一、阅读前
其实录制了一个视频专门讲解这篇文章,视频中讲的比下文还全哦

视频链接:
https://mp.weixin.qq.com/s/wGcODm6gfy6JOvkcKp-8MA
https://mp.weixin.qq.com/s/wGcODm6gfy6JOvkcKp-8MA
Oow!
想白嫖explain实战部分用到的建库SQL、存储过程等脚本可以通过上面的视频链接关注,后台回复:explain即可领取哦~
二、explain 实战
2.1、初识执行计划:
获取sql执行计划的语法:explain yoursql
explain select * from t1;

| 字段名 | 作用 |
|---|---|
| id | sql中的每一个select都有一个未对应的id,对子查询来说,有多个select,就有多个id。 |
| select_type | sql执行计划对应的查询类型。如: 1.针对单表查询或者是多表连接查询的select type是simple。 2.union语句针对前半部分sql的select_type为primary,针对后半部分sql的select_type为union,做去重时的select_type是union result。3.sql中出现子查询时,外层的select_type为primary,内层的select_type一般为subquery |
| table | 你的sql要查询哪个表 |
| partitions | 分区表 |
| type | 针对该表查询时的查询方式。如: 1.聚簇索引的const 2.二级索引的查询ref(ref、eq_ref、ref_or_null)、range 3.对二级索引的全表扫描index 4.对聚簇索引的全表扫描的all |
| possible_keys | 有哪些索引可以选择 |
| key | 实际选择的索引 |
| key_len | 索引的长度 |
| ref | 和上面选中key进行比较时,是等值匹配(const)还是其他的字段(库名.表名.列名) |
| rows | 估算的可能会读取的数据条数 |
| filtered | 过滤比例,真实数据*过滤比例为预计将读取出来的数据 |
| extra | 额外的说明数据,如: 1.sql中有where条件时,Extra为:Using Where 2.sql中使用二级索引时,Extra为:Using Index 3.sql中有join语句多表关联时:Extra为:Using join buffer(Block Nested Loop) 4.sql操作产生临时表时,Extra为:Using temporary 5.sql需要根据某个字段排序,且内存不够时(不管是不是索引):Extra为:Using filesort |
2.2、分析联表SQL的执行计划
SQL如下:
mysql> explain select * from t1 join t2;

SQL执行时,会先将驱动表t1中的数据以全表扫描的方式检索出来放在内存中,一共检索4行。然后在将t2表中的数据检索出来,和t1中的数据join在一起作为返回值。由于我们没有加任何where条件,这里还会存在一个笛卡尔积,也就是说结果中会有16条数据
执行计划解析:
id:每一个select 关键字对应一个id,这条SQL中只有一个select,所以这两行执行计划的id都是1
select_type:均是simple 简单的查询方式。
table:查询了哪张表
Partitions:分区
type:ALL表示全表扫描
possible_keys:可能使用到的索引,null表示,没有任何索引 key:null表示实际上也没有使用到索引
key_len:最长的索引的长度
ref:当你使用到索引时,索引列是等值匹配还是其他的连接方式,由于我们都没有索引,所以直接为null
rows:估算的扫描行数
filterd:过滤的比例,实际数量*过滤比例 ≈ 本次查询返回的行数
Extra:其他的信息
2.3、分析子查询SQL的执行计划
SQL如下:
explain select * from t1 where x1 in (select x1 from t2) or x3 = 890;

id:有两个select 语言,所以执行计划的id有两个
table、partitions 不再赘述
select_type:第一行查询语句的查询类型是Primary,主查询。第二条查询SQL的类型是Subquery,自查询。
对于主查询而言,where条件中有or x3 = 123 (x3我们创建了索引)说明他有可用的索引:t1_x3_index 。但是它最终并没有使用这个索引,它使用的全表扫描ALL的查询方式。所以对应的key_len(最长的索引长度为null)。预估全表扫描出9987条数据。
主查询之所以有x3索引却不用,是因为MYSQL认为,使用这个索引和不用索引的层本擦不多。
对于自查询来说,它的查询类型是自查询。它选择使用t2表的x1这个二级索引,最长的索引长度为515byte,预估扫描14948条数据。
2.4、分析union SQL的执行计划
# 联合t1、t2并对union的结果进行去重!
explain select * from t1 union select * from t2;

