卷积神经网络
一、摘要
卷积网络(Convolutional network)也叫神经网络,是一种专门用来处理具有类似网格结构的数据的神经网络。例如时间序列数据和图像数据(可以看做二维的像素网络)。卷积网络在诸多应用领域表现得都比较出色。卷积网络是指那些至少在网络的一层中使用卷积运算来代替 一般的矩阵乘法运算的神经网络。
二、卷积运算
在通常形式中,卷积是两个实变函数的一种数学运算。对于卷积连续的表达式我们可以表示为:
$$ s(t) = int mathrm { x(a)}mathrm{w(t-a)}mathrm { d } x$$
而离散的表达式为:
$$s(t) = (x*w)(t) = displaystylesum_{a=-infty}^{infty} x(a)w(t-a)$$
在卷积网络中,卷积的第一个参数(函数x)通常叫做输入,第二个参数(函数w)叫做卷积函数。输出有时被称作为特征映射。
在机器学习中,输入通常是多维数组的数据,而核通常是由学习优化得到的多维数组的参数。所以,在卷积层的网络中通常是一次在多个 维度上进行卷积运算。例如,如果把一张二维的图像I作为输入,这时我们要使用的核函数也是一个二维的核K:
$$S(i,j) = (I*K)(i,j) = sum sum I(m,n)K(i-m,j-n)$$
对于卷积的运算时可以交换的,所以:
$$S(i,j) = (I*K)(i,j) = sum sum I(i-m,j-n)K(m,n)$$
而在机器学习的库中,通常用到的m与n通常都比较小。
三、神经网络与卷积神经网络
