ConcurrentHashMap
在涉及到Java多线程开发时,如果我们使用HashMap可能会导致死锁问题,使用HashTable效率低
而ConcurrentHashMap既可以保持同步也可以提高并发效率,所以这个时候ConcurrentHashmap是我们最好的选择
Map
Map是数组+链表结构(JDK1.8该为数组+红黑树)
HashMap
在多线程环境中使用HashMap的put方法有可能导致程序死循环,因为多线程可能会导致HashMap形成环形链表
即链表的一个节点的next节点永不为null,就会产生死循环
return (index < 0) ? false : remove(o, snapshot, index);
这时,CPU的利用率接近100%,所以并发情况下不能使用HashMap
HashTable
HashTable通过使用synchronized保证线程安全,但在线程竞争激烈的情况下效率低下
因为当一个线程访问HashTable的同步方法时,其他线程只能阻塞等待占用线程操作完毕
分段锁
分段锁是先分段再锁,将原本的一整个的Entry数组分成了若干段,分别将这若干段放在了不同的新的Segment数组中
每个Segment有各自的锁,以此提高效率

ConcurrentHashMap
ConcurrentHashMap使用分段锁的思想,对于不同的数据段使用不同的锁
可以支持多个线程同时访问不同的数据段,这样线程之间就不存在锁竞争,从而提高了并发效率
ConcurrentHashMap的设计与实现非常精巧,大量的利用了volatile,final,CAS等lock-free技术来减少锁竞争对于性能的影响
采用Hash的链地址法

JDK1.8版本的ConcurrentHashMap的数据结构已经接近HashMap
ConcurrentHashMap只是增加了同步的操作来控制并发
从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树
- 数据结构:取消了Segment分段锁的数据结构,取而代之的是数组+链表+红黑树的结构
- 保证线程安全机制:JDK1.7采用segment的分段锁机制实现线程安全,其中segment继承自ReentrantLock。JDK1.8采用CAS+Synchronized保证线程安全
- 锁的粒度:原来是对需要进行数据操作的Segment加锁,现调整为对每个数组元素加锁(Node)。
- 链表转化为红黑树:定位结点的hash算法简化会带来弊端,Hash冲突加剧,因此在链表节点数量大于8时,会将链表转化为红黑树进行存储
- 查询时间复杂度:从原来的遍历链表O(n),变成遍历红黑树O(logN)
CopyOnWriteArrayList
和ArrayList一样,底层数据结构是数组,加上transient不让其被序列化,加上volatile修饰来保证多线程下的其可见性和有序性
构造函数
public CopyOnWriteArrayList() { //默认创建一个大小为0的数组 setArray(new Object[0]); } final void setArray(Object[] a) { array = a; } public CopyOnWriteArrayList(Collection<? extends E> c) { Object[] elements; //如果当前集合是CopyOnWriteArrayList的类型的话,直接赋值给它 if (c.getClass() == CopyOnWriteArrayList.class) elements = ((CopyOnWriteArrayList<?>)c).getArray(); else { //否则调用toArra()将其转为数组 elements = c.toArray(); // c.toArray might (incorrectly) not return Object[] (see 6260652) if (elements.getClass() != Object[].class) elements = Arrays.copyOf(elements, elements.length, Object[].class); } //设置数组 setArray(elements); } public CopyOnWriteArrayList(E[] toCopyIn) { //将传进来的数组元素拷贝给当前数组 setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class)); }
add函数
public boolean add(E e) { //使用ReentrantLock上锁 final ReentrantLock lock = this.lock; lock.lock(); try { //调用getArray()获取原来的数组 Object[] elements = getArray(); int len = elements.length; //复制老数组,得到一个长度+1的数组 Object[] newElements = Arrays.copyOf(elements, len + 1); //添加元素,在用setArray()函数替换原数组 newElements[len] = e; setArray(newElements); return true; } finally { lock.unlock(); } }
修改操作是基于fail-safe机制
- 像我们的String一样,不在原来的对象上直接进行操作,而是复制一份对其进行修改
- 另外此处的修改操作是利用Lock锁进行上锁的,所以保证了线程安全问题
remove函数
public boolean remove(Object o) { Object[] snapshot = getArray(); int index = indexOf(o, snapshot, 0, snapshot.length); return (index < 0) ? false : remove(o, snapshot, index); } private boolean remove(Object o, Object[] snapshot, int index) { final ReentrantLock lock = this.lock; //上锁 lock.lock(); try { Object[] current = getArray(); int len = current.length; if (snapshot != current) findIndex: { int prefix = Math.min(index, len); for (int i = 0; i < prefix; i++) { if (current[i] != snapshot[i] && eq(o, current[i])) { index = i; break findIndex; } } if (index >= len) return false; if (current[index] == o) break findIndex; index = indexOf(o, current, index, len); if (index < 0) return false; } //复制一个数组 Object[] newElements = new Object[len - 1]; System.arraycopy(current, 0, newElements, 0, index); System.arraycopy(current, index + 1, newElements, index, len - index - 1); //替换原数组 setArray(newElements); return true; } finally { lock.unlock(); } }
效率比ArrayList低,毕竟多线程场景下,其每次都是要在原数组基础上复制一份在操作耗内存和时间
而ArrayList只是容量满了进行扩容,因此在非多线程的场景下还是用ArrayList
适用场景
- CopyOnWriteArrayList适合于多线程场景下使用,其采用读写分离的思想,读操作不上锁,写操作上锁,且写操作效率较低
- CopyOnWriteArrayList基于fail-safe机制,每次修改都会在原先基础上复制一份,修改完毕后在进行替换
- CopyOnWriteArrayList采用的是ReentrantLock进行上锁
ConcurrentLinkedQueue
ConcurrentLinkedQueue是一个基于链接节点的无界线程安全队列
- 采用先进先出的规则对节点进行排序
- 当添加一个元素的时候,它会添加到队列的尾部
- 当获取一个元素时,它会返回队列头部的元素
- 采用了“wait-free”算法来实现,该算法在Michael & Scott算法上进行了一些修改
ConcurrentLinkedQueue由head节点和tail节点组成
每个节点(Node)由节点元素(item)和指向下一个节点的引用(next)组成
节点与节点之间就是通过这个next关联起来,从而组成一张链表结构的队列
入队

