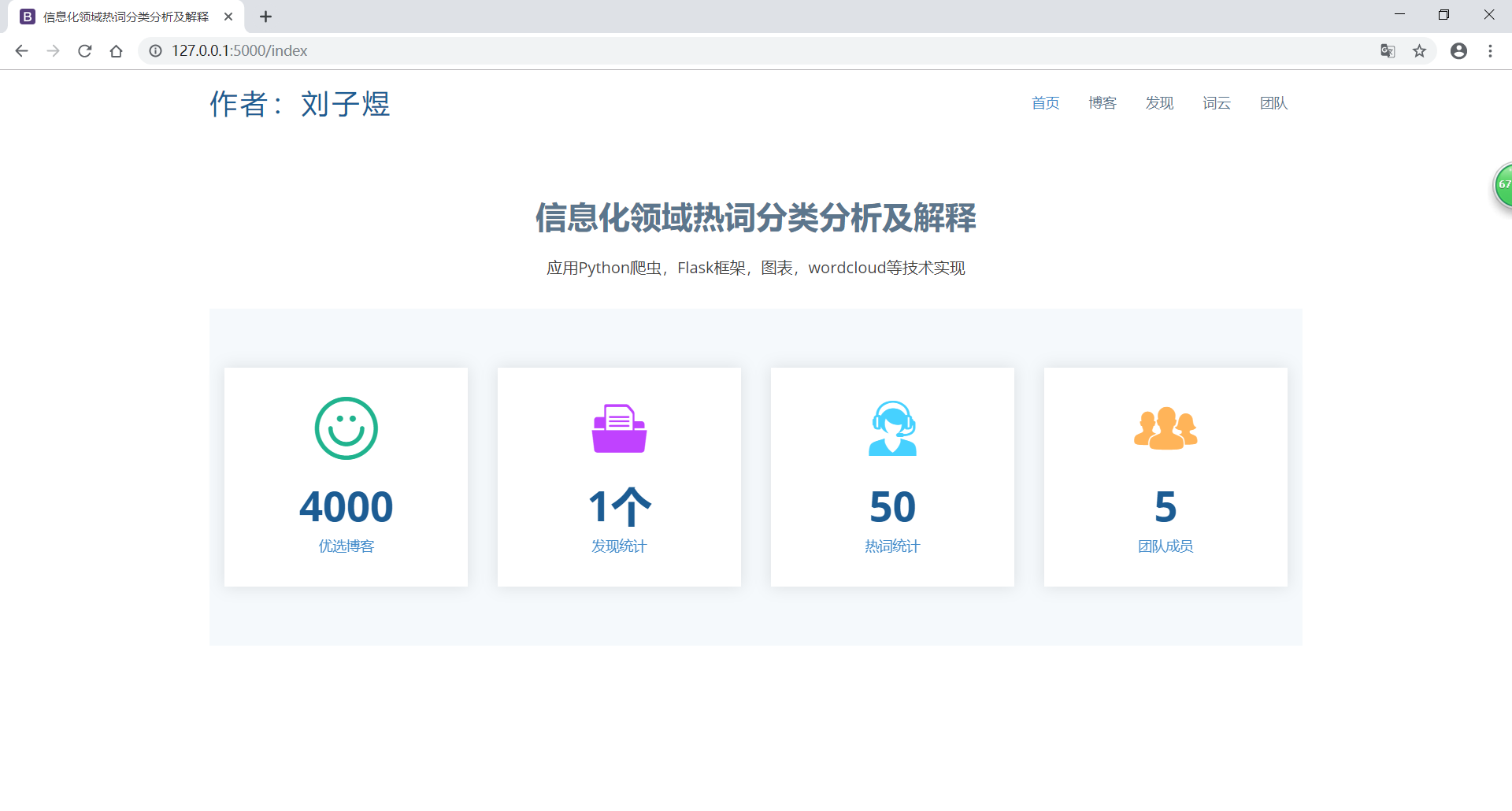
(1) 项目名称:信息化领域热词分类分析及解释
(2) 功能设计:
1) 数据 采集:要求从定期自动从网络中爬取信息领域的相关热
词;
2) 数据 清洗:对热词信息进行数据清洗,并采用自动分类技术
生成信息领域热词目录,;
3) 热 热 词 解释:针对每个热词名词自动添加中文解释(参照百度
百科或维基百科);
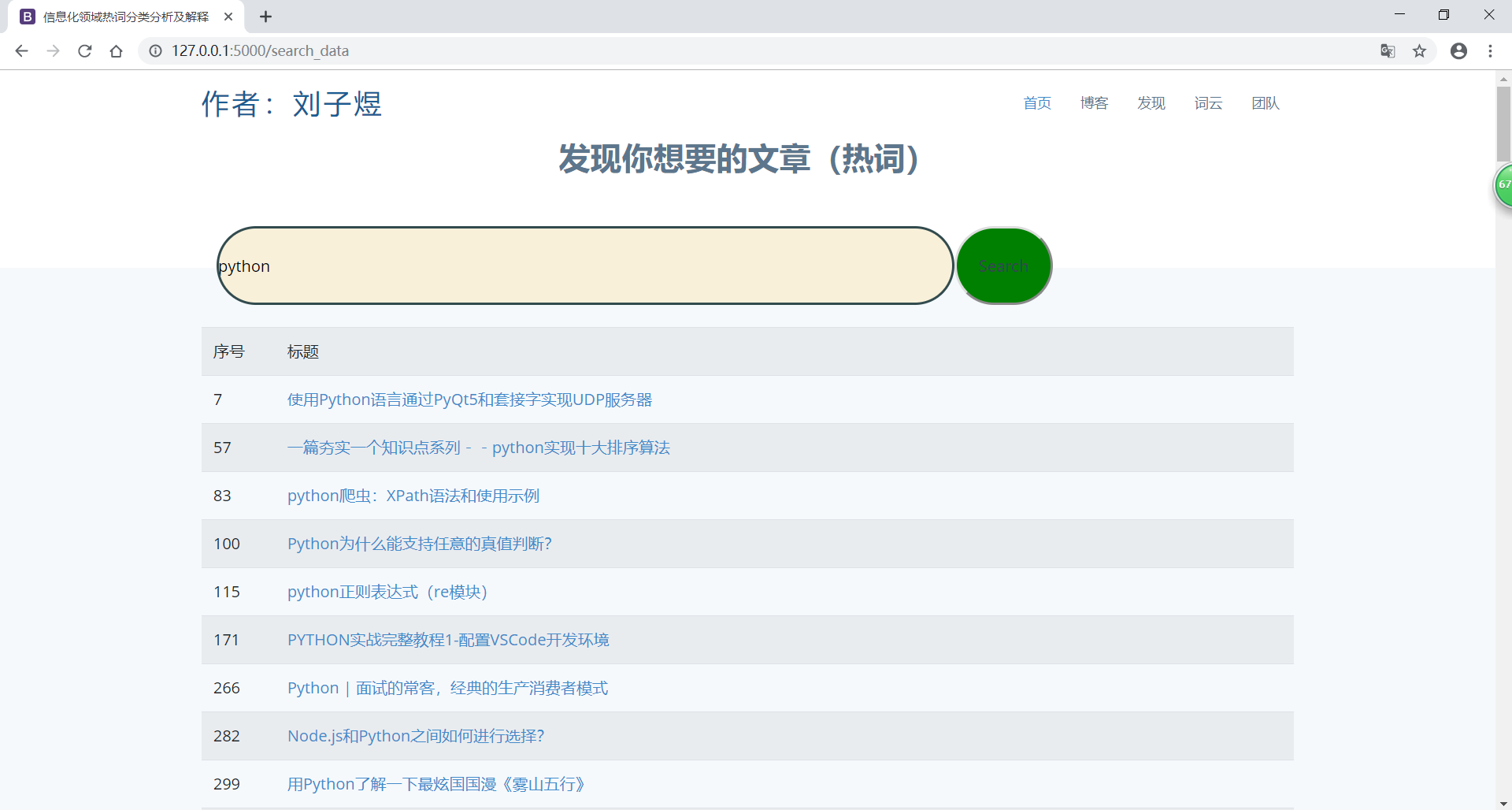
4) 热词 引用 :并对近期引用热词的文章或新闻进行标记,生成
超链接目录,用户可以点击访问;
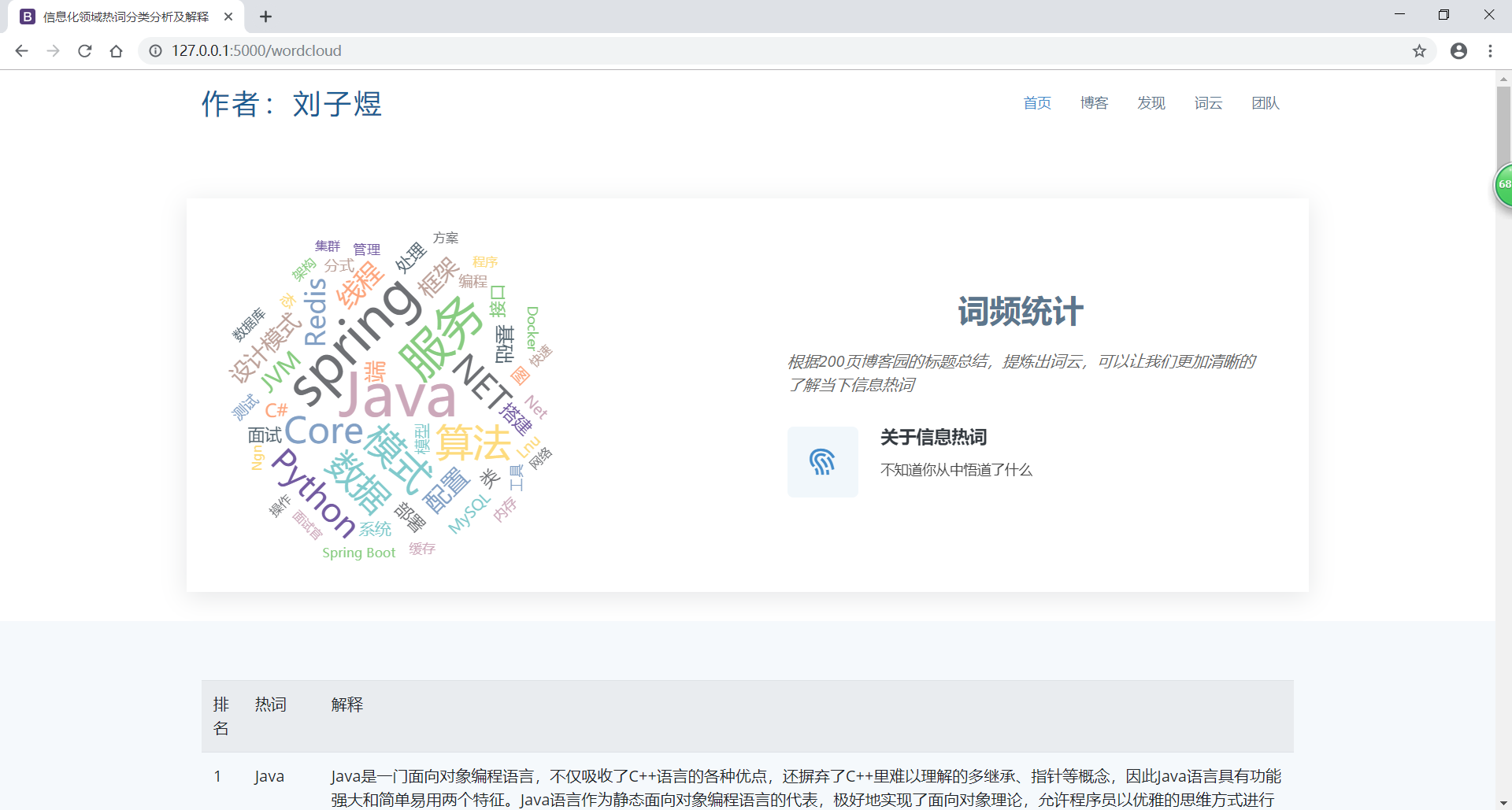
5) 数据 可视化 展示:
① 用字符云或热词图进行可视化展示;
② 用关系图标识热词之间的紧密程度。
6) 数据 报告:可将所有热词目录和名词解释生成 WORD 版报告
形式导出。
显示如下:
项目目录
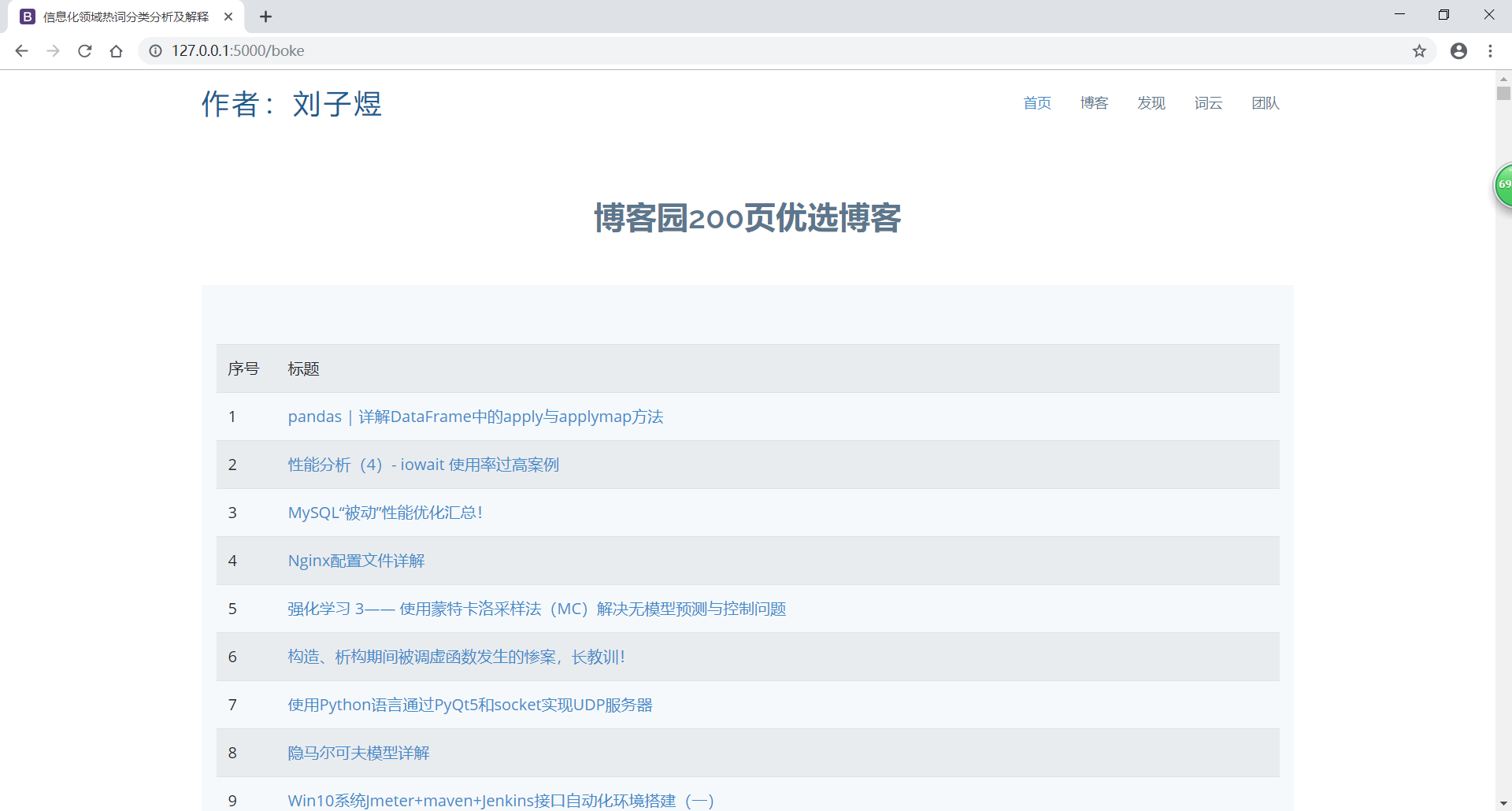
爬取博客园:cnblogs.py
#-*- codeing = utf-8 -*- #@Time : 2020/8/8 22:16 #@Author : 刘子煜 #@File : cnblogs.py #@Software : PyCharm import requests from bs4 import BeautifulSoup import sqlite3 def main(): datalist = getdata() dbpath = "xinxi.db" savedataDB(datalist,dbpath) def getdata(): datalist = [] for index in range(200): print("#"*30,index+1) url = "https://www.cnblogs.com/" data = {"CategoryType":"SiteHome", "ParentCategoryId":0, "CategoryId":808, "PageIndex":index+1, "TotalPostCount":4000, "ItemListActionName":"AggSitePostList" } r = requests.post(url,data=data) # print(r.status_code ) # if r.status_code!