信息论课程设计
算术编码的编码与译码:
要求:输入字符集为{a,b},且p(a)=1/4,p(b)=3/4.对长度L<=50的序列进行算术编码,并进行反向译码
输入文件:in1.txt,含至少两组输入,每组为满足要求的串
输出文件:out1.txt,对每组输入的编码和译码结果
问题分析和实现原理
编码原理
算数编码的原理我个人感觉其实并不太容易用三言两语直观地表达出来,其背后的数学思想则更是深刻。当然在这里我还是尽可能地将它表述,并着重结合例子来详细讲解它的原理。
简单来说,算数编码做了这样一件事情:
-
假设有一段数据需要编码,统计里面所有的字符和出现的次数。
-
将区间 [0,1) 连续划分成多个子区间,每个子区间代表一个上述字符, 区间的大小正比于这个字符在文中出现的概率 p。概率越大,则区间越大。所有的子区间加起来正好是 [0,1)。
-
编码从一个初始区间 [0,1) 开始,设置:
low=0, high=1 -
不断读入原始数据的字符,找到这个字符所在的区间,比如 [ L, H ),更新:
low=low+(high-low)*Lhigh=low+(high-low)*H
最后将得到的区间 [low, high)中任意一个小数以二进制形式输出即得到编码的数据。
乍一看这些数学和公式很难给人直观理解,所以我们还是看例子。例如有一段非常简单的原始数据:
ARBER
统计它们出现的次数和概率:
| Symbol | Times | P |
|---|---|---|
| A | 1 | 0.2 |
| B | 1 | 0.2 |
| E | 1 | 0.2 |
| R | 2 | 0.4 |
将这几个字符的区间在 [0,1) 上按照概率大小连续一字排开,我们得到一个划分好的 [0,1)区间:

开始编码,初始区间是 [0,1)。注意这里又用了区间这个词,不过这个区间不同于上面代表各个字符的概率区间 [0,1)。这里我们可以称之为编码区间,这个区间是会变化的,确切来说是不断变小。我们将编码过程用下图完整地表示出来:

拆解开来一步一步看:
-
刚开始编码区间是 [0,1),即
low=0high=1 -
第一个字符A的概率区间是 [0,0.2),则 L = 0,H = 0.2,更新
low=low+(high-low)*L=0high=low+(high-low)*H=0.2 -
第二个字符R的概率区间是 [0.6,1),则 L = 0.6,H = 1,更新
low=low+(high-low)*L=0.12high=low+(high-low)*H=0.2 -
第三个字符B的概率区间是 [0.2,0.4),则 L = 0.2,H = 0.4,更新
low=low+(high-low)*L=0.136high=low+(high-low)*H=0.152 -
......
上面的图已经非常清楚地展现了算数编码的思想,我们可以看到一个不断变化的小数编码区间。每次编码一个字符,就在现有的编码区间上,按照概率比例取出这个字符对应的子区间。例如一开始A落在0到0.2上,因此编码区间缩小为 [0,0.2),第二个字符是R,则在 [0,0.2)上按比例取出R对应的子区间 [0.12,0.2),以此类推。每次得到的新的区间都能精确无误地确定当前字符,并且保留了之前所有字符的信息,因为新的编码区间永远是在之前的子区间。最后我们会得到一个长长的小数,这个小数即神奇地包含了所有的原始数据,不得不说这真是一种非常精彩的思想。
解码
如果你理解了编码的原理,则解码的方法显而易见,就是编码过程的逆推。从编码得到的小数开始,不断地寻找小数落在了哪个概率区间,就能将原来的字符一个个地找出来。例如得到的小数是0.14432,则第一个字符显然是A,因为它落在了 [0,0.2)上,接下来再看0.14432落在了 [0,0.2)区间的哪一个相对子区间,发现是 [0.6,1), 就能找到第二个字符是R,依此类推。在这里就不赘述解码的具体步骤了。
