一、简介
Tachyon是一个高容错的分布式文件系统,允许文件以内存的速度在集群框架中进行可靠的共享,就像Spark和MapReduce那样。通过利用信息继承,内存侵入,Tachyon获得了高性能。Tachyon工作集文件缓存在内存中,并且让不同的Jobs/Queries以及框架都能内存的速度来访问缓存文件”。因此,Tachyon可以减少那些需要经常使用的数据集通过访问磁盘来获得的次数
二、体系结构
Tachyon以常见的Master/worker的方式组织集群,由Master节点负责管理维护文件系统MetaData,文件数据维护在Worker节点的内存中
在容错性方面,主要的技术要点包括:
-
底层支持Plugable的文件系统如HDFS用于用户指定文件的持久化
-
使用Journal机制持久化文件系统的Metadata
-
使用Zookeeper构建Master的HA
-
没有使用replica复制内存数据,而是采用和Spark RDD类似的Lineage的思想用于灾难恢复
三、工作过程
1.初始化文件系统
创建和清空Master/worker所需的工作目录,对Master节点来说这些目录包括底层持久化文件系统上的Data/worker/Journal目录,实际上这里的Worker目录是由Worker节点使用的(用于存放一些零时的持久化文件,丢失Meta信息的数据块等),但是放在Master节点来创建,本质上是为了简化创建逻辑(因为放在HDFS上,只创建一次)对worker节点来说所需的目录就是本地Ramdisk目录,此外,在master的Journal文件夹中,会创建一个特定前缀的空文件用于标志文件系统格式化完毕。
2.Tachyon Master的启动
首先当然是要读取Master相关配置参数,目前都是通过-D参数传给Java的,理想的是通过配置文件来做。目前这些参数,一部分是在Env文件里设置变量,再通过-D参数设置,也有的直接写死在-D参数中的,也有启动脚本中默认未配置,在MasterConf代码里使用了默认值的通过读取特定的format文件判断文件系统是否格式化。
在内存中重建文件系统信息,Tachyon的文件系统信息依靠Journal日志保存,Journal包括两部分,一是meta信息在某个时刻的快照Image,二是增量Log。Tachyon Master启动时首先从快照Image文件中读取文件系统meta信息,包括各种数据节点(文件/目录/Raw表/Checkpoint/依赖关系等)信息,而后再从继续EditLog(可能多个)中读取增量操作记录,EditLog的内容基本对应于Tachyon文件系统Client的一些相关操作,包括文件的添加,删除,重命名,数据块的添加等等。
需要注意的是,这里的Log记录不包括实际的文件内容数据,只是meta信息,所以如果Cache中的文件内容丢失,如果没有持久化,也没有绑定相关lineage信息,那么对应的文件的具体内容也就丢失了。文件系统信息恢复完毕以后,在Tachyon Master正式启动服务之前,Tachyon Master会先把当前的Meta Data写出为新的快照Image。在启用zookeepeer的情况下,standby的Master会定期将Editlog合并并创建Standby的Image,如果没有Standby的Master则只有在启动过程中,才通过上述步骤合并到新的Image中。这里多个Master并发操作Image的editlog,没有Lock或者互斥的机制,不知道会不会存在竞争冲突,数据stale或丢失的问题。
3.文件存储
Tachyon存放在RamDisk上的文件以Block(默认为1G)为单位划分,Master为每个Block分配一个BlockID,Worker直接以BlockID作为实际的文件名在Ramdisk上存储对应Block的数据。