=200: # raise Exception() soup = BeautifulSoup(r.text,"html.parser") items = soup.find_all("div",class_="post-item-text") for item in items: data = [] link = item.find("a",class_="post-item-title") # print(link["href"],link.get_text()) data.append(link["href"]) data.append(link.get_text()) datalist.append(data) return datalist def savedataDB(datalist,dbpath): init_db(dbpath) conn = sqlite3.connect(dbpath) cur = conn.cursor() for data in datalist: for index in range(len(data)): data[1] = data[1].replace(""","") data[index] = '"'+data[index]+'"' sql = ''' insert into messagec ( info_link,title) values(%s)'''%",".join(data) # print(sql) cur.execute(sql) conn.commit() cur.close() conn.close() def init_db(dbpath): sql = ''' create table messagec ( id integer primary key autoincrement, info_link text, title text ) ''' # 创建数据表 conn = sqlite3.connect(dbpath) cursor = conn.cursor() cursor.execute(sql) conn.commit() conn.close() if __name__ == "__main__": #当程序执行时 #调用函数 main() #init_db("movietest.db") print("爬取完毕!")
数据处理:app.py
from flask import Flask,render_template import jieba import sqlite3 import urllib.request from flask import request from collections import Counter from bs4 import BeautifulSoup app = Flask(__name__) @app.route('/index') def index(): return render_template("index.html") @app.route('/') def index1(): return render_template("index.html") @app.route('/boke') def boke(): datalist = [] con = sqlite3.connect("xinxi.db") cur = con.cursor() sql = "select * from messagec" data = cur.execute(sql) for item in data: datalist.append(item) cur.close() con.close() print(datalist) return render_template("boke.html",bokes=datalist) @app.route('/search') def search(): return render_template("search.html") @app.route('/search_data',methods=['GET','POST']) def search_data(): # 取出待搜索keyword datalist = [] if request.method=='POST': keyword = request.form['keyword'] print(keyword) con = sqlite3.connect("xinxi.db") cur = con.cursor() sql = "select * from messagec where title like '%"+keyword+"%'" data = cur.execute(sql) for item in data: datalist.append(item) cur.close() con.close() print(datalist) return render_template('search.html',bokes=datalist) return