最近几天怪事儿出奇的多,同一个工单、同一个产品,在A线可以正常生产,但是在H线死活都无法生产,系统直接提示TimeOut,监控发现有一条SQL语句执行缓慢,Copy出来仔细查看,很简单的一条语句,如下:
SELECT TOP 1 LOT_ID FROM QS_WIP(NOLOCK) WHERE STATION_ID='FB808A1E-5758-43B3-B243-8C728ACC5264' AND ROUTE_STEP_ID='29F813DC-2204-4413-9FB6-0DBF1982F33F' order by END_TIME desc
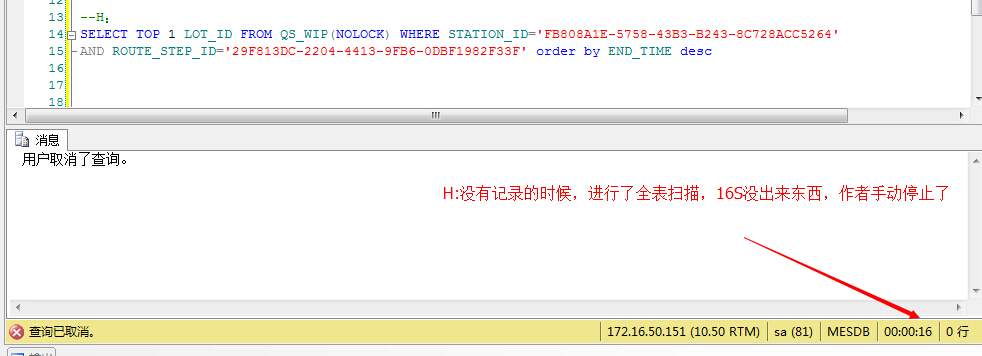
看似简单的SQL语句,却执行了10多S还没结果出来,表中STATION_ID与ROUTE_STEP_ID都是有索引的,理论上不应该啊,于是还是等着SQL执行完毕(当时没截图,要1分钟,不敢再次执行了),发现结果是空,如下图所示:
我们再看另一条SQL语句,跟上面的语句唯一不同的就是不同的STATION_ID,如下:
SELECT TOP 1 LOT_ID FROM QS_WIP(NOLOCK) WHERE STATION_ID='40D83B4A-9BC3-4FE0-BE53-65685402AB2E' AND ROUTE_STEP_ID='29F813DC-2204-4413-9FB6-0DBF1982F33F' order by END_TIME desc
这条语句执行速度很快,如下:
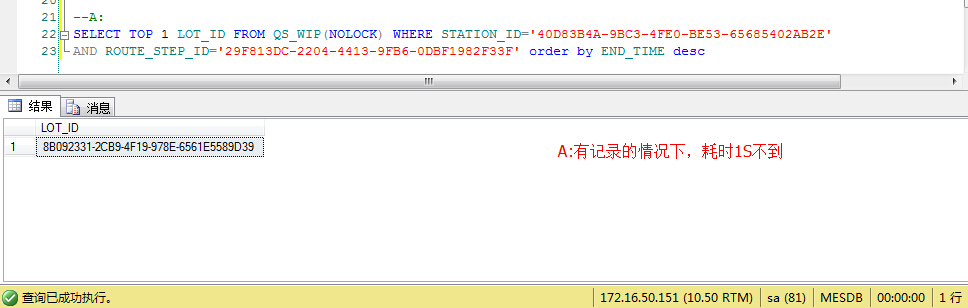
结果返回了实际的数据,难道是数据为空的原因吗?那好,我手动增加一条符合条件的H线数据,增加数据之后,再次执行第一条SQL,如下:
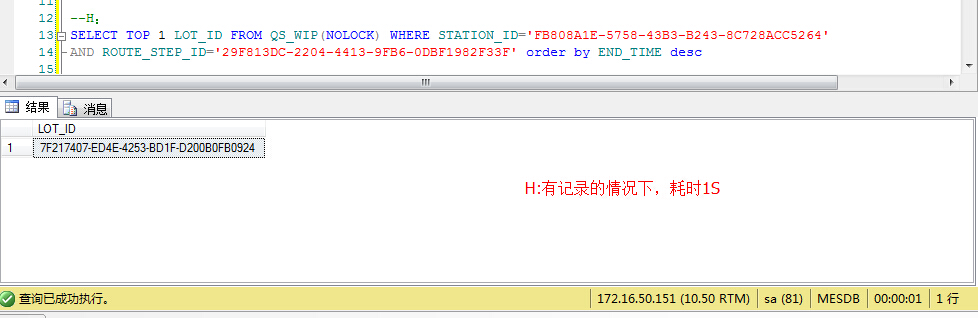
结果显示,1s的时间就出来,看来真是这个问题导致。
分析一下结果:
有一个比较重要的因素,那就是目标表中的数据量比较大,有100000000+的记录,虽然在查询的时候加上了TOP 1,但是在没有符合条件的数据的情况下,将对整个表进行全表扫描,也就是对100000000+的记录进行扫描,那一定会很慢,即便加了索引也一样,因为找不到符合条件的数据,那就一直找,直到找到数据为止;
相反,只要有一条符合条件的数据,那么TOP 1的时候找到了这一条符合条件的记录,将不再继续扫描表中其它的数据,所以速度快。