同样执行计划有有3行
针对t1的查询为主查询,因为sql中没有任何查询条件,所以Extra、possible_key、key都为NULL,并且预计全表扫描9987行数据。
第二行不再赘述。
第三行的查询类型为:Union result,针对表<union1,2>进行操作,Extra中的Using tmporary表明这是一个临时表。也就是说,结果集放到临时表中进行去重。
2.5、分析复杂SQL的执行计划
# 查询x1列重复次数超过1次以上的x1列以及它的重复次数。
explain select * from (select x1,count(*) as cnt from t1 group by x1) as _t1 where cnt > 1;

先看id为2的执行计划,它是针对t1表的查询,并且最终选择索引:t1_x1_index。注意它的select_type是Derived表示派生,意思是它的查询结果是会被物化成一个临时表给外层的sql使用。
再看外层的id为1的SQL,它是类型为primary的主查询,查询的自查询生成的临时表<drived2> 查询的方式是全表扫描。
2.6、常见的执行计划的type
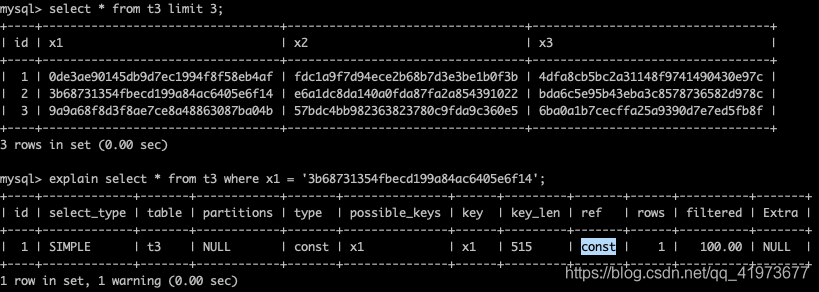
2.6.1、const
查询聚簇索引
explain select * from t1 where id = 5000;

查询唯一的二级索引,执行计划的type同样是const
# t3.x1 是unique key
explain select * from t3 where x1 = 'qweqwe';
2.6.2、ref
ref 对非唯一的二级索引进行检索
mysql> explain select * from t1 where x1 = 'ucshiuhdaiusd';

多个二级索引的等值匹配的type也是ref
mysql> explain select * from t1 where x1 = 'ucshiuhdaiusd' and x3 = 'qdasdsadas';

使用普通索引的做join操作,被join的表的查询type也是ref
mysql> explain select * from t1 inner join t2 on t1.x1 = t2.x1;

2.6.3、eq_ref
eq_ref 使用主键进行join,被join的表的查询type为eq_ref
mysql> explain select * from t1 inner join t2 on t1.id = t2.id;

2.6.4、eq_or_null
对普通二级索引进行检索,并且二级索引允许存在null的情况,那么查询计划的type为eq_or_null
mysql> explain select * from t1 where x1 = 'ucshiuhdaiusd' or x1 is null;

2.6.5、range
基于二级索引进行对一个范围进行检索,查询类型为:range
mysql> explain select * from t1 where id > 5000;

2.6.6、index
type 为 index 类型的执行计划
# t3表中有3个索引,如下:
# id:聚簇索引
# x1:唯一的二级索引
# x1_x3_x2:联合索引
explain select * from t3 where x2 = 'fdc1a9f7d94ece2b68b7d3e3be1b0f3b';
可以看到,x2列没有单独的索引。但是sql的执行计划选择去联合索引树中扫全表,也不会去聚簇索引中全表扫描