render_template('search.html',bokes=datalist) @app.route('/wordcloud') def wordcloud(): con = sqlite3.connect('xinxi.db') cur = con.cursor() sql = 'select title from messagec' data = cur.execute(sql) text = "" for item in data: text = text + item[0] # print(item[0]) # print(text) cur.close() con.close() word = [] num = [] # 分词 # '十','好','解','功','次','性','优','发','件','9','种','象','以','容','机','间','手','人','级','么', cut = jieba.cut(text) str = ['的', ',', ')', '(', '-', '.', '—', ':', '之', '(', ')', '?', '和', '使用', '实现', '、', '与', '!', '你', '了', '中', '】', '【', '系列', '学习', '如何', '+', '源码', '入门', '我', '开发', '详解', '从', '分析', '实战', '及', '一', '原理', '是', '在', '到', '一个', '问题', '应用', '项目', '基于', ':', '解析', '理解', '--', '篇', '代码', '笔记', '用', '|', '微', '二', '/', '方法', '技术', '深入', '总结', '简单', '上', '教程', '下', '学', '看', '2', '小', '了解', '什么', '1', '个', '不', '3', ',', '[', ']', '_', '多', '《', '》', '说', '一文', '吗', '三', '对', '为什么', '高', '介绍', '「', '」', '---', '带', '创建', '5', '来', '新', '这', '过程', '做', '有', '4', '一次', '&', '个', '@', '让', '知道', '都', '“', '”', '懂', '器', '以及', '解决', '记', '还', '怎