offer方法

出队
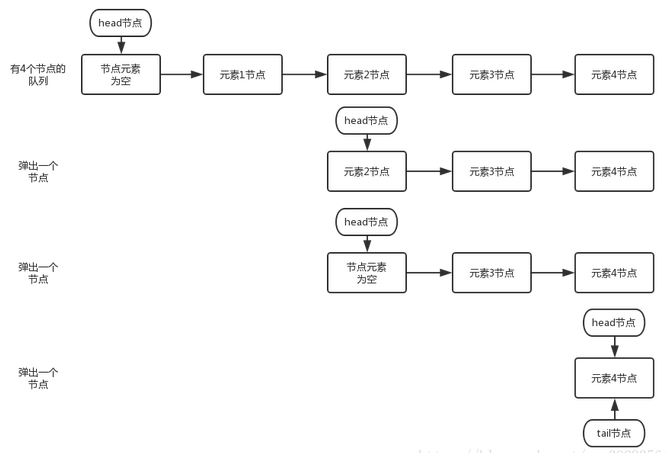
poll

peek
peek操作会改变head指向,执行peek()方法后head会指向第一个具有非空元素的结点
总结
- 使用 CAS 原子指令来处理对数据的并发访问,这是非阻塞算法得以实现的基础
- head/tail 并非总是指向队列的头 / 尾节点,也就是说允许队列处于不一致状态
- 这个特性把入队 / 出队时,原本需要一起原子化执行的两个步骤分离开来,从而缩小了入队 / 出队时需要原子化更新值的范围到唯一变量
- 这是非阻塞算法得以实现的关键
- 由于队列有时会处于不一致状态,为此,ConcurrentLinkedQueue 使用三个不变式来维护非阻塞算法的正确性
- 以批处理方式来更新 head/tail,从整体上减少入队 / 出队操作的开销
- 为了有利于垃圾收集,队列使用特有的 head 更新机制
- 为了确保从已删除节点向后遍历,可到达所有的非删除节点,队列使用了特有的向后推进策略
LinkedBlockingQueue
线程友好的生产者消费者队列模型
LinkedBlockingQueue是一个基于单向链表的、范围任意的(其实是有界的)、FIFO 阻塞队列
访问与移除操作是在队头进行,添加操作是在队尾进行,并分别使用不同的锁进行保护
- 只有在可能涉及多个节点的操作才同时对两个锁进行加锁
- 队列是否为空、是否已满仍然是通过元素数量的计数器(count)进行判断
- 可以同时在队头、队尾并发地进行访问、添加操作
- 线程安全的计数器,使用原子类
AtomicInteger,容量范围是: 1 – Integer.MAX_VALUE
由于同时使用了两把锁,在需要同时使用两把锁时,加锁顺序与释放顺序是非常重要的
- 必须以固定的顺序进行加锁,再以与加锁顺序的相反的顺序释放锁。
头结点和尾结点一开始总是指向一个哨兵的结点,它不持有实际数据
- 当队列中有数据时,头结点仍然指向这个哨兵,尾结点指向有效数据的最后一个结点
- 这样做的好处在于,与计数器 count 结合后,对队头、队尾的访问可以独立进行,而不需要判断头结点与尾结点的关系
put实现阻塞
put 操作把指定元素添加到队尾,如果没有空间则一直等待
take实现阻塞
take 操作会一直阻塞直到有元素可返回
总结
- linkedblockingqueue通过ReentrantLock和Condition条件来保证多线程的正确访问的
- 取元素(出队列)和存元素(入队列)是采用不同的锁,进行了读写分离,利于提高并发度
DelayQueue
DelayQueue是什么
DelayQueue是一个无界的BlockingQueue,用于放置实现了Delayed接口的对象
其中的对象只能在其到期时才能从队列中取走