编程实现
算数编码的原理简洁而又精致,理解起来也不很困难,但具体的编程实现其实并不是想象的那么容易,主要是因为小数的问题。虽然我们在讲解原理时非常容易地不断计算,但如果真的用编程实现,例如C++,并且不借助第三方数学库,我们不可能简单地用一个double类型去表示和计算这个小数,因为数据和编码可以任意长,小数也会到达小数点后成千上万位。
怎么办?其实也很容易,小数点是可以挪动的。给定一个编码区间,例如从上面例子里最后的区间 [0.14432,0.1456)开始,假定还有新的数据进来要继续编码。现有区间小数点后的高位0.14其实是确定的,那么实际上14已经可以输出了,小数点可以向后移动两位,区间变成 [0.432,0.56),在这个区间上继续计算后面的子区间。这样编码区间永远保持在一个有限的精度要求上。
上述是基于十进制的,实际数字是用二进制表示的,当然原理是一样的,用十进制只是为了表述方便。
算术编码是把一个信源表示为实轴上0和1之间的一个区间,信源集合中的每一个元素都用来缩短这个区间。
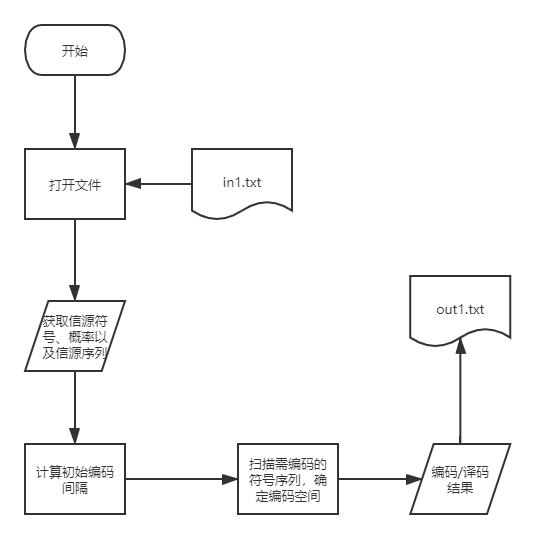
算法流程:
-
输入信源符号个数,信源概率分布,还有需要编码的符号序列。
-
根据概率可以算出初始编码间隔,
High--当前编码的上限,
Low--当前编码的下限,
high--中间变量,用来计算下一个编码符号的当前间隔的上限,
low--中间变量,用来计算下一个编码符号的当前间隔的下限,
d--当前间隔之间的距离。
-
扫描需编码的符号序列,确定编码空间
第1个编码符号的当前间隔为其初始的编码间隔,
第i个编码符号的当前间隔为第i-1个编码后的[Low, High),
第i+1个编码符号的当前间隔算法如下:
high=Low+d*第i+1个初始编码符号对应的上限,low=Low+d*第i+1个编码符号对应的下限,然后High=high, Low=low, d=d*第i个编码符号的概率。流程图
实现源码
#include<iostream>
#include<fstream>
#pragma warning(disable:4996)
using namespace std;
#include"math.h"
char S[100], A[10];//用户的码字与保存输入字符
float P[10], f[10], gFs;//字符概率
char bm[100], jm[100]; //保存码字
fstream in("in1.txt");
fstream out("out1.txt");
void bianma(int a, int h)//算术编码
{
int i, j;
float fr;
float ps = 1;
float Fs = 0;
float Sp[100];
for (i =0; i < h; i++)//以待编码的个数和字符个数为循环周期,将待编码的字符所对应的概率存入到Fs中
{
for (j = 0; j < a; j++)
{
if (S[i] == A[j])
{
Sp[i] = P[j];
fr = f[j];//将划分好的[0,1)区间的对应点赋值给fr
}
}
Fs = Fs + ps * fr;
ps *= Sp[i];
}
cout << "Fs=" << Fs << endl;
gFs = Fs;
out << "算术编码结果:" << endl;
out << "Fs=" << Fs << endl;
float l = log((float)1 / ps) / log((float)2);//计算算术编码的码字长度l
if (l > (int)l)l = (int)l + 1;
else l = int(l);//将Fs转换成二进制形式
int d[20];
int m = 0;