卷积神经网络与普通神经网络的区别在于,卷积神经网络包含了一个由卷积层和子采样层构成的特征抽取器,而且在普通神经网络中,由于数据量很大,所以在隐层中的神经元一般也会比较多,所以使用全连接的方式会使他们的W参数量很大,容易过拟合。卷积神经网络解决的问题是参数量大的问题,在卷积神经网络的卷积层中,一个神经元只与部分邻层神经元连接。在CNN的一个卷积层中,通常包含若干个特征平面(featureMap),每个特征平面由一些矩形排列的的神经元组成,同一特征平面的神经元共享权值,这里共享的权值就是卷积核。卷积核一般以随机小数矩阵的形式初始化,在网络的训练过程中卷积核将学习得到合理的权值。共享权值(卷积核)带来的直接好处是减少网络各层之间的连接,同时又降低了过拟合的风险。
3.1 层级结构
3.1.1 普通神经网络的层级结构:

3.1.2 卷积网络层级结构:
有与普通神经网络的层级结构,不同层之间有不同的运算与功能。

主要的层次有:数据输入成(Input layer),卷积计算层(CONV layer),激励层(Activation layer),池化层(Pooling layer),全连接层(FC layer)。
四、卷积神经网络
4.1 数据输入层(Input layer)
在数据输入层中,接收数据的输入,并处理。有三种常见的处理方式。
4.1.1 去均值
把输入的数据都中心化到坐标轴的中心位置。
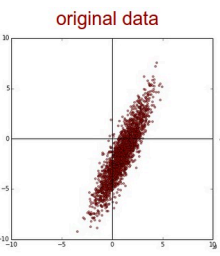
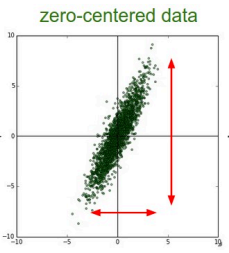
4.1.2 归一化
把幅度归一到同样的范围,但对于图像的数据,一般数值在0到255,所以对于图像的数据,可以不做归一化。
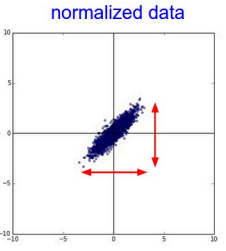
