一、首先谈一谈zookeeper的选举机制
注:高可用集群中有两台机器作为namenode,无论在任何时候,集群中只能有一个namenode作为active状态,而另一个是standby状态,为了达到namenode快速容错的目的,引入zookeeper后,hadoop-ha可以在active的namenode出问题时由standby自动切换为active状态
特征
leader 投票发起和决议,更新系统状态(只能有一个,否则出现脑裂现象)
follower 参与选举,处理并反馈客户请求
为了保证zookeeper的可用性,集群中至少由3个zookeeper节点组成(确保某一节点死亡可以由选举机制从另外两个节点选出一个作为leader,对外继续提供服务,它的存活条件为半数以上的节点存活)
选举机制如此例:
预设5台: 1、2分别启动后因为未过半都处于观望 3启动后,1、2、3都选择3,数量过半因此3为leader,1、2为follower 4、5启动后因为领导已经产生,则自动沦为follower
二、zookeeper的配置
# 需要提前准备好jdk环境
# 解压步骤省略
# 创建目录:
mkdir zookeeper
# 建立软连接:
ln -s zookeeper345/ zookeeper/
# 创建数据目录:
mkdir zookeeper/zkdata
# 修改zookeeper配置文件:
cd /opt/bigdata/hadoop/zookeeper345/conf
zoo.sample.cfg zoo.cfg--配置信息 tickTime=2000 毫秒,服务器和客户端之间,服务器之间心跳间隔,最小超时为2倍 initLimit=10 follower启动后与leader之间同步数据,并且确定可以对外服务状态的最大时限为10*tickTime syncLimit=5 follower和leader之间如果在syncLimit*tickTime时间内无法通过心跳确认,则leader判定该follower死亡,移出服务列表 dataDir=/opt/bigdata/hadoop/zookeeper/zkdata clientPort=2181 server.1=vwmaster:2888:3888 server.2=vwslave01:2888:3888 server.3=vwslave02:2888:3888 server.4=vwslave03:2888:3888
# 在zkdata目录中创建myid文件,并将当前host下对应的服务器编号1/2/3/4存在其中
# 配置环境变量:
export ZK_HOME=/opt/bigdata/hadoop/zookeeper345
export PATH=$ZK_HOME/bin:$ZK_HOME/sbin:$PATH
# 激活环境变量:
source /etc/profile
[root@vwslave01 ~]# zkServer.sh start
三、高可用原理
在高可用集群中有两个namenode,其中一个为active,另一个作为standby,active的namenode负责集群中所有的客户端操作,而原来的secondaryNamenode也不需要了,数据交互由轻量级进程journalNode完成,对于任何由主namenode的修改操作,standby的namenode监测到之后会同步journalnode里面的修改log,当active namenode挂了后会读取journalnode里面的修改日志,接替它的位置并保证数据的同步。
而namenode的健康状态的判定由zookeeper决定,在每个namenode启动时,会在zookeeper上注册一个持久化节点,而zookeeper提供一个znode(独占锁)获取master的功能,两个namenode谁得到谁就是active状态,另一个保持standby,实际工作中hadoop会提供一个ZKFailoverControl角色在每个主节点周期性的探测namenode的健康状态,当它出问题了独占锁将会给备份的namenode代替原来的主机负责其职责
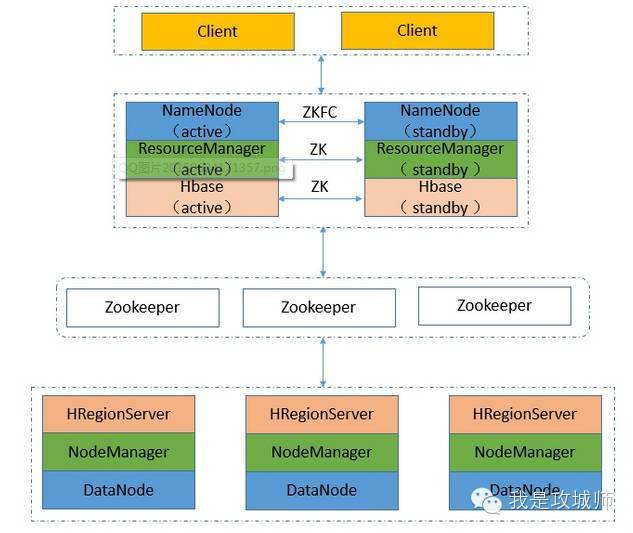
四、搭建方法
关于NameNode高可靠需要配置的文件有core-site.xml和hdfs-site.xml
关于ResourceManager高可靠需要配置的文件有yarn-site.xml
时间同步
本地时钟服务器搭建
rmp -qa|grep ntp
yum -y remove ntpdate-4.2.6p5-29.e17.centos.x86_64
安装ntp yum -y install ntp
修改所有节点的/etc/ntp.conf
restrict 20.0.0.100 nomodify notrap nopeer noquery //当前节点ip
restrict 20.0.0.2 mask 255.255.255.0 nomodify notrap //集群所在网段网关Gateway,子网掩码Netmask
主节点
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
server 127.127.1.0
Fudge 127.127.1.0 stratum 10
从节点
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
server 20.0.0.100 //主节点ip
Fudge 20.0.0.100 stratum 10
启动ntp服务 service ntpd start
设置开机启动 chkconfig ntpd on
查看 ntpstat
以下配置均为hadoop260/etc/hadoop目录下
注:提前在hadoop260下建目录data(cd data, mkdir pids journalnode)
hadoop core-site.xml配置
<configuration>
<!--设定集群访问路径:kbcluster-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://kbcluster</value>
</property>
<!--设定临时目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/hadoop/hadoop260/data/tmp</value>
</property>
<!--设定zookeeper集群目录-->
<property>
<name>ha.zookeeper.quorum</name>
<value>vwmaster:2181,vwslave01:2181,vwslave02:2181,vwslave03:2181</value>