这种队列是有序的,即队头对象的延迟到期时间最长
注意:不能将null元素放置到这种队列中
DelayQueue能做什么,用来按照时间进行任务调度
- 淘宝订单业务:下单之后如果三十分钟之内没有付款就自动取消订单
- 饿了吗订餐通知:下单成功后60s之后给用户发送短信通知
- 关闭空闲连接。服务器中,有很多客户端的连接,空闲一段时间之后需要关闭之
- 缓存。缓存中的对象,超过了空闲时间,需要从缓存中移出
- 任务超时处理。在网络协议滑动窗口请求应答式交互时,处理超时未响应的请求等
工作原理
- 队列元素需要实现getDelay(TimeUnit unit)方法和compareTo(Delayed o)方法
- getDelay定义了剩余到期时间,compareTo方法定义了元素排序规则,内部存储结构聚合了优先级队列(小顶堆)
- 存放元素时元素存储交由优先级队列存放
- 存放元素时,将元素根据compareTo放入优先级队列
- 获取元素时,总是判断PriorityQueue队列的队首元素是否到期,若未到期就等待,线程进入等待状态等待唤醒
- 若到期则元素出队
- 其中涉及到Leader/Follower线程模型,线程去获取堆顶元素时,元素并未到期,那么会去将自己设置为Leader线程等待指定的时间后唤醒
- 如果Leader已经有其他线程,则自己为Follower
等待时间短的优先得到执行
Leader-Follower pattern
- 当存在多个take线程时,同时只生效一个,即leader线程
- 当leader存在时,其它的take线程均为follower,其等待是通过condition实现的
- 当leader不存在时,当前线程即成为leader,在delay之后,将leader角色释放还原
- 最后如果队列还有内容,且leader空缺,则调用一次condition的signal,唤醒挂起的take线程,其中之一将成为新的leader
- 最后在finally中释放锁
SynchronousQueue
SynchronousQueue是一个队列,但它的特别之处在于它内部没有容器
一次配对过程(当然也可以先take后put,原理是一样的)
- 一个生产线程,当它生产产品(即put的时候)
- 如果当前没有人想要消费产品(即当前没有线程执行take),此生产线程必须阻塞,等待一个消费线程调用take操作
- take操作将会唤醒该生产线程,同时消费线程会获取生产线程的产品(即数据传递)
SynchronousQueue直接使用CAS实现线程的安全访问
队列的实现策略通常分为公平模式和非公平模式
公平模式
底层实现使用的是TransferQueue这个内部队列,它有一个head和tail指针,用于指向当前正在等待匹配的线程节点
初始化时,TransferQueue的状态如下