4.1.3 PCA/白化
对于数据维度太高,但有些数据对结果不太相关的,可以通过PCA进行降维。白化是对数据每个特征轴上的幅度归一化。

4.2 卷积计算层(CONV layer)
对于卷积层的参数是有一组可学习的滤波器组成,滤波器在空间上都很小。卷积层中每个神经元在空间上的连接的输入是局部的,但是他会连接到所有的深度(整张图片),每一个神经元都有一个W,对图像处理可以理解为滤波这组W通过滤波器对图像做变量,拿到该神经元觉得有用的信息。窗口滑动,对局部数据进行计算。
卷积计算的过程中会涉及到三个概念:深度(depth)、步长(stride)、零填充(zero-padding)。对于深度,我们可以理解为我们想要使用的滤波器(神经元)数量,每个滤波器的学习在输入中寻找不同的东西,对于他认为有用的特征就会抽取。对于幅度,当步幅为1时,我们一次将滤镜移动一个像素,幅度为二的时候移动两个像素。零填充,零填充的优点在于,它可以让我们控制输出体积的空间大小(最常见的是,我们很快就会看到,使用它来精确地保留输入体积的空间大小,以便输入和输出宽度和高度是相同的)。
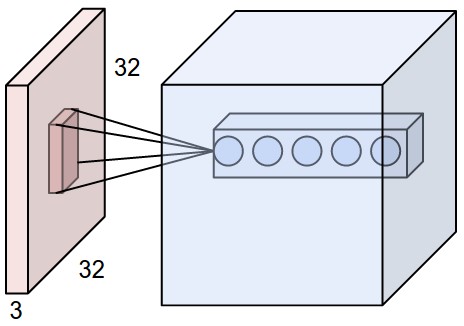
红色的示例输入体积(例如32x32x3 CIFAR-10图像)以及第一个卷积层中的示例体积的神经元。卷积层中的每个神经元仅在空间上连接到输入体积中的局部区域,但是连接到全深度(即所有颜色通道)。请注意,沿深度有多个神经元(本例中为5个)。计算过程的动图如下,对于三个通道的图片计算过程:
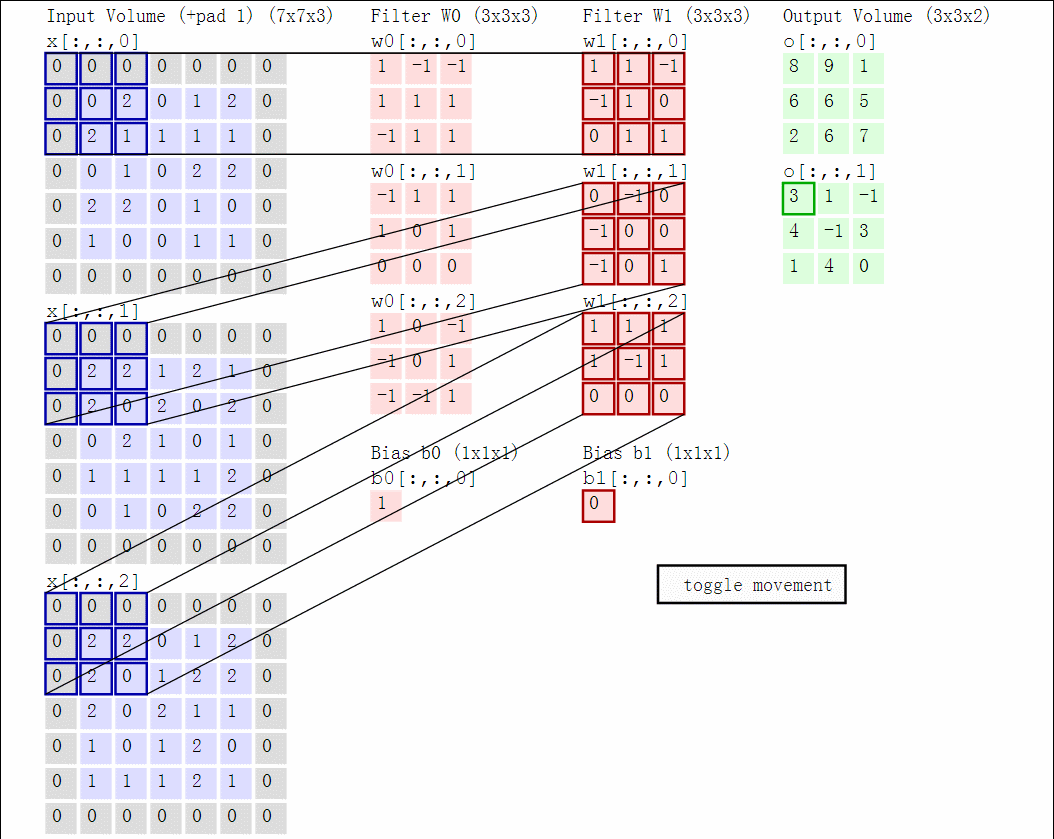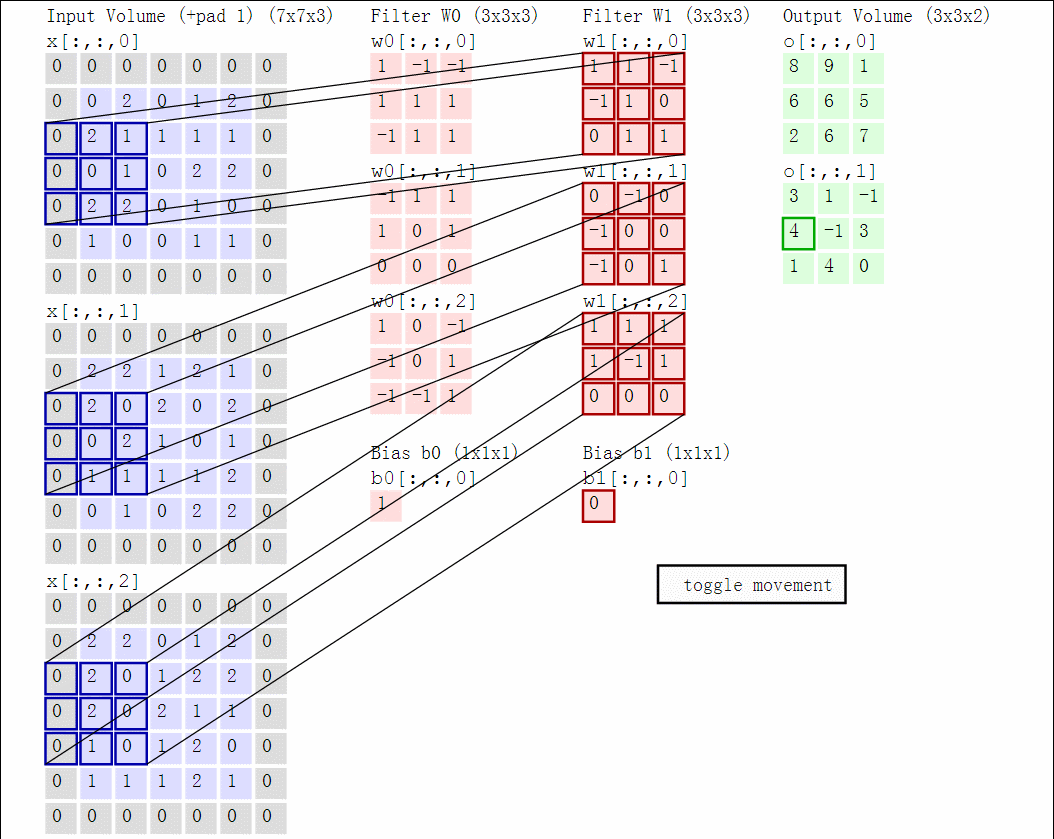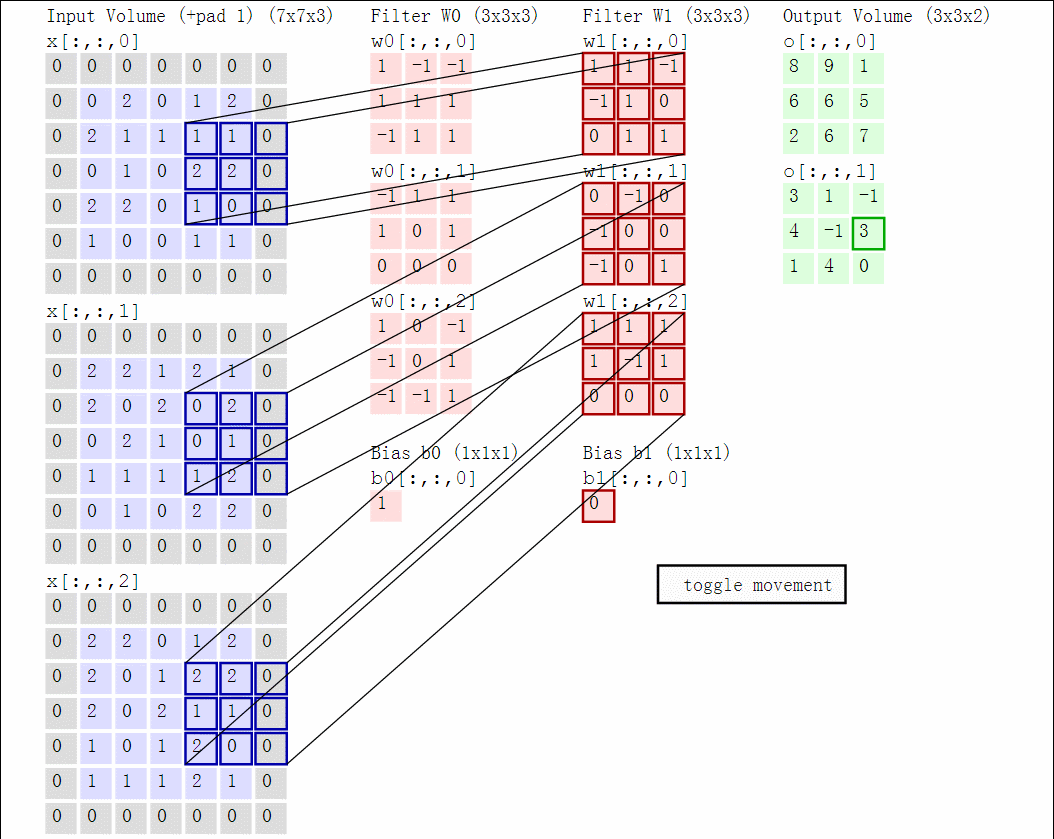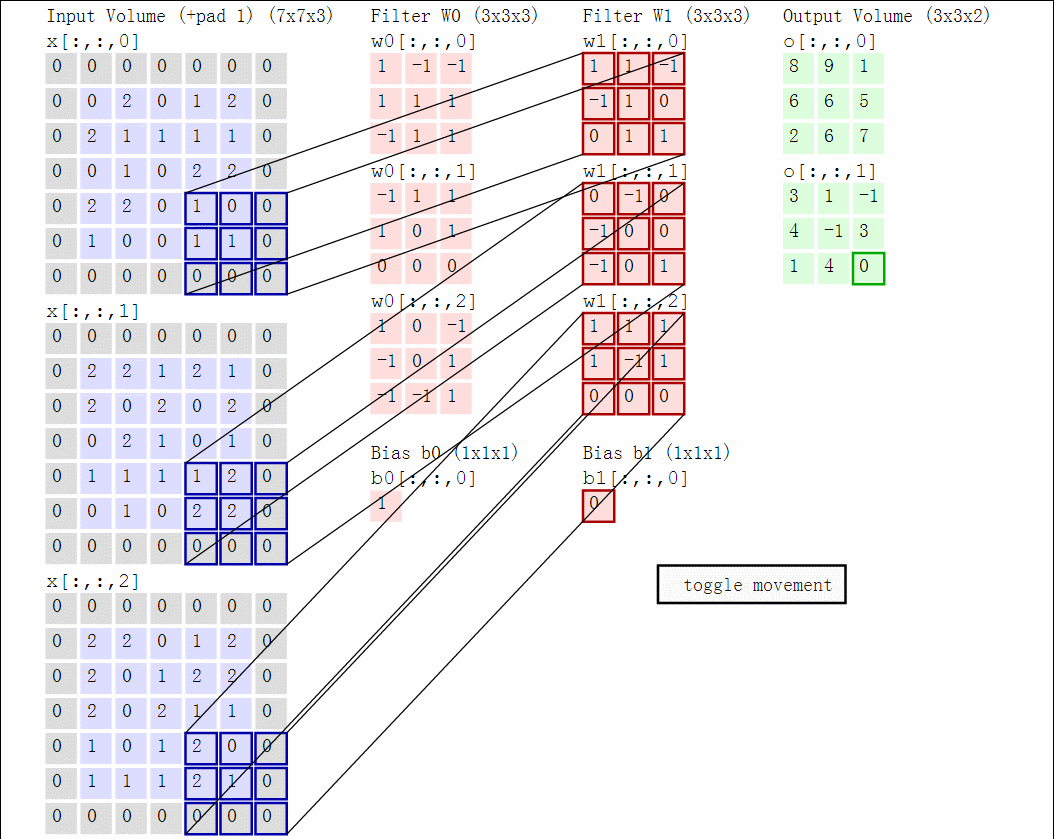
下面举个栗子,以图片的形式展示卷积的计算过程:
原始图片的与特定的神经元(filter)做卷积运算,两个3x3的矩阵作相乘后再相加,以下图为例,计算:$00 + 00 + 01+ 01 + 10 + 00 + 00 + 01 + 0*1 =0$
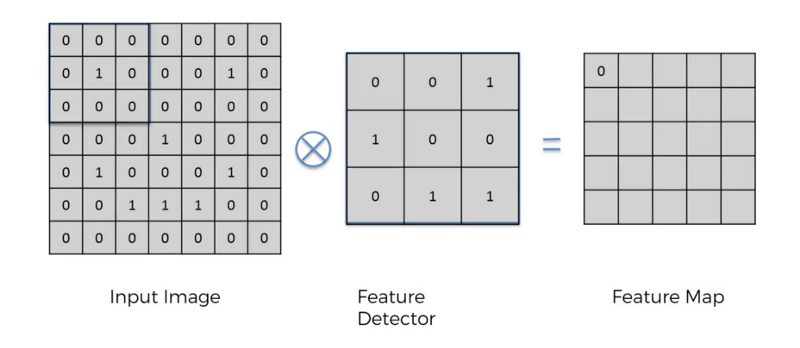
依序遍历完整张图片可得:

中间的神经元(Feature Detector)会随机产生好几种抽取图片特征的方式,他会帮助我们提取屠屏中的特征,就像人的大脑在判断这个图片是什么东西也是根据形状来推测,
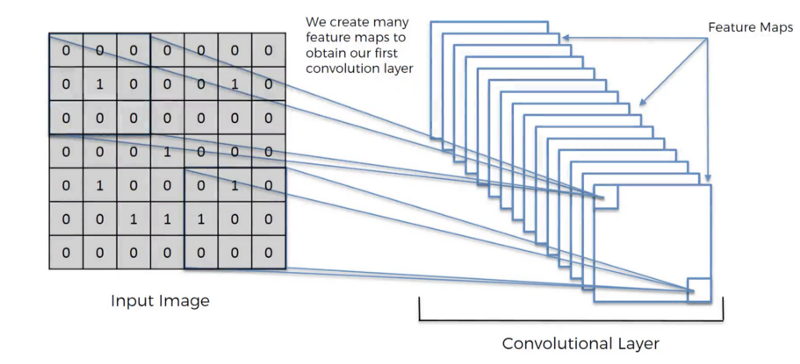
以上就是卷积层的计算过程,通过卷积层抽取图片的特征。
4.3 激励层(Activation layer)
4.3.1 激励函数的应用
激励层是把卷积层输出的结果做成非线性映射。
例如:通过Feature提取物体的边界,
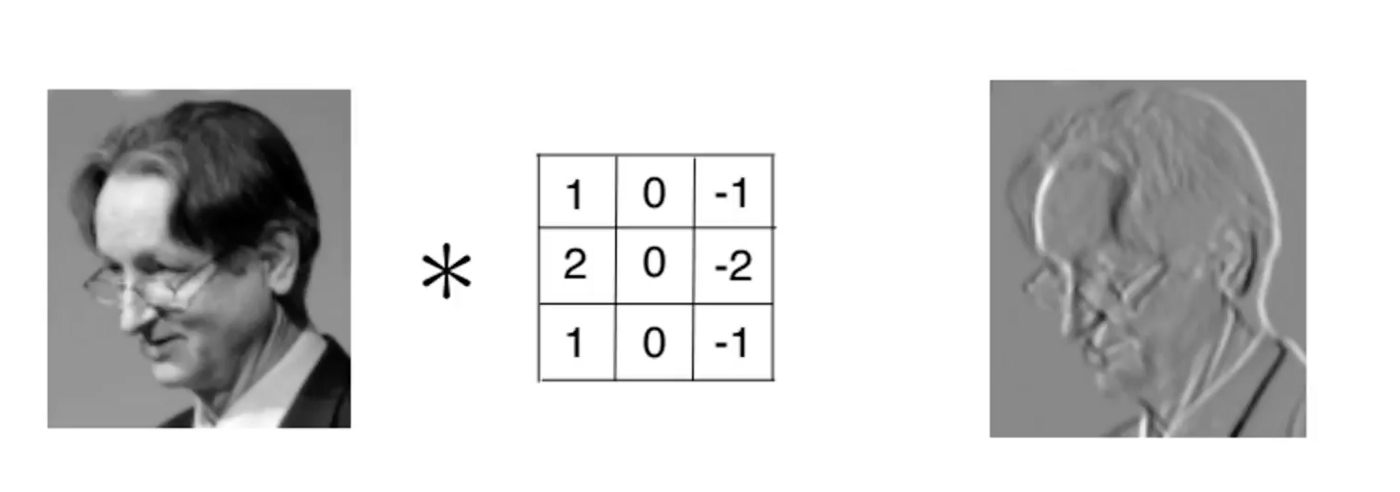
提取到物体的边界后可能会有负值,通过激励函数Relu去掉负值,更能提取出物体的形状。
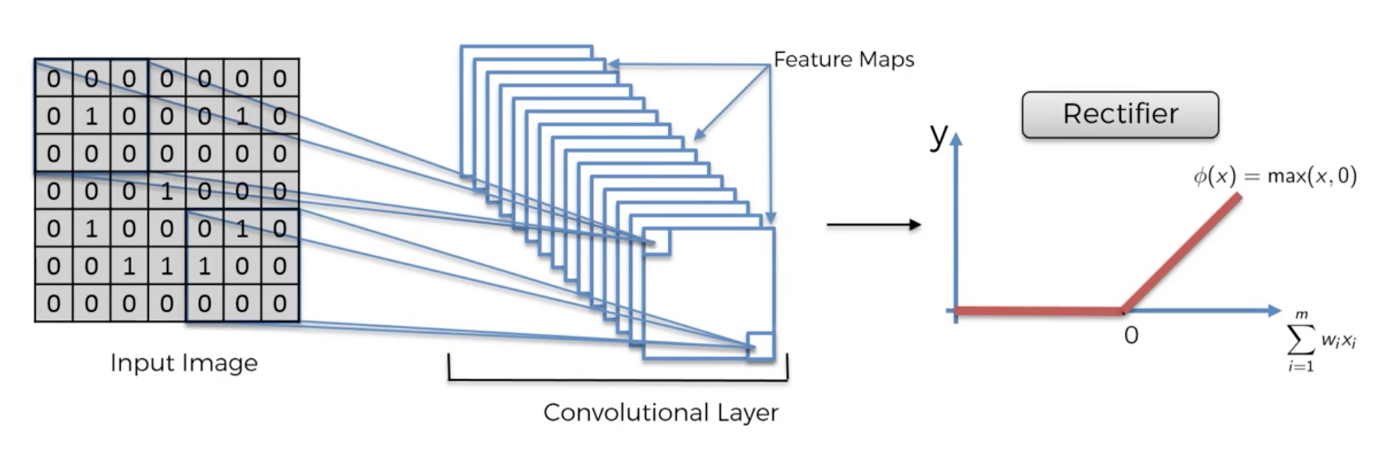
4.3.2 常用的激励函数
Sigmoid,Tanh(双曲正切),ReLU,Leaky ReLU,ELU,Maxout等。如图所示:

但在CNN中要慎用Sigmoid,因为在训练过程中,网络是多层的,BP算法是通过链式求导的法则,对于Sigmoid会有0值,会陷入一个局部最优的状态。所以,对于CNN先试试ReLU,因为计算比较快,如果失效再用Leaky ReLU或者Maxout。
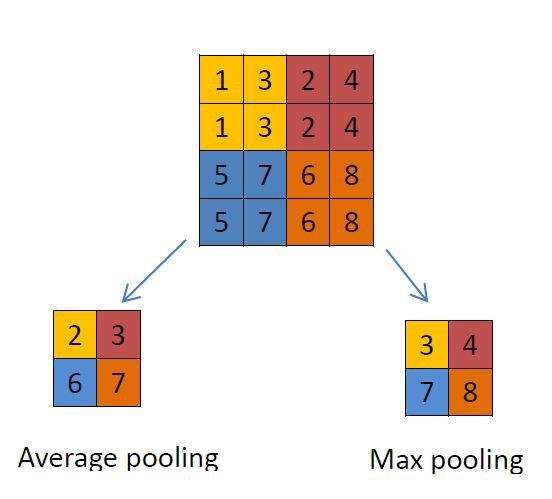
4.4 池化层(Pooling layer)
池化层是在连续的卷积层中间,压缩数据和参数的作用,减小过拟合。

在Pooling layer 层主要方式有Max pooling 和average pooling,过程如下图:
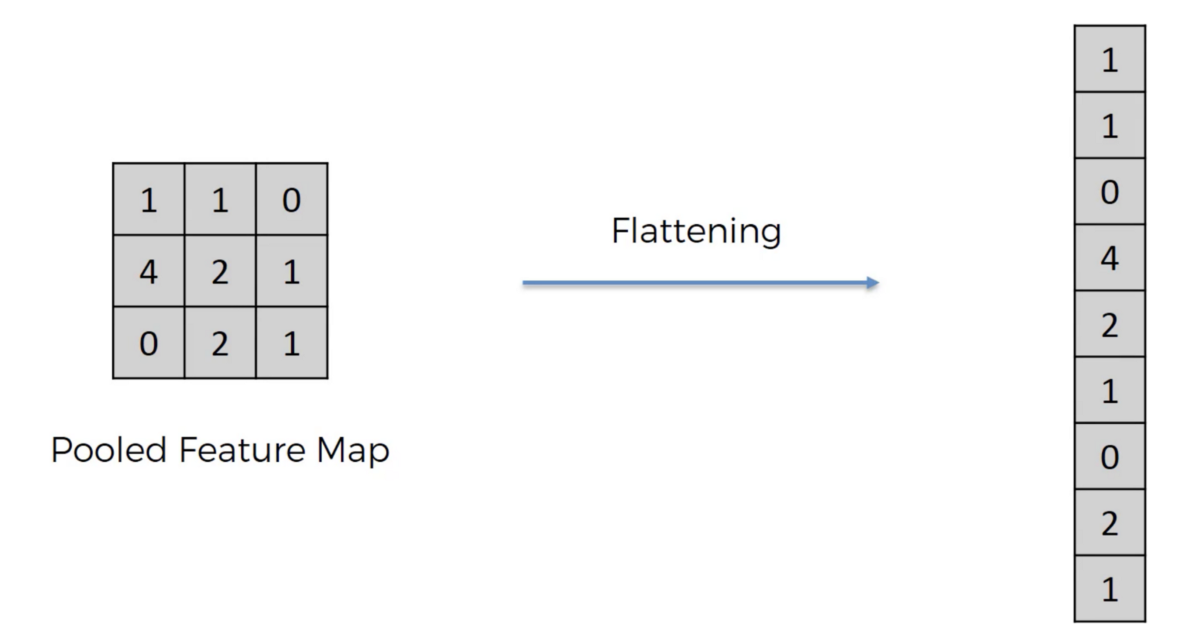
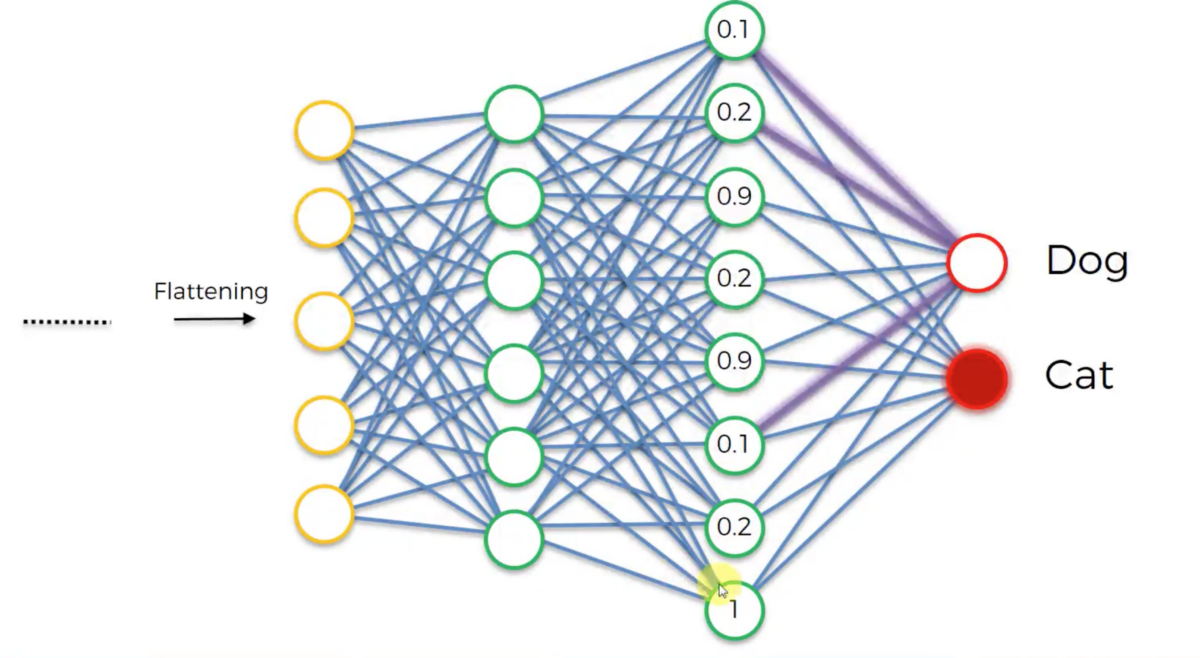
4.5 全连接层(FC layer)
基本上全连接层的部分就是将之前的结果平坦化之后接到最基本的神经网络了,两层之间所有神经元都远权重连接,通常连接层在卷积层网络的 末尾,如下图:

五、卷积神经网络训练算法
卷积神经网络与机器学习算法一般,需要先定义Loss function,衡量和实际结果的差距,找到最小化损失函数的W和b,CNN中用的算法是随机梯度下降法(SGD)。SGD需要计算W和b偏导。BP算法利用链式求导法则,逐级相乘知道求解出dW和db。利用SGD迭代和更新W和b。在这里不详细讲解SGD算法和BP算法。
六、总结
6.1 层级结构
通过以上的我们可以总结,典型的CNN结构为:INPUT-->[ [ CONV --> RELU ]*N --> POOL?] * N -->[FC --> RELU] *K --> FC。
6.2 CNN优缺点