</property>
</configuration>
hadoop hdfs-site.xml
<configuration>
<!--设定文件块备份数-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--设定集群服务名称:kbcluster-->
<property>
<name>dfs.nameservices</name>
<value>kbcluster</value>
</property>
<!--设定集群kbcluster的namenode自定义名称列表-->
<property>
<name>dfs.ha.namenodes.kbcluster</name>
<value>nn1,nn2</value>
</property>
<!--分别设定所有namenode名称列表的rpc访问地址-->
<property>
<name>dfs.namenode.rpc-address.kbcluster.nn1</name>
<value>vwmaster:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.kbcluster.nn2</name>
<value>vwslave01:9000</value>
</property>
<!--分别设定所有namenode名称列表的http访问地址-->
<property>
<name>dfs.namenode.http-address.kbcluster.nn1</name>
<value>vwmaster:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.kbcluster.nn2</name>
<value>vwslave01:50070</value>
</property>
<!--设定所有节点的共享编辑日志journal地址列表-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://vwmaster:8485;vwslave01:8485;vwslave02:8485;vwslave03:8485/kbcluster</value>
</property>
<!--设定隔离方法名称:即同一时刻只能有一台服务器对外响应--->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--使用隔离机制是需要私钥进行无秘访问-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--设定journal节点存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/bigdata/hadoop/hadoop260/data/journalnode</value>
</property>
<!--关闭权限检查-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!--启动client访问失败动态代理-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--设置client访问失败自动切换代理-->
<property>
<name>dfs.client.failover.proxy.provider.kbcluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
</configuration>
hadoop yarn-site.xml
<configuration>
<!--设置nodemanager附属服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--启用resourcemanager的高可用(ha)集群-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--启用resourcemanager的集群标识-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>kbcluster-yarn</value>
</property>
<!--启用resourcemanager(ha)集群的resoucemanager名称列表-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--分别设置resourcemanager(ha)集群的resoucemanager名称的hostname-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>vwmaster</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>vwslave01</value>
</property>
<!--设置resourcemanager(ha)集群的zookeepr集群地址列表-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>vwmaster:2181,vwslave01:2181,vwslave02:2181,vwslave03:2181</value>
</property>
<!--启用resourcemanager(ha)集群可恢复功能-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager(ha)集群的状态信息存储在zookeepr集群-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
初始化hadoop ha集群
分别启动所有节点上的journalnode服务 hadoop-daemon.sh start journalnode
nn1上格式化 hdfs namenode -format hadoop-daemon.sh start namenode(启动主节点)
nn2上同步nn1上的元数据信息 hdfs namenode -bootstrapStandby hadoop-daemon.sh start namenode #启动后通过网页测试
nn1上启动hadoop ha集群 start-all.sh
单独启动nn2上的resourcemanager yarn-daemon.sh start resourcemanager
网页上可查状态 ip:50070
图片来源博客:https://cloud.tencent.com/developer/article/1121864