么', '生成', '进行', '自己', '10', '问', '一篇', '进阶', '相关', '玩转', '关于', '手把手', '四', '6', '第', '大', '被', '工作', '能', '这么', '就', '7', '利用', '教', '基本', '时', '会', '重', '给', '通过', '热点', '思考', '写', '五', '为', '真的', 'x', '并', '也', '及其', 'three', '8', '分享', '常用', '要', '一起', '2020', '那些', '知识点', '手写', '化', '最佳', '不会', '0', '开始', '从零开始', '最', '师妹', '完', '零', '区别', '轻松', '需要', '指南', '优雅', '去', '任务', '六', '垃圾', '干货', 'i', '持续', '支持', '初识', '搞懂', '年', '我们', '循序渐进', '文', '可能', '这些', '原创', '后', '必备', '解决方案', '整理', '八', '可用'] str1 = ['践', '九', '十', '好', '解', '功', '次', '性', '优', '发', '件', '9', '种', '象', '以', '容', '机', '间', '手', '人', '级', '么', '可', '组', '注', '制', '布', '调', '特', '七', '全', '起', '真', '利', '再', '更', '些', '点', '详细', '引', '需', '自', '信', '其', '们', '讲', '前', '过', '论', '常', '搞', '实', '章', '附', '分钟', '动', '录', '精通', '户', '样', '各', '成', '超', '够', '坑'] string = ' '.join(cut) # 清洗数据 for i in str: string = string.replace(i, "") for j in str1: string = string.replace(j, "") print(string) print(len(string)) # print(string[1]) string1 = string.split() # print(string1[12]) # print(type(string1)) # print(string1) count = Counter(string1) for (k, v) in count.most_common(50): # 输出词频最高的前50两个词 print("%s:%d" % (k, v)) word.append(k) num.append(v) word[1]="spring" word[9] = "Redis" word[40] = "Spring Boot" print(word[40]) introductionlist = [] baseurl = "https://baike.baidu.com/" for i in word: # print(i) string = 'item/' + i string = urllib.parse.quote(string) # 编码 url = baseurl + string # print(url) response = urllib.request.urlopen(url, timeout=30) # 访问并打开url html = response.read() # 创建html对象读取页面源代码 soup = BeautifulSoup(html, 'html.parser') # 创建soup对象,获取html代码 introduction = soup.find_all('div', class_="para") if len(introduction) == 0: print(i + ":没有找到解释!") string2 = ":没有找到解释!" introductionlist.append(string2) print("-" * 30) else: print(i + ":" + introduction[0].get_text()) introductionlist.append(introduction[0].get_text()) print("-" * 30) print(introductionlist[0]) print("^"*30) print(introductionlist[1]) return render_template("wordcloud.html",word=word,num=num,introductionlist=introductionlist) if __name__ == '__main__': app.run()
html就不放出来了,套用的模板,需要的完整的可以联系作者哦。