4.数据读写
Tachyon的文件读写,尽可能的通过JavaNIO API将文件直接映射到内存中,做为数据流进行读写操作,目的在于避免在Java Heap中使用大量的内存,由此减小GC的开销,提升响应速度。
读写过程中,所有涉及到Meta相关信息的,都需要通过调用TachyonMaster经由Thrift暴露的ServerAPI来执行,Tachyon的文件读操作支持本地和远程两种模式,从Client API的角度来说对用户是透明的。
读文件的实现,其流程基本就是先从Master处获取对应文件Offset位置对应的Block的ID而后连接本地Worker取得相应ID对应的文件名,如果文件存在,Client端代码会通知Worker锁定对应的Block,而后Client端代码直接映射相关文件为RandomAccessFile直接进行读操作,并不经由Worker代理读取实际的数据。
如果本地没有Worker,或者文件在本地worker上不存在,Client代码再进一步通过Master的API获取相关Block所对应的Worker,而后通过Worker暴露的DataServer接口读取对应Block的内容,在DataServer内部,同样延续锁定对应Block,映射文件的流程读取并将数据返回给Client。另外,基于读数据的时候使用的TachyonFile的API接口,如果使用的是FileStream的接口,当远程Worker也没有对应文件Block时,RemoteBlockInStream还会尝试从底层持久化文件系统层(如果存在对应的文件的话)去读取数据,而ReadByteBuffer接口则没有对应的流程。
Tachyon目前只支持本地写操作,写操作按写入位置可以分为Cache(写到Tachyon内存文件系统中)和Through(写到底层持久化文件系统中)。具体的类型是以上几种情况的合法的组合,如单cache,cache +through等。还有一个Async模式:异步写到底层持久化文件系统中,这个大概是为了优化那些数据需要持久化,但是又对性Latency等有要求的场合。
四、why tachyon
现在为了需求很多框架追求快而使用内存,但是持久化又是一个必须的问题,所以瓶颈就出现在了数据的安全和磁盘I/O了,tachyon就是为了解决这个而产生的
问题1
不同的job要分享数据需要通过磁盘的读写,速度往往是不理想的
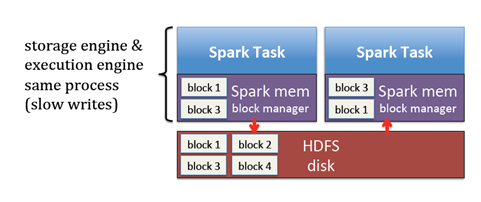
每个job都要复制自己需要执行的block到内存以及相应的垃圾回收
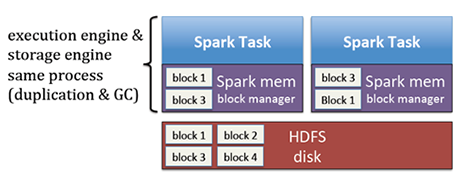
解决上面两个问题
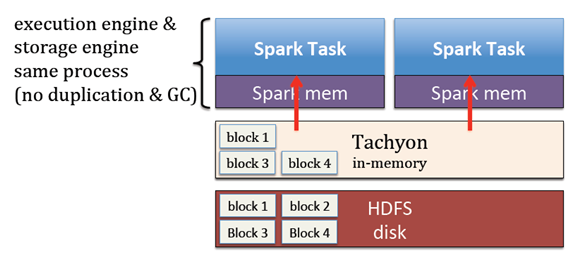
多个job需要用到同一份数据的话,只需要复制一次到Tachyon以及job不需要进行垃圾回收
问题2
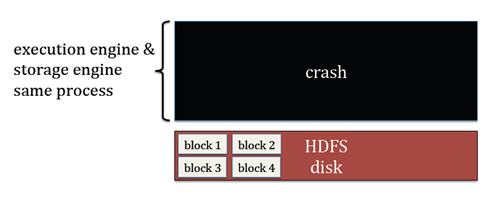
如果excutor执行失败,那么就会丢失该excutor的缓存
解决:
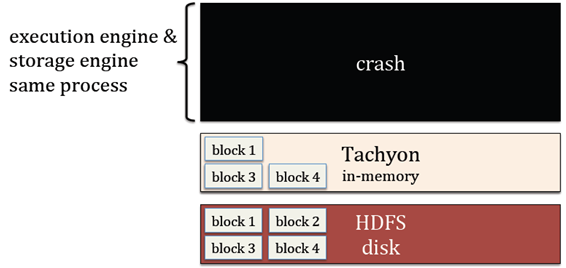
如果excutor挂掉了,缓存可以通过tachyon进行保留
问题3
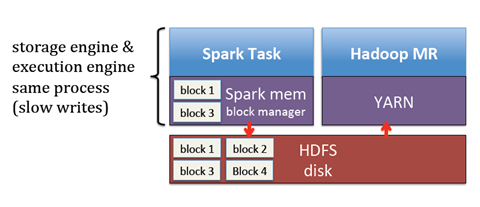
不同的框架之间分享数据也是需要通过读写磁盘
解决:
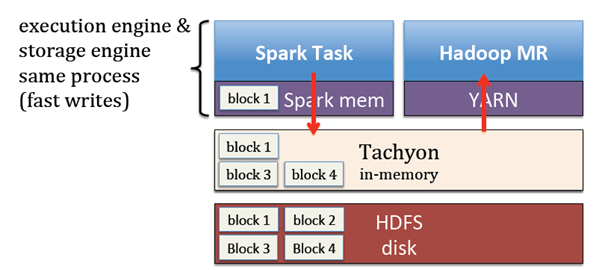
数据处理框架以及HDFS存储框架中加入了tachyon,不同的计算框架之间就可以通过以内存的访问速度对文件进行共享了