while (l > m)
{
Fs = 2 * Fs;
if (Fs > 1)
{
Fs = Fs - 1;
d[m] = 1;
}
else if (Fs < 1)d[m] = 0;
else { d[m] = 1; break; }
m++;
}
int z = m;
if (m >= l)//解决有关算术编码的进位问题
{
while (1)
{
d[m - 1] = ( d[m - 1] + 1 ) % 2;
if (d[m - 1] == 1)break;
else m--;
}
}
cout << "s=";
out << "s=";
for (int e = 0; e < z; e++)
{
cout << d[e];
out << d[e];
}
cout << endl;
out << endl;
}
void jiema(int a,int h)//算术译码
{
int i;
float Ft, Pt;
float Fs = 0, Ps = 1;
out << "算术译码后:";
for (i = 0; i < h; i++)//以编码个数和符号个数为循环周期进行解码
{
for (int j = a - 1; j > -1; j--)
{
Ft = Fs;
Pt = Ps;
Ft += Pt * f[j];//对其进行逆编码
Pt *= P[j];
if (gFs >= Ft)//对其进行判断并将值存入到数组A中
{
Fs = Ft;
Ps = Pt;
cout << A[j];
out << A[j];
break;
}
}
}
cout << endl;
out << endl;
}
void main()
{
cout << "编码个数";
int a, i, h = 0;
in >> a;
cout << a << endl;
cout << "输入编码符号和概率值" << endl;
for (i = 0; i < a; i++)
{
char x;
float y;
in >> x;
cout << x;
A[i] = x;
in >> y;
cout << y << endl;
P[i] = y;
}
for (i = 1; i < a; i++)
{
f[0] = 0;
f[i] = f[i - 1] + P[i - 1];//将要编码的数据映射到一个位于[0,1)的实数区间中
}
while (!in.eof())
{
cout << "输入需要编码的符号序列,同时用$结尾" << endl;
h = 0;
while (1)//将要编码的字符存入到数组S中
{
char cc;
in >> cc;
if (cc == '$')
break;//在以“$”为结尾的时候结束存储
S[h++] = cc;
cout << cc;
}
cout << endl;
cout << "算术编码结果:" << endl;
bianma(a, h);
cout << "对应的解码结果:" << endl;
jiema(a, h);
system("pause");
}
in.close();
out.close();
}
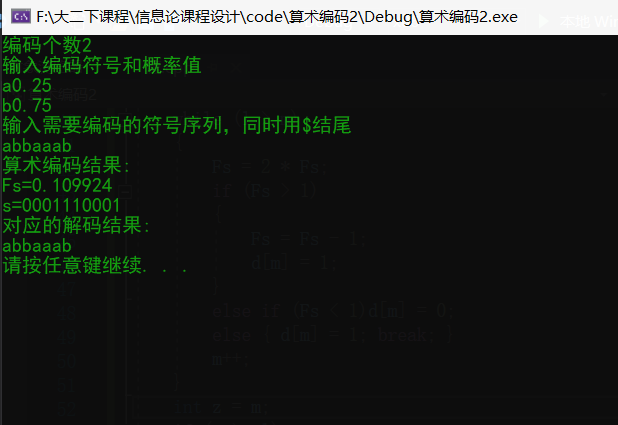
运行结果
终端运行界面
文件夹中的in1.txt和out1.txt


设计体会
通过本次实验,学会了算术编码技基本流程,基本能够调试算术编码程序。对信息论相关知识有了进一步的了解。同时提高了自己解决问题的能力,对编程能力也有很大的提高。
判定唯一可译码:
输入:任意的一个码(即已知码字个数及每个具体的码字)
输出:判决结果(是/不是)
输入文件:in4.txt,含至少2组码,每组的结尾为”$”符
输出文件:out4.txt,对每组码的判断结果
说明:为了简化设计,可以假定码字为0,1串
问题分析和实现原理
