1, 3).contiguous().view(-1, len_v, d_v)
pe2 = pe2.permute(2, 0, 1, 3).contiguous().view(-1, len_v, d_v)
pe = torch.bmm(pe1, pe2.transpose(1, 2))
for enc_layer in self.layer_stack: #进入编码器
enc_output, enc_slf_attn = enc_layer(
enc_output, pe,
non_pad_mask=non_pad_mask,
slf_attn_mask=slf_attn_mask)#经过编码器输出编码结果和注意力
if return_attns: #默认不对每层的注意力形成列表形式
enc_slf_attn_list += [enc_slf_attn]
if return_attns: #默认为false
return enc_output, enc_slf_attn_list
return enc_output, #返回最后层编码器输出
class EncoderLayer(nn.Module):
"""Compose with two sub-layers.
1. A multi-head self-attention mechanism
2. A simple, position-wise fully connected feed-forward network.
"""
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
super(EncoderLayer, self).__init__()
self.slf_attn = MultiHeadAttention(
n_head, d_model, d_k, d_v , dropout=dropout) #多头注意力实例化
self.pos_ffn = PositionwiseFeedForward(
d_model, d_inner, dropout=dropout) #前馈网络实例化
def forward(self, enc_input, pe,non_pad_mask=None, slf_attn_mask=None):
enc_output, enc_slf_attn = self.slf_attn(
enc_input, enc_input, enc_input, pe, mask=slf_attn_mask) #获得多头注意力的输出
enc_output *= non_pad_mask #防止经过注意力层后数据的长度发生变化
enc_output = self.pos_ffn(enc_output) #前馈网络的输出
enc_output *= non_pad_mask
return enc_output, enc_slf_attn #返回一个编码器的输出
多头注意力代码:
点击查看代码
import numpy as np
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
''' Multi-Head Attention module '''
def __init__(self, n_head, d_model, d_k, d_v , dropout=0.1):
super().__init__()
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
self.w_qs = nn.Linear(d_model, n_head * d_k) #输入512维,输出512维
self.w_ks = nn.Linear(d_model, n_head * d_k)
self.w_vs = nn.Linear(d_model, n_head * d_v)
nn.init.normal_(self.w_qs.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_k))) #权重初始化。mean=0:正态分布的均值;std:标准差
nn.init.normal_(self.w_ks.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_k)))#np.sqrt():开根号
nn.init.normal_(self.w_vs.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_v)))
self.attention = ScaledDotProductAttention(temperature=np.power(2 * d_k, 0.5),
attn_dropout=dropout) #np.power(a,b):a的b次方
self.layer_norm = nn.LayerNorm(d_model) #归一化
self.fc = nn.Linear(n_head * d_v, d_model) #线性变换,输入512维,输出512维
nn.init.xavier_normal_(self.fc.weight) #初始化线性变换的权重
self.dropout = nn.Dropout(dropout) #信息漏失率
def forward(self, q, k, v , pe , mask=None):
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
sz_b, len_q, _ = q.size() #获取查询矩阵的大小,长度
sz_b, len_k, _ = k.size()
sz_b, len_v, _ = v.size()
residual = q
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k) #重塑tensor的shape
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
#.permute():改变tensor维度;contiguous方法改变了多维数组在内存中的存储顺序,以便配合view方法使用
#torch.contiguous()方法首先拷贝了一份张量在内存中的地址,然后将地址按照形状改变后的张量的语义进行排列。
q = q.permute(2, 0, 1, 3).contiguous().view(-1, len_q, d_k) # (n*b) x lq x dk
k = k.permute(2, 0, 1, 3).contiguous().view(-1, len_k, d_k) # (n*b) x lk x dk
v = v.permute(2, 0, 1, 3).contiguous().view(-1, len_v, d_v) # (n*b) x lv x dv
if mask is not None:
mask = mask.repeat(n_head, 1, 1) # (n*b) x .. x ..
output, attn = self.attention(q, k, v, pe,mask=mask) #进入attention得到输出和注意力关系
output = output.view(n_head, sz_b, len_q, d_v) #对输出重塑
output = output.permute(1, 2, 0, 3).contiguous().view(sz_b, len_q, -1) # b x lq x (n*dv)
output = self.dropout(self.fc(output)) #输出进行线性变换和dropout
output = self.layer_norm(output + residual) #残差连接和归一化
return output, attn
class ScaledDotProductAttention(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
self.softmax = nn.Softmax(dim=2)
def forward(self, q, k, v, pe, mask=None):
# print(torch.bmm(q, k.transpose(1, 2)).size())
attn = torch.bmm(q, k.transpose(1, 2).cuda()) #得到q乘k的转置
attn = torch.add(attn, pe).cuda() #将位置信息与词嵌入信息相加
#三维矩阵相乘(QxK),.transpose()实现维度的转变,一维数据和二维数据互换位置,在这里是转置作用
attn = attn / (self.temperature) #QxK除以根号k的维度
if mask is not None:
attn = attn.masked_fill(mask.bool(), -np.inf) #-np.inf:负无穷的浮点数
attn = self.softmax(attn)
attn = self.dropout(attn)
output = torch.bmm(attn, v)
return output, attn
class MultiHeadAttention1(nn.Module): #decoder调用的attention类,未改变过的
''' Multi-Head Attention module '''
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
self.w_qs = nn.Linear(d_model, n_head * d_k)
self.w_ks = nn.Linear(d_model, n_head * d_k)
self.w_vs = nn.Linear(d_model, n_head * d_v)
nn.init.normal_(self.w_qs.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_k)))
nn.init.normal_(self.w_ks.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_k)))
nn.init.normal_(self.w_vs.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_v)))
self.attention = ScaledDotProductAttention1(temperature=np.power(d_k, 0.5),
attn_dropout=dropout)
self.layer_norm = nn.LayerNorm(d_model)
self.fc = nn.Linear(n_head * d_v, d_model)
nn.init.xavier_normal_(self.fc.weight)
self.dropout = nn.Dropout(dropout)
def forward(self, q, k, v, mask=None):
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
sz_b, len_q, _ = q.size()
sz_b, len_k, _ = k.size()
sz_b, len_v, _ = v.size()
residual = q
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
q = q.permute(2, 0, 1, 3).contiguous().view(-1, len_q, d_k) # (n*b) x lq x dk
k = k.permute(2, 0, 1, 3).contiguous().view(-1, len_k, d_k) # (n*b) x lk x dk
v = v.permute(2, 0, 1, 3).contiguous().view(-1, len_v, d_v) # (n*b) x lv x dv
if mask is not None:
mask = mask.repeat(n_head, 1, 1) # (n*b) x .. x ..
output, attn = self.attention(q, k, v, mask=mask)
output = output.view(n_head, sz_b, len_q, d_v)
output = output.permute(1, 2, 0, 3).contiguous().view(sz_b, len_q, -1) # b x lq x (n*dv)
output = self.dropout(self.fc(output))
output = self.layer_norm(output + residual)
return output, attn
class ScaledDotProductAttention1(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
self.softmax = nn.Softmax(dim=2)
def forward(self, q, k, v, mask=None):
attn = torch.bmm(q, k.transpose(1, 2))
attn = attn / self.temperature
torch.set_printoptions(profile="full")
if mask is not None:
attn = attn.masked_fill(mask.bool(), -np.inf)
# print(mask)
attn = self.softmax(attn)
attn = self.dropout(attn)
output = torch.bmm(attn, v)
return output, attn