原文:http://blog.sina.com.cn/s/blog_6203dcd60100xvky.html
【第十阶段 : 数据存储优化】
在前面的阶段中,我们都使用数据库作为默认的存储引擎,很少谈论关于关于数据存储的话题。但是,数据的存储却是我们现在众多大型网站面临的最核心的问题。现在众多网络巨头纷纷推出自己的“高端”存储引擎,也吸引了众多的眼球。比如:google的BigTable、facebook的cassandra、以及开源的Hadoop等等。国内众多IT巨头也纷纷推出自己的“云”存储引擎。
其实这些存储引擎用的一些关键技术有许多的共性,比如:Meta信息管理、分片、冗余备份、数据自动恢复等。因为之前我也做过一些工作和研究,但是不是特别深入,不敢在此指手画脚、高谈阔论。相关的资料网上比比皆是,大家有兴趣有search吧。^_^
关系型数据库常用的有几个,比如:MySQL、PostgreSQL、SQLServer、DB2等,当然还有NB的Oracle(唉,作为DB科班出生的屌丝,没有真正意义上使用过这样的高帅富数据库,惭愧啊)。
互联网使用频率最高的应该要算是MySQL。最重要的是开源;其次是他提供的一些特性,比如:多种存储引擎、主从同步机制等,使用起来非常的方便;再次,就是一个单词:LAMP,几乎成为搭建网站的必备利器;还有,较高服务的稳定性。
关系型数据使得建立网站变得及其轻松,几乎是个网站都会有一个数据库。试想一下,如果没有这种通用的关系型数据库,我们的生活会是怎么样的?
关系型数据库在95%的场景下是工作的非常好的。而且只要配置得当、数据切分合理、架构设计符合要求,性能上是绝对能够承受业务的需求。现在很多大型网站的后台,几乎都是数据库作为标准的存储引擎。
另外,最近炒的比较热的一个概念就是NoSQL。说起来,其实就是放弃关系型数据库中许多的特性,比如:事务、外键等等。简化设计,将视线更关注于存储本身。比较有名的,比如:BDB、MongoDB、Redis等等。这些存储引擎提供更为直接的Key-Value存储,以满足互联网高效快速的业务需求。其实,从另外一个角度来看,关系型数据库(比如MySQL),如果不使用那么多的关系型数据库特性,也可以简化成KV模式,提升效率。
不过,有些时候,为了节省机器资源,提升存储引擎的效率,就不得不开发针对业务需要的专用存储引擎。这些存储引擎的效率,往往较关系数据库效率高10-100倍。比如,当一个图片服务,存储的图片量从1亿到10亿,甚至100亿;现在流行的微薄,假如发布总量达到10亿或者100亿。这样级别的数据量,如果用数据库来存储固然可以,但是有可能需要耗费相当多的机器,且维护成本和代价不小。
其实分析我们通常的业务,我们对数据的操作无非就是四个:查、插、删、改。对应数据库的操作就是select、insert、delete、update。那自己设计的存储引擎无非就是对这四个操作中的某几个做针对性的优化,让其中几个根据不同的业务特点,使其变的更加的高效。比如:对于微薄而言,可能就需要插入和查询具有很高的效率,而删除和修改的需求不是那么高。这个时候,就可以牺牲一部分删除和修改的性能,而重点放在插入和查询上。
在业务上,我们的提交通常可以看作在某一个维度上是有序的。比如,每一个微薄或者博客可能都会有一个id,这些id可能是按照序列递增、或是时间递增等。而查询的时候,则是按照另外一个维度的顺序组织的,比如:按关注的人组织微薄的信息。这样就造成了一个冲突,就是提交的组织顺序和查询的组织顺序不一致。
再来看看我们的磁盘。我们现在常规磁盘还是机械方式运转的:有盘片、有磁头等等。当需要写入或者读取的时候,磁头定位到不同的盘片的不同扇区上,然后找到或修改对应的信息。如果信息分散在不同的盘片、扇区上,那么磁头寻道的时间就会比较长。
反过来,我们再来看看我们的业务和磁盘的组织。A、如果我们按照写入有序的方式存储数据,那么磁盘会以很高的效率,将数据连续的写入到盘片中,无需多次寻道。那么读取的时候,可能就会出现按照另外的维度来组织数据,这样就有可能需要在多个地方来读取。从而造成我们磁盘来回寻道定位,使得查询效率低下。B、如果我们按照某一种查询维度来存储数据(因为同一业务往往有多种查询模式),那读取的时候,就让磁盘顺序读取即可。但带来的麻烦就是,写入的时候有可能需要反复的寻道定位,将提交的数据一条条写入。这样就会给写入带来麻烦。
其实矛盾的主体就是:僵化的磁盘存储方式不能满足网站日益增长的提交和查询需求!