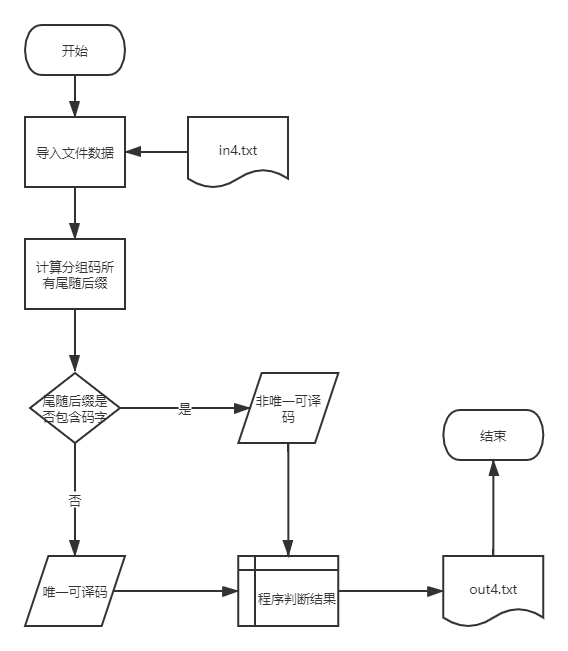
根据萨德纳斯和彼特森设计判断唯一可以码的算法思想,设计算法,判断一个码是否为唯一可译码
判断标准:
将码所有可能的未遂后缀组成一个集合,当且仅当集合中没有包含任意码字时,码为唯一可译码。
实验原理
1、考查C中所有的码字,若Wi是Wj的前缀,则将相应的后缀作为一个尾随后缀码放入集合F0中;
2、考察C和Fi两个集合,若Wi∈C是Wi∈Fi的前缀或Wi∈Fi是Wj∈C的前缀,则将相应的后缀作为尾随后缀码放入集合Fi+1中;
3、F= $ cup $ Fi即为码C的尾随后缀集合;
4、若F中出现了C中的元素,算法终止,返回假(C不是唯一可译码);否则若F中没有出现新的元素,则返回真。
流程图
实现源码
#include<iostream>
#include<fstream>
#include<stdio.h>
#include<string.h>
using namespace std;
#pragma warning(disable:4996)
char c[100][50];//保存码字
char f[300][50];//保存尾随后缀
int N, sum = 0;//分别为码字的个数和尾随后缀个数
int flag;//判断是否为唯一可译码
void patterson(char c[], char d[])//检测尾随后缀
{
int i, j, k;
for (i = 0;; i++)
{
if (c[i] == '�'&&d[i] == '�')//两字符串长度相同
break;
if (c[i] == '�')//d比c长,将d的尾随后缀放入到f中
{
for (j = i; d[j] != '�'; j++)
f[sum][j - i] = d[j];
f[sum][j - i] = '�';
for (k = 0; k < sum; k++)
{
if (strcmp(f[sum], f[k]) == 0)//查看当前生成的尾随后缀在f集合中是否存在
{
sum--;
break;
}
}
sum++;
break;
}
if (d[i] == '�')//c比d长,将c的尾随后缀放入f中
{
for (j = i; c[j] != '�'; j++)
f[sum][j - i] = c[j];
f[sum][j - i] = '�';
for (k = 0; k < sum; k++)
{
if (strcmp(f[sum], f[k]) == 0)//查看当前生成的尾随后缀在f集合中是否存在
{
sum--;
break;
}
}
sum++;
break;
}
if (c[i] != d[i])
break;
}
}
void main()
{
int k = 0, N = 0, m = 0, a[50], z = 0;
a[m] = N; m++;
fstream file1;
file1.open("out4.txt");
FILE *file;
file = fopen("in4.txt", "r+");//读取码字
int num = fgetc(file) - 48;
for (int n = 0; n < num; n++)
{
int i = 0, j;
if (fgetc(file) == ' ')
N += (fgetc(file) - 48);
else
N += (fgetc(file) - 48);
a[m] = N; m++;
fgetc(file);
for (k; k < N; k++)
{
for (int q = 0;; q++)
{
char temp = fgetc(file);
c[k][q] = temp;
if (temp == ' ' || temp == '$')
{
c[k][q] = '�';
break;