补充:索引的选择逻辑
Case1: 比如现有索引:KEY(x1,x3)、KEY(x2,x4)
SQL如下:
select * from t where x1=xxx and x2>yyy;
那么问题来了,x1、x2都有对应的索引,那MYSQL该如何选择索引呢?
一般来说MYSQL会优先选择一个扫描行数少的KEY,作为最终的索引,比如x1是等值条件,x2是range条件,所以最终大概率是通过x1索引查询一次取id,再去回表找到x2列,使用x2>yyy的条件进行过滤。
Case2:在执行SQL语句时有可能会同时查询多个索引。
比如:现有索引:KEY(x1)、KEY(x2)
SQL如下:
select * from table where x1=xxx and x2=yyy;
那它的执行计划可能就是:先从x1索引数中取出x1=xxx的数据行,再从x2的索引树中取出x2=yyy的数据行,这两部分数据根据主键进行一次交集,再使用intersection交集后的结果去聚簇索引中回表。
之前的例子中说的是,在x1和x2这两个索引中优先选一个扫描行数少的索引,先使用它查询,在拿着查询到的结果去回表。
那,之所以示例9中的情况会出现,是因为可能存在如下的情况:
(扫描x1的行数+扫描x2的行数)+ merge之后的行数 < 扫描x1或者x2的最少行数+回表的行数
此外:如果想让一个SQL使用多个索引,也有硬性的条件:
- 如果使用联合索引,那联合索引中的每一个字段都需要出现在sql中,且必须是等值匹配。
- 通过主键查询+其他二级索引的等值匹配,也可能做一次多索引查询做交集后再回表。
补充:如果你的SQL如下:
select * from table where x1=xxx or x2=yyy;
依然有可能使用多个索引,然后对多个索引的结果取union并集
Case3:如下SQL
select * from t1,t2 where t1.x1 = xxx and t1.x2 = t2.x2 and t2.x3 = yyy;
sql中的有t1、t2两个表,前面的t1为驱动表,后面的t2为被驱动表。
sql中的t1.x2 = t2.x2为关联条件。
SQL在执行时会先使用t1.x1=xxx为条件先捞出一部分数据,此次操作会根据x1的索引情况而不同,可能是const、ref、index或者全表扫描all。
假设第一次根据x1=xxx条件找到了2行数据(称这两行数据为A)。接下来会分别拿着这两行数据中的x2为新的条件,去t2表中查询,假设第一行数据的x2列值为123。他就会使用t2.x2=123 and t2.x3=yyy为新的条件在t2表找到匹配到的数据,和第一行数据关联起来。
补充:
这种联表查询的方式也叫做内连接,比如t2中有3行符合
x2=123,那么它们都会被和A中的第一行拼接起来,作为最终的返回值。如果t2表中没有找到t2.x2=123的列,那么A中的第一行数据也不会被保留作为最终的返回值。
那如果不想因为t2.x2中没有符合条件的列也将A中的第一行保留下来,那么可以使用外连接实现。如 left join on + 条件
接着处理A中的第二行数据。
2.7、详解ref列
Case1 ref之: 库名.表名.列名
explain select * from t1 inner join t2 on t1.id = t2.id;

当执行第二个查询计划时,对主键ID进行等值匹配,而且是使用test.t1.id 来和ID进行等值匹配(而不是某个常量)
Case2 ref之:const
explain select * from t1 where x1 = 'qwdasdas';