是否有解决方案呢?那必须有!
要解决这个问题,可以从两方面入手。
1、改变现有的磁盘存储方式。随着硬件快速的发展,磁盘本身的效率得到了极大提升。磁盘的转速,盘片的个数等都大幅增加,本身寻道的速度提升很快。加上缓存等的加强,效率提升还是很明显。另外,Flash Disk、Solid State Disk等新技术的引入,改变了原来的随机读取的低效(没有数据,根据经验,Flash或SSD的效率可以达到10-100倍普通硬盘的随机访问的效率)。
2、根据不同的业务,有效的组织数据。比如微薄(我没有写过微薄,但是做过微薄类似的东东),因为读取业务组织的维度是按人,而提交组织的维度则是时间。所以,我们可以将某个人一段时间提交的数据,在内存里面进行合并,然后再一次性的刷入到磁盘之中。这样,某个人一段时间发布的数据就在磁盘上连续存储。当读取的时候,原来需要多次读取的数据,现在可以一次性的读取出来。
第一点提到的东东现在也逐步的开始普及,其实他给我们的改变是比较大的。不用花太多的精力和时间,去精心设计和优化一个系统,而只需要花一些钱就能使得性能大幅提升,而且这样的成本还在降低。
但是,资源永远是不够的。多年前,当内存还是64K的时候,我们畅想如果内存有个32M该多美妙啊。但是,随着数据的膨胀,即使现在64G内存,也很快就不能满足我们的需求。
所以,在一些特殊的应用下面,我们还是需要更多的关注第二个点。
对于存储优化,一直是一个持久的话题,也有很多成熟的方案。我这里可能提几个点。
(到饭点了,先吃饭。:D)
好了,午觉后,沐浴在阳光和春风中,继续数据存储优化的话题。
先来看一张简单的架构图:

上面这张图比较简单的表明了从软件到硬件的一个层次关系,其中括号里面的部分只是一个举例。比如,用户程序blog要读取一个数据,使用了c标准库stdio中的fread函数,fread去调用操作系统提供的接口read函数,read再通过sys_read等一系列的深入调用,到最下层操作磁盘。
我们对于数据存储的优化,实际上就是这样一个过程,每一步的优化。
为了更好的说明问题,我们拿简化的微薄做例子。因为在微薄的实现中有推和拉两种实现方案。针对我们这里要举例的内容,我们就用“拉”的实现方式来讨论(说明:推的方式就是用户发微薄的时候,就把数据推到关注者的队列中,访问的时候直接就可以展示;拉的方式就是发微薄的时候只记录在发送者的队列上,展示的时候再从被关注者队列里获取数据。两种方式各有优劣,不在此赘述。)。
我们假定就实现这样的一个功能:用户提交微薄,用户可以浏览自己关注人的微薄。具体的数据定义如下:
1、用户就只有一个属性:struct user {uint32 uid};
2、微薄就只有两个属性:struct mblog {uint64 mbid, char content[32] };
3、一个用户可以发多个微薄:struct user_mb {uint32 uid, uint64 mbid};
4、用户间可以相互关注:struct user_follow {uint32 uid1, uint32 uid2};
有了上述的定义,为了更简洁的说明存储的优化,我们只关注一个点:用户微薄数据的存储。
用户随时间推移不断的提交微薄数据。如果我们按这样的顺序来存储数据,我们可以利用磁盘高效的顺序读写性能来实时写入磁盘。不过,当我们要读取时就犯难了。请看下图:
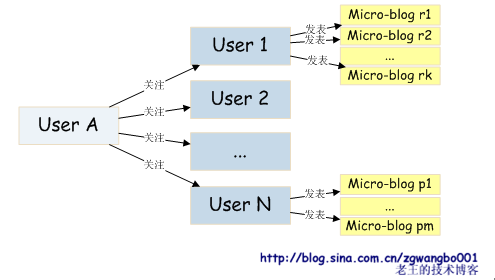