}
}
}
flag = 0;
for (i = a[z]; i < N - 1; i++)//判断码本身是否重复
for (j = i + 1; j < N; j++)
{
if (strcmp(c[i], c[j]) == 0)
{
flag = 1; break;
}
}
if (flag == 1)//如果码本身存在重复,即可断定其不是唯一可译码
{
for (int y = a[z]; y < N; y++)
file1 << c[y] << ' ';
file1 << "不是唯一可译码
";
}
else {
for (i = a[z]; i < N - 1; i++)//将原始码字生成的尾随后缀集合s[1]放入f中
{
for (j = i + 1; j < N; j++)
{
patterson(c[i], c[j]);
}
}
for (i = 0;; i++)//根据原始码与s[i]生成s[i+1]也放入f[i]
{
int s = 0;
for (j = a[z]; j < N; j++)//判断s[i+1]中的字符串是否与s[i]中一样,重复则不再添加
{
if (i == sum)
{
s = 1; break;
}
else
patterson(f[i], c[j]);
}
if (s == 1)
break;
}
for (i = 0; i < sum; i++)//判断尾随后缀与原始码字是否相同,相同则不是唯一可译码
{
for (j = a[z]; j < N; j++)
{
if (strcmp(f[i], c[j]) == 0)
{
flag = 1;
break;
}
}
}
if (flag == 1)
{
for (int y = a[z]; y < N; y++)
file1 << c[y] << ' ';
file1 << "不是唯一可译码
";
}
else {
for (int y = a[z]; y < N; y++)
file1 << c[y] << ' ';
file1 << "是唯一可译码
";
}
}
file1 << "尾随后缀集合为:";
for (i = 0; i < sum; i++)
file1 << f[i] << ' ';
file1 << "
";
z++;
sum = 0;
}
}
运行结果



设计体会
通过对判定唯一可译码算法的实现,我进一步了解了判定唯一可译码缩的基本原理及过程,体会到了其重要性,同时也锻炼了我独立分析问题以及解决问题的能力,这次课程设计让我深刻认识到了自己编程能力的不足,在以后的学习中要加强自己的编程能力的提高。
综合编码:
游程编码+Huffman编码+加密编码+信道编码及对应的译码(L-D+Huffman编码+加密编码+信道编码及对应的译码)
一个二元无记忆信源,0符号的出现概率为1/4, 1符号的出现概率为3/4。
现要求对该信源连续出现的n个符号序列,进行游程编码/对游程编码结果进行Huffman编码/使用加密算法进行加密/进行信道编码;
然后模拟信道的传输过程,并对收到的信息串进行信道译码/解密译码/Huffman译码/游程译码。
假定,连续出现的0或1序列的长度不超过16,n不小于256。
其中加密编码/解密译码可自主选择对称加密算法或非对称算法;
信道编码要求采用(7,4)系统循环码,其中,g(x)= (X^3)+(x)+1,译码采用简化的译码表;
信道为BSC信道,p=(10^{-6})
输入:
长为n的0/1串
输出:
游程编码结果,
Huffman编码结果,
加密编码结果
信道编码结果
模拟接收串,
信道译码结果,
解密编码结果 ,
Huffman译码结果
游程译码结果
输入文件:in5.txt,含至少两组输入
输出文件:out5.txt,对每组输入的处理结果
问题分析和实现原理
游程编码
-