2.8、Extra 列
关于这一列上面其实提到过了
1、Using where
explain select * from t1 where x1 = 'ucshiuhdaiusd' and x3 = 'qdasdsadas';
2、Using Index
explain select x1 from t1;
3、Using filesort ,其中的x1是二级索引,x2是普通索引。
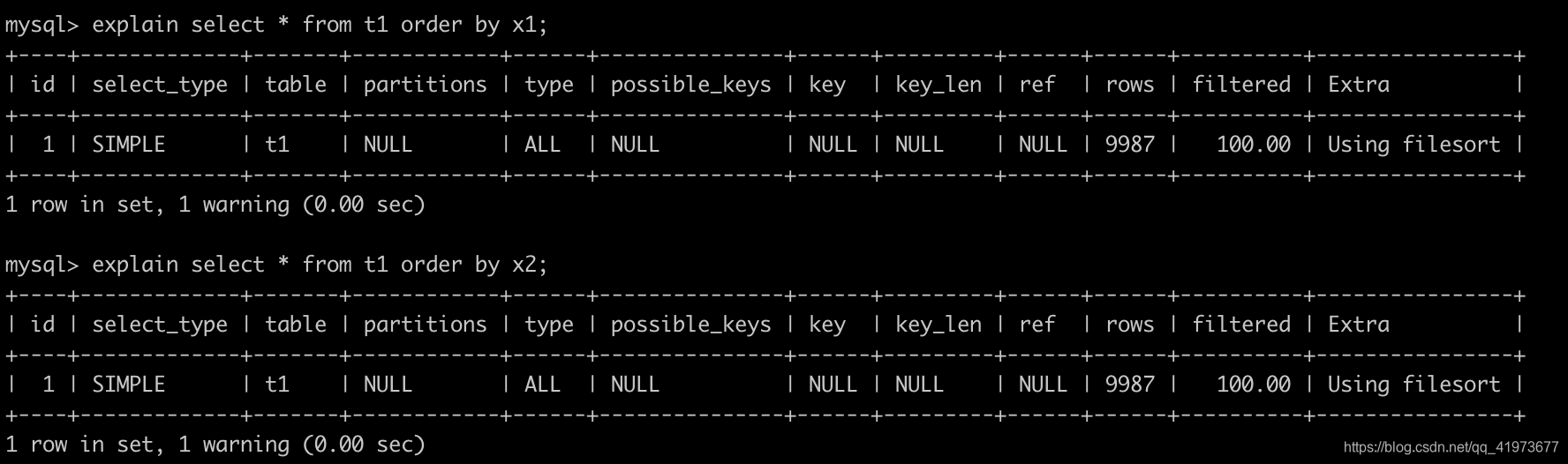
4、Using temporary,表示:使用了中间表
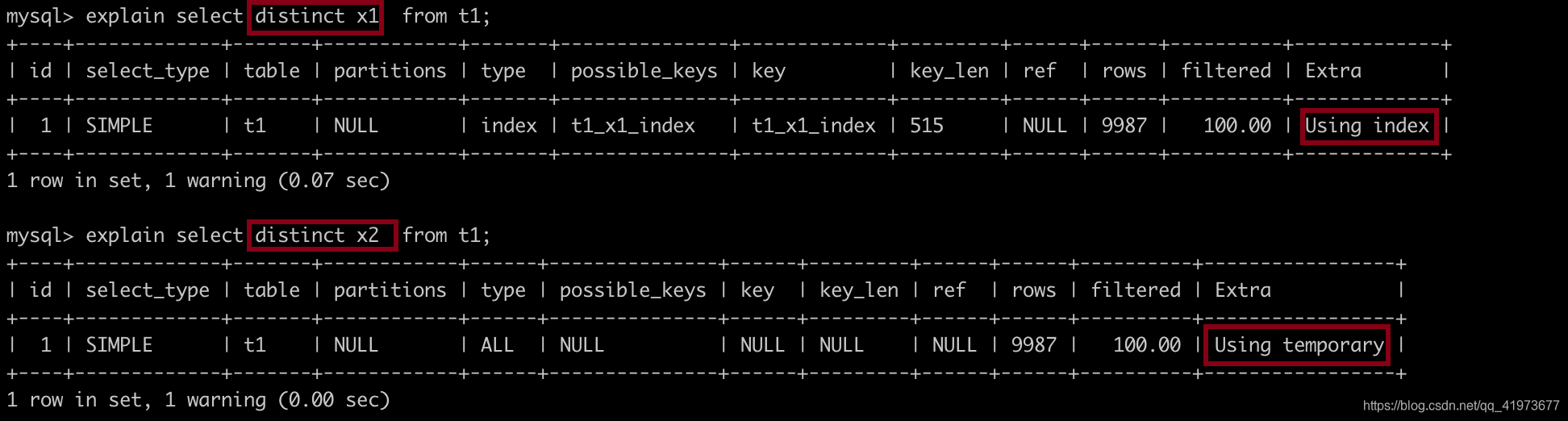
Notice,当你的sql中针对非索引的列进行 group by、distinct、union操作时,它都会通过一张中间表去完成指定操作。而如果对索引列进行group by、distinct、union时,会直接使用索引完成我们的操作。
Case1:
# x1是二级索引
mysql> explain select distinct x1 from t1;
# x2是普通列
mysql> explain select distinct x2 from t1;
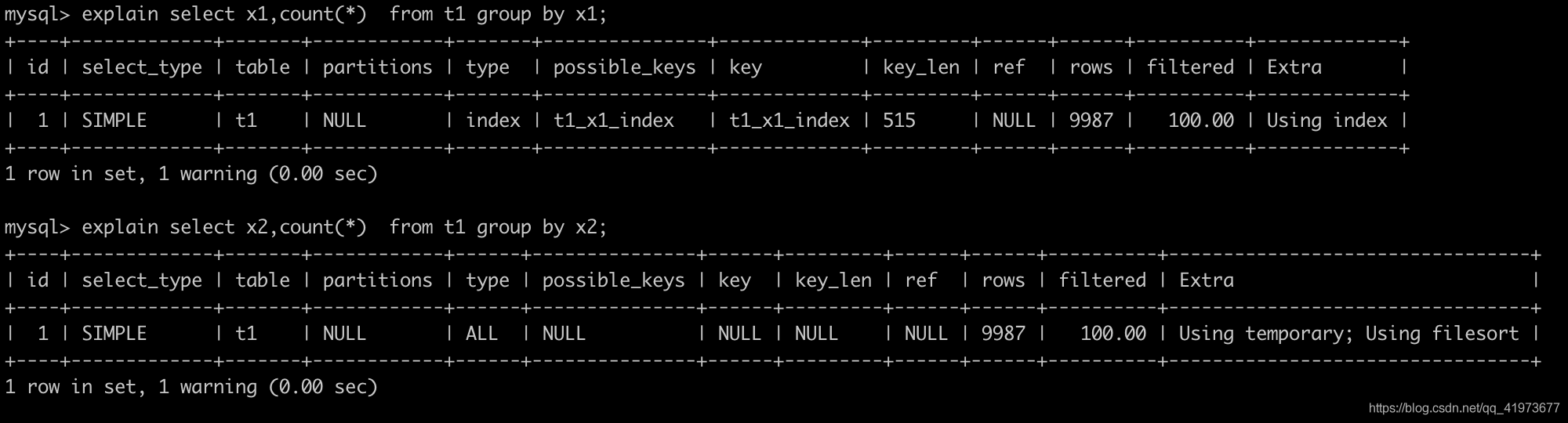
Case2:
# x1是索引列
mysql> explain select x1,count(*) from t1 group by x1;