我们这个时候就需要从磁盘当中去搜寻被关注人发的博客。假定平均每个用户关注了10个用户,且平均每个用户发微薄数目为100个。另外,假设我们一页展示30个微薄,那么,访问第一页的时候(注意,这里为了简化,强调的是第一页),我们就需要去读取300次磁盘,然后将数据进行排序。这个处理的开销,实在是难以接受。(当然,我们也有许多折衷的处理方法,我们可以记录最近有更新的用户按时间排序,然后按顺序拉取;或者我们用更为压缩的方法,先读取出时间摘要,先排序,再读取实际的内容。不过这个就不在这里介绍。)
那我们来看如何优化。如果我们能将同一个用户在一段时间内发送的数据,在内存中进行合并,比如,User 1今天发的微薄,我们在内存中先合并,形成一条拉链:mbr1->mbr2->…->mbrk,等到半夜访问量降低的时候,或者内存快满的时候,我们再集中的一次性写入到磁盘中。然后在磁盘中形成该用户一段时间连续的数据。假如一个用户平均一天发送微薄数为10个,那么我们这样做了合并以后,同一个用户的10个微薄就会连续的写入到磁盘中。那读取第一页的时候,一个用户的数据只要读3次,这样我们就减少了一个数量级的访问次数。如果为了得到更好的效果,我们可以将多个这样的磁盘数据,做定期的合并,这样可以更好的减少访问次数,有可能把同一用户的访问次数压缩到1次。
不过,有一个问题,因为我们一天提交的数据都放在内存中。如果某个时刻机器宕机了,我们的数据岂不是就丢了?
那我们还需要引入数据回放机制。我们需要一个redo log,用于记录每一个发微薄的动作,另外,加上一个check point,用于记录上次写盘后的有效记录点。当程序重启以后,我们就从check point开始,回放我们的log,就可以恢复内存结构。
其实这个技术也是业界比较成熟的一个技术。在Mysql中,数据也不是实时写盘的,而是有数据合并的过程。也有通过这样的方式来做优化。在更为高级的“云”存储中,这个技术也是广泛使用。
说到这里,就稍微的描述一下几个文件读写的函数:fread、fwrite、fseek、fflush、read、write、lseek、pread、pwrite、flush,这些函数带f开头的,是std标准库中提供的函数,在库级别做了缓存,以提升效率。但是带来的问题就是,你不知道数据什么时候被写入,可控性较差。不带f的,则是操作系统提供的系统调用,你可以认为调用了这些函数以后,数据就被写入了。但是实际上,这些函数也是有缓存的,也并不是实时写入的。操作系统会根据系统的运行状态来按照一定策略来将内存中的数据刷回到磁盘中。比如,linux里面的按脏页比例刷回等就是策略之一。另外,还有一种访问方式,叫做Direct IO。这种方式可以认为是实时读写磁盘,没有缓存。但是要求我们的内存buffer和磁盘的分页是对齐的。
好,假定我们已经开发出这样一个优化的微薄存储系统,但是这个系统还是单机的。How to work?
其实我们可以有多种方式。还记得我们之前提过的数据库多机化的方案嘛?实际上这个也是一样的。
1、仿照mysql等数据库的实现方式,实现一套主从同步的机制;
2、如果只针对mysql,可以做成mysql的一种存储引擎,让mysql来帮你实现数据的同步(其他数据库没怎么样研究过);
3、利用Message Queue,实现消息的多机分发。
其实上面几种方案都是可行的,为了降低成本,我比较喜欢第三种方案。就是利用消息队列来转发数据。但是有一个问题就是CAP原理:不同机器之间的数据不能做到强一致性,最多只能到达最终一致性。
修改后的数据存储架构就变成下面的样子:

其实,数据存储优化是一个很深的话题。如果真正要比较详细的来写这一部分,可以写出《算法导论》那么厚一本书。我这里只是很皮毛的做了一个介绍。关键的一个点就是,分析清楚业务的需求,按照读写分离的原则,对读写进行折衷,达到一种平衡。
(今天是泰坦尼克沉没100周年,不由得想起重新听听当年的经典曲目:My heart will go on)