游程编码是一种比较简单的压缩算法,其基本思想是将重复且连续出现多次的字符使用(连续出现次数,某个字符)来描述。
比如一个字符串:
AAAAABBBBCCC使用游程编码可以将其描述为:
5A4B3C5A表示这个地方有5个连续的A,同理4B表示有4个连续的B,3C表示有3个连续的C,其它情况以此类推。
在对图像数据进行编码时,沿一定方向排列的具有相同灰度值的像素可看成是连续符号,用字串代替这些连续符号,可大幅度减少数据量。
游程编码记录方式有两种:①逐行记录每个游程的终点列号:②逐行记录每个游程的长度(像元数)
Huffman编码
-
霍夫曼编码是一种无损的统计编码方法,利用信息符号概率分布特性来改编字长进行编码。适用于多元独立信源。霍夫曼编码对于出现概率大的信息符号用字长小的符号表示,对于出现概率小的信息用字长大的符号代替。如果码字长严格按照所对应符号出现的概率大小逆序排列,则编码结果的平均字长一定小于其他排列形式。
霍夫曼编码的具体步骤如下:
1)将信源符号的概率按减小的顺序排队。
2)把两个最小的概率相加,并继续这一步骤,始终将较高的概率分支放在右边,直到最后变成概率。
3)画出由概率1处到每个信源符号的路径,顺序记下沿路径的0和1,所得就是该符号的霍夫曼码字。
4)将每对组合的左边一个指定为0,右边一个指定为1(或相反)。
对称加密
对称加密算法 是应用较早的加密算法,又称为 共享密钥加密算法。在 对称加密算法 中,使用的密钥只有一个,发送 和 接收 双方都使用这个密钥对数据进行 加密 和 解密。这就要求加密和解密方事先都必须知道加密的密钥。
数据加密过程:在对称加密算法中,数据发送方 将 明文 (原始数据) 和 加密密钥 一起经过特殊 加密处理,生成复杂的 加密密文 进行发送。
数据解密过程:数据接收方 收到密文后,若想读取原数据,则需要使用 加密使用的密钥 及相同算法的 逆算法 对加密的密文进行解密,才能使其恢复成 可读明文。
信道编码
编码过程
在编码时,首先需要根据给定循环码的参数确定生成多项式g(x),也就是从F(x)的因子中选一个(n-k)次多项式作为g(x);然后,利用循环码的编码特点,即所有循环码多项式A(x)都可以被g(x)整除,来定义生成多项式g(x)。
据上述原理可以得到一个较简单的系统:设要产生(n,k)循环码,m(x)表示信息多项式,循环码编码方法,则其次数必小于k,而m(x)的次数必小于n,用m(x)除以g(x),可得余数r(x),r(x)的次数必小于(n-k),将r(x)加到信息位后作监督位,就得到了系统循环码。下面就将以上各步处理加以解释。
(1)用x的乘m(x)。这一运算实际上是把信息码后附加上(n-k)个“0”。例如,信息码为110,而希望的到得系统循环码多项式应当是A(x) = (x^n)·m(x) + r(x)。
(2)求r(x)。由于循环码多项式A(x)都可以被g(x)整除,因此,用·m(x)除以g(x),就得到商Q(x)和余式r(x),这样就得到了r(x)。
(3)编码输出系统循环码多项式A(x)为:这时的编码输出为:1100101。
上述三步编码过程,在硬件实现时,可以利用除法电路来实现,这里的除法电路采用一些移位寄存器和模2加法器来构成。下面将以(7,4)循环码为例,来说明其具体实现过程。设该(7,4)循环码的生成多项式为:g(x)= (x^3)+(x)+1,则构成的系统循环码编码器如图8-6所示,图中有4个移位寄存器,一个双刀双掷开关。 当信息位输入时,开关位置接“2”,输入的信息码一方面送到除法器进行运算,一方面直接输出;当信息位全部输出后,开关位置接“1”,这时输出端接到移位寄存器的输出,这时除法的余项,也就是监督位依次输出。
顺便指出,由于数字信号处理器(DSP)和大规模可编程逻辑器件(CPLD和FPGA)的广泛应用,目前已多采用这些先进器件和相应的软件来实现上述编码。译码过程