# x2是普通列
explain select x2,count(*) from t1 group by x2;
三、成本计算
SQL的执行是有成本的,比如读取磁盘的操作远比内存中的操作高的多。而执行计划的作用就是选择一个低成本执行方式去执行我们的SQL。
下面看一种简单的计算SQL执行成本的方式:
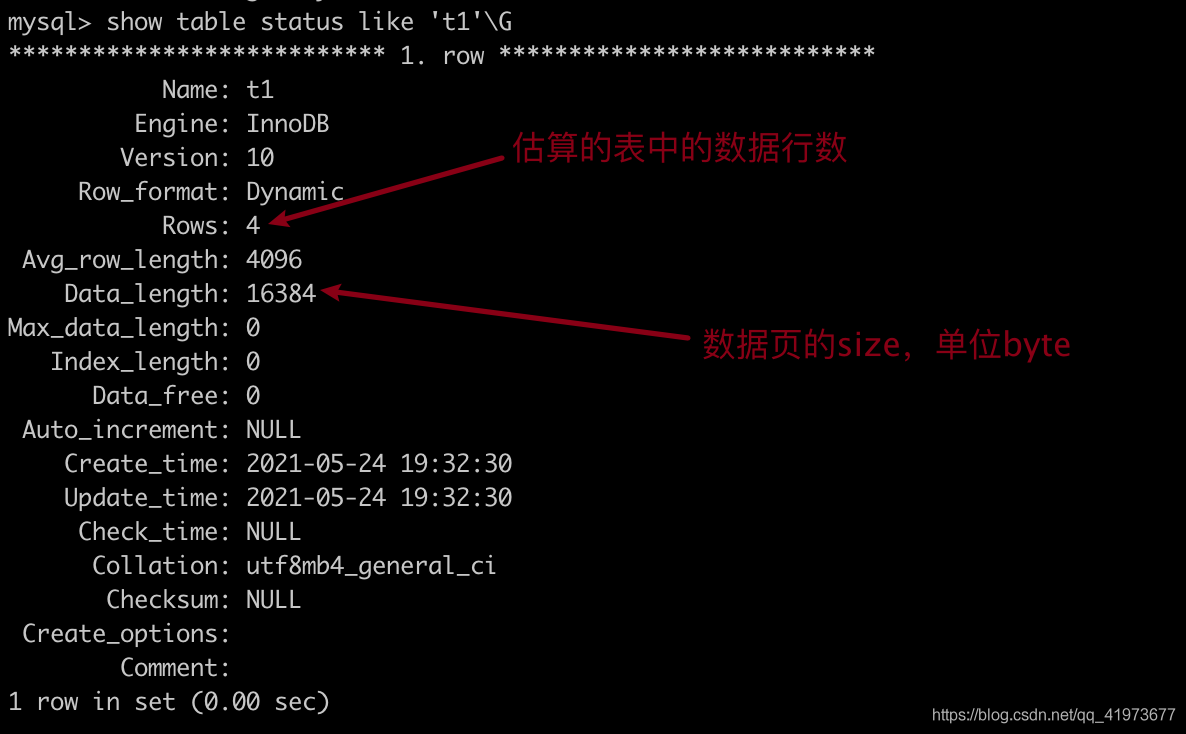
通过如上面的命令可以得到mysql替我们维护的表的统计数据。
其中的rows并不准确,为估算值。data_length/1024/16 为数据页的数量。
全表扫描的成本计算方法如下:
SQL的执行成本 约为 数据页的数量*1.0 + 数据行数*0.2
四、MySQL会改写你的SQL
如果MYSQL认为你的SQL写的不是很好,它会改写优化你的SQL,目的是为了更好的分析得到最优执行计划。
Case1: mysql会去除sql中多余的括号
Case2:
常量替换,如果 `where i=5 and j
select * from t1 join t2 where t1.x1 = t2.x2 and t1.id = 1
比如t1表中有id、x1、x2、x3四列
MySQL的可能按照如下的顺序执行
1.反正t1表中就有1行数据符合预期,那先执行如下SQL,将数据查询出来
select * from t1 where id = 1;
比如查询结果如下
id x1 x2 x3
1 2 3 4
2.使用第一步中查询出来的值,当做常量替换、改写原始sql