6.2.1 优点
共享卷积核,能够降低参数量,优化计算量,无需手动选取特征,可以通过训练获取权重,即可提取特征,深层次的网络抽取图像信息丰富,表达效果好。
6.2.2 缺点
需要调参,且不好调,需要大量的样本,GPU等硬件的依赖。
参考文献
[1] .卷积神经网络介绍(Convolutional Neural Network).
[2] .CS231n Convolutional Neural Networks for Visual Recognition.
[3] 深度学习(DEEP LEARNING).lan Goodfellow,Yoshua Bengio,Aaron Courville.
实训部分
Data preparation (keras.dataset)
We will train our model on the MNIST dataset, which consists of 60,000 28x28 grayscale images of the 10 digits, along with a test set of 10,000 images.

Since this dataset is provided with Keras, we just ask the keras.dataset model for training and test data.
We will:
- download the data
- reshape data to be in vectorial form (original data are images)
- normalize between 0 and 1.
The binary_crossentropy loss expects a one-hot-vector as input, therefore we apply the to_categorical function from keras.utilis to convert integer labels to one-hot-vectors.
使用keras框架,构建CNN网络完成对MNIST数据集的训练,评估及预测
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
import tensorflow as tf
from keras.utils import np_utils
1.数据处理部分
batch_size = 128
num_classes = 10
epochs = 5
# input image dimensions
img_rows, img_cols = 28, 28
# the data, shuffled and split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# 幅度缩放
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
# 对数据进行转换,因为在keras中训练等对数据的数量一般要用numpy.ndarray类型
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
# 查看一下数据
import matplotlib.pyplot as plt
%matplotlib inline
plt.imshow(x_train[0].reshape(28, 28))
2. 模型部分
# 创建一个系灌模型
model = Sequential()
# 卷积层,3*3的卷积核,后面接激活函数,relu。32个神经元
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
# 池化层
model.add(MaxPooling2D(pool_size=(2, 2)))
# 正则化
model.add(Dropout(0.25))
# 全连接层前面的shape要是n*1的,就是类似向量形式,所以沿展开
model.add(Flatten())
# 全连接
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
# 全连接,直接连接到多少个类
model.add(Dense(num_classes, activation='softmax'))
3. 编译
- 告诉他用交叉熵的loss。指定优化器:optimizer=keras.optimizers.Adadelta(),评估的准则:accuracy
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
4. 训练
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
- 通过以上的结果可以看出,通过CNN网络能够很好的对图像进行识别,准确率很高。
5. 评估
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])