对于接收端译码的要求通常有两个:检错与纠错。达到检错目的的译码十分简单通过判断接收到的码组多项式B(x)是否能被生成多项式g(x)整除作为依据。当传输中未发生错误时,也就是接收的码组与发送的码组相同,即A(x)=B(x),则接收的码组B(x)必能被g(x)整除;若传输中发生了错误,则A(x)≠B(x),B(x)不能被g(x)整除。因此,可以根据余项是否为零来判断码组中有无错码。
需要指出的是,有错码的接收码组也有可能被g(x)整除,这时的错码就不能检出了。这种错误被称为不可检错误,不可检错误中的错码数必将超过这种编码的检错能力。
在接收端为纠错而采用的译码方法自然比检错要复杂许多,因此,对纠错码的研究大都集中在译码算法上。
我们知道,校正子与错误图样之间存在某种对应关系。如同其它线性分组码,循环编码和译码可以分三步进行:(1)由接收到的码多项式B(x)计算校正子(伴随式)多项式S(x);
(2)由校正子S(x)确定错误图样E(x);
(3)将错误图样E(x)与B(x)相加,纠正错误。
上述第(1)步运算和检错译码类似,也就是求解B(x)整除g(x)的余式,第(3)步也很简单。因此,纠错码译码器的复杂性主要取决于译码过程的第(2)步。
基于错误图样识别的译码器称为梅吉特译码器,它的原理图如图8-7所示。错误图样识别器是一个具有(n-k)个输入端的逻辑电路,原则上可以采用查表的方法,根据校正子找到错误图样,利用循环码的上述特性可以简化识别电路。梅吉特译码器特别适合于纠正2个以下的随机独立错误。
k级缓存器用于存储系统循环码的信息码元,模2加电路用于纠正错误。当校正子为0时,模2加来自错误图样识别电路的输入端为0,输出缓存器的内容;当校正子不为0时,模2加来自错误图样识别电路的输入端在第i位输出为1,它可以使缓存器输出取补,即纠正错误。
循环码的译码方法除了梅吉特译码器以外,还有补错编译码、大数逻辑编译码等方法。捕错译码是梅吉特译码的一种变形,也可以用较简单的组合逻辑电路实现,它特别适合于纠正突发错误、单个随机错误和两个错误的码字。大数
逻辑译码也称为门限译码,这种译码方法也很简单,但它只能用于有一定结构的为数不多的大数逻辑可译码,虽然在一般情形下,大数逻辑可译码的纠错能力和编码效率比有相同参数的其它循环码(如BCH码)稍差,但它的译码算法和硬件比较简单,因此在实际中有较广泛的应用。
流程图
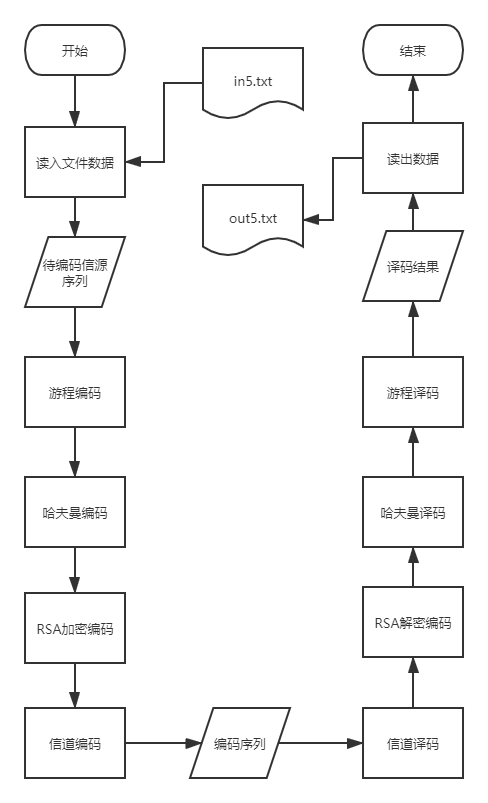
综合编码流程图
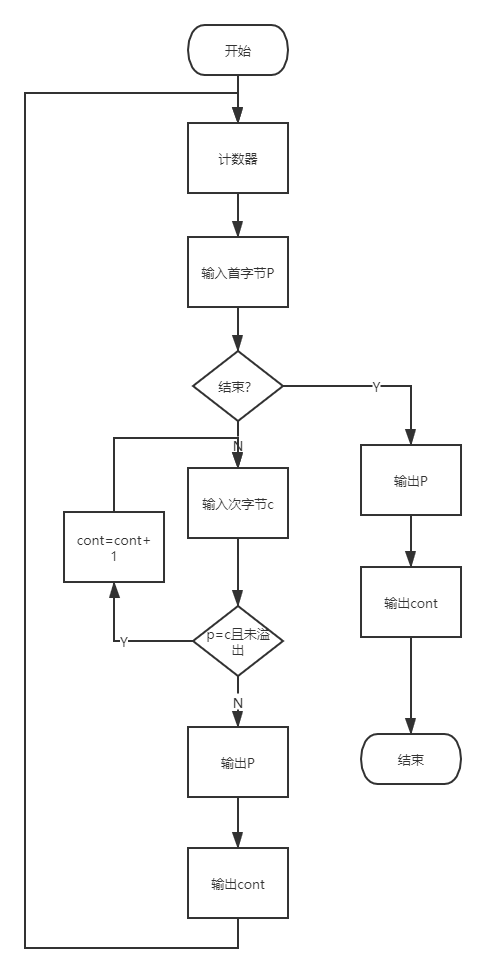
游程压缩实现流程图
实现源码
//游程编码
void YCencode(char* str)
{
int count = 1;
int j = 0;
int i = 0;
if (str[0] == '1') { yc[0] = 0; j = 1; }
for (i = 0; str[i] != 0; i++)
{
if (str[i + 1] == str[i])
{
count++;
}
else {
yc[j] = count; j++;
count = 1;
}
}
yc[j] = 0;
l = j;
for (int k = 0; k < l; k++)
{
cout << yc[k] << " ";
}
}
//对称加密
string DCencode(string m, int l)
{
string so;
string temp;
int c;
int num(0), num1(0);
bool b(false);
for (int n(0); n < l; n++, num++)
{
if (num1 >= 3)
num1 = 0;
b = false;
if (m[n] == ' ')
{
if (num == 0)
{
num = -1;
b = true;
}
else
{
for (; num < 4; num++)