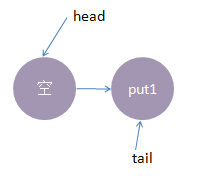
线程put1执行 put(1)操作
由于当前没有配对的消费线程,所以put1线程入队列,自旋一小会后睡眠等待,这时队列状态如下
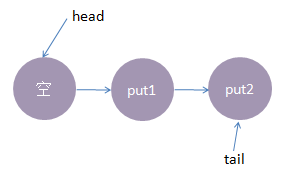
线程put2执行了put(2)操作
跟前面一样,put2线程入队列,自旋一小会后睡眠等待,这时队列状态如下
来了一个线程take1执行了 take操作
由于tail指向put2线程,put2线程跟take1线程配对了(put--take),这时take1线程不需要入队
要唤醒的线程并不是put2,而是put1
公平策略就是谁先入队了,谁就优先被唤醒,我们的例子明显是put1应该优先被唤醒
至于读者可能会有一个疑问,明明是take1线程跟put2线程匹配上了,结果是put1线程被唤醒消费,怎么确保take1线程一定可以和次首节点(head.next)也是匹配的呢
公平策略:队尾匹配队头出队
执行后put1线程被唤醒,take1线程的 take()方法返回了1(put1线程的数据),这样就实现了线程间的一对一通信

再来一个线程take2,执行take操作
- 这时候只有put2线程在等候,而且两个线程匹配上了,线程put2被唤醒
- take2线程take操作返回了2(线程put2的数据),这时候队列又回到了起点

队尾匹配队头出队,先进先出,公平原则
非公平模式
非公平模式底层的实现使用的是TransferStack
一个栈,实现中用head指针指向栈顶
1线程put1执行 put(1)操作
由于当前没有配对的消费线程,所以put1线程入栈,自旋一小会后睡眠等待,这时栈状态如下

线程put2再次执行了put(2)操作
跟前面一样,put2线程入栈,自旋一小会后睡眠等待,这时栈状态如下

线程take1,执行了take操作
发现栈顶为put2线程,匹配成功,但是实现会先把take1线程入栈,然后take1线程循环执行匹配put2线程逻辑
一旦发现没有并发冲突,就会把栈顶指针直接指向put1线程
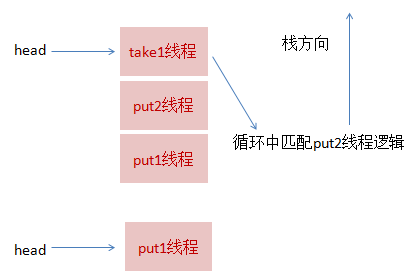
线程take2,执行take操作
这跟步骤3的逻辑基本是一致的,take2线程入栈,然后在循环中匹配put1线程,最终全部匹配完毕,栈变为空,恢复初始状态,如下图所示:
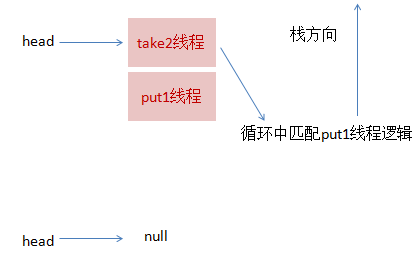
虽然put1线程先入栈了,但是却是后匹配,这就是非公平的由来。
总结
SynchronousQueue由于其独有的线程一一配对通信机制
在大部分平常开发中,可能都不太会用到,但线程池技术中会有所使用
由于内部没有使用AQS,而是直接使用CAS,所以代码理解起来会比较困难,但这并不妨碍我们理解底层的实现模型
LinkedTransferQueue
LinkedTransferQueue是ConcurrentLinkedQueue、SynchronousQueue(公平模式下转交元素)、LinkedBlockingQueue(阻塞Queue的基本方法)的超集
- LinkedTransferQueue是一个由链表结构组成的无界阻塞TransferQueue队列
- 相对于其他阻塞队列,LinkedTransferQueue多了tryTransfer和transfer方法
- 如果队列不为空,则直接取走数据,若队列为空,那就生成一个节点(节点元素为null)入队
- 然后消费者线程被等待在这个节点上,后面生产者线程入队时发现有一个元素为null的节点,生产者线程就不入队了,直接就将元素填充到该节点
- 唤醒该节点等待的线程,被唤醒的消费者线程取走元素,从调用的方法返回
- 这种节点操作为“匹配”方式
工作原理

相比较 SynchronousQueue 多了一个可以存储的队列,相比较 LinkedBlockingQueue 多了直接传递元素,少了用锁来同步
性能更高,用处更大
Vector
Hashtable
Hashtable和vector基本不用