select 1,2,3,4,t2.* from t1 join t2 where t2.x2 = 2;
Case4: 如下SQL:
select * from t1 where x1 = (select x1 from t2 where id = xxx);
MySQL执行该SQL时,首先会执行子查询语句,先根据id找到一条数据,取出其x1的值,作为外层sql的常量。然后再执行外层SQL
Case5: ```bash select * from t1 where x1 = (select x1 from t2 where t2.x2 = t1.x2); ```
子查询中的条件又依赖t1表的x2列的值,所以想执行该SQL,就得先遍历t1表,将每一行t1中的x2的值放入到子查询中作为条件,得到子查询的x1后再当做常量作为外层查询的条件。
Case6: 对in语句的优化,如下SQL:
select * from t1 where x1 in (select x1 from t1 where x2 = xxx);
假设t1、t2中各有10万条数据。
MySQL可能会将SQL的执行流程优化成下面这样:
Step1:先执行子查询语句,假设我们从10w条数据中过滤出500条。
Step2:基于memory存储引擎,再内存中,将过滤出的500条数据写入临时表,也叫做物化表,并为他建立索引。如果数据很多内存不够用,也可能以普通B+Tree的方式将其放在磁盘中。
Step3:遍历这个临时表,并将遍历出的x1的值作为条件放在外层sql中,这样就避免了遍历外层sql时需要的10万次遍历了!