{
temp += '0';
}
b = true;
}
}
else
{
temp += m[n];
}
if (num >= 3)
{
num = -1;
c = bit_int(temp, 9);
temp = "";
so += int_bit(c);
num1++;
}
if (b)
{
for (; num1 < 3; num1++)
{
so += int_bit(bit_int("0000", 9));//int_bit(((bit_int("0000") + 3) % 16));
}
}
}
return so;
}
//对称解密
string DCdecode(string m, int l)
{
string so;
string temp, temp_0;
int l1(0);
int l2(0);
for (int n(0); n < l; n++)
{
if (n % 4 == 3)
{
temp_0 += m[n];
temp += int_bit(bit_int(temp_0, 7));
temp_0 = "";
}
else
{
temp_0 += m[n];
}
if (n % 12 == 11)
{
l2 = l2 % 2;
l1 = len1(temp, temp.length());
for (int a(0); a < 17; a++)
if (temp.compare(0, (l1 > (int)mh[a][l2].length() ? l1 : mh[a][l2].length()), mh[a][l2]) == 0)
{
so += mh[a][l2] + ' ';
break;
}
temp = "";
l2++;
}
}
return so;
}
//信道编码
string XDencode(string m, int l)
{
string so;
string temp;
for (int n(0); n < l; n++)
{
temp += m[n];
if (n % 4 == 3)
{
for (int n2(0); n2 < 16; n2++)
{
if (xd[n2].compare(0, 4, temp) == 0)
so += xd[n2];
}
temp = "";
}
}
return so;
}
//信道解码
string XDdecode(string m, int l)
{
string so, temp;
bool b(false);
for (int n(0); n < l; n++)
{
int n4;
temp += m[n];
if (n % 7 == 6)
{
cout << temp;
n4 = 0;
for (int n2(0); n2 < 16; n2++)
if (temp.compare(xd[n2]) != 0)
{
n4++;
}
else
break;
if (n4 == 15)
{
temp = findxd(temp);
}
for (int n3(0); n3 < 4; n3++)
so += temp[n3];
temp = "";
}
}
cout << endl;
return so;
}
//模拟信道传输
int suiji() //产生随机数
{
srand((int)time(0));
int a = rand() % 10;
if (a == 0)
{
return 1;
}
else
{
return 0;
}
}
运行结果
in5.txt和out5.txt文件


设计体会
通过本次实验,了解了霍夫曼编码,游程编码,加密编码以及信道编码的原理和基本流程,了解了编码与译码,加密与解密的基本原理,实验过程中通过查阅资料了解了RSA加密算法。经过本次实验提高了我的解决问题的能力、查阅资料和文献检索的能力。