有的时候,一些时刻或连续时间段内的值无法采集到,或者本身就没有值,本文将介绍如何处理这种情况。
一般而言,有以下几种方法:
- 对所有的缺失值用零填充。
- 前向填充:比如用周一的值填充缺失的周二的值
- 后向填充:比如用周二的值填充缺失的周一的值
- 采用n最近邻均值法填充:比如n取2,则用t-2,t-1,t+1,t+2时刻的平均值来填充缺失的t时刻的值。
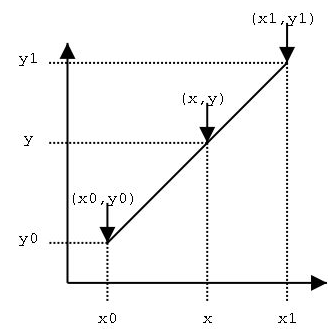
- 单线性插值:取某个缺失值的时间点,做一条垂线相较于左右时刻的值的连接线,得到的交点作为填充值。类似下图:
对应的python代码实现:
from sklearn.metrics import mean_squared_error
df_orig = pd.read_csv('https://raw.githubusercontent.com/selva86/datasets/master/a10.csv', parse_dates=['date'], index_col='date').head(100)
df = pd.read_csv('datasets/a10_missings.csv', parse_dates=['date'], index_col='date')
fig, axes = plt.subplots(7, 1, sharex=True, figsize=(10, 12))
plt.rcParams.update({'xtick.bottom' : False})
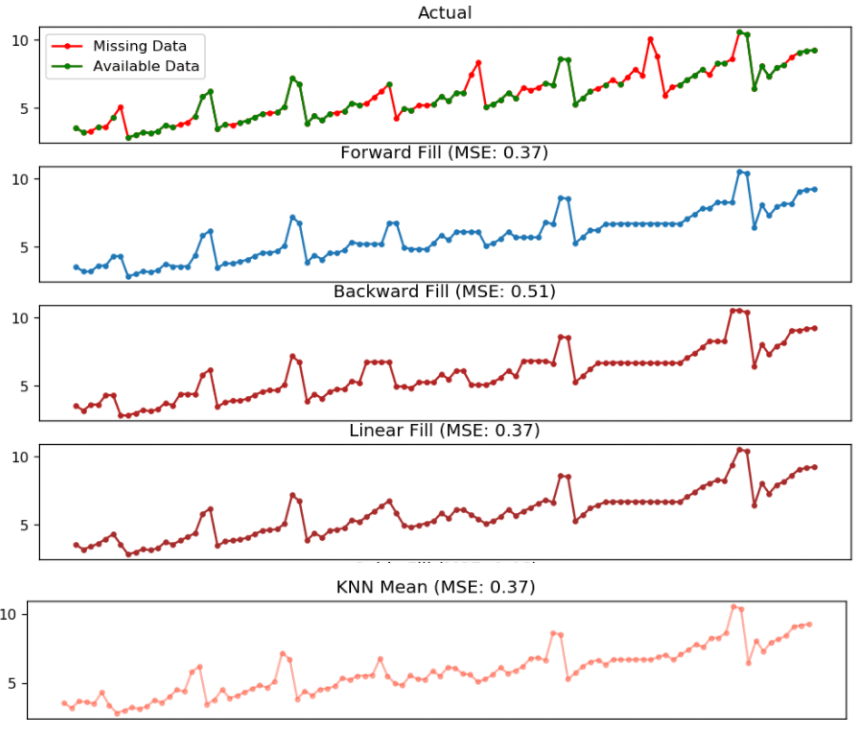
## 1. Actual -------------------------------
df_orig.plot(title='Actual', ax=axes[0], label='Actual', color='red', style=".-")
df.plot(title='Actual', ax=axes[0], label='Actual', color='green', style=".-")
axes[0].legend(["Missing Data", "Available Data"])
## 2. Forward Fill --------------------------
df_ffill = df.ffill()
error = np.round(mean_squared_error(df_orig['value'], df_ffill['value']), 2)
df_ffill['value'].plot(title='Forward Fill (MSE: ' + str(error) +")", ax=axes[1], label='Forward Fill', style=".-")
## 3. Backward Fill -------------------------
df_bfill = df.bfill()
error = np.round(mean_squared_error(df_orig['value'], df_bfill['value']), 2)
df_bfill['value'].plot(title="Backward Fill (MSE: " + str(error) +")", ax=axes[2], label='Back Fill', color='firebrick', style=".-")
## 4. Linear Interpolation ------------------
df['rownum'] = np.arange(df.shape[0])
df_nona = df.dropna(subset = ['value'])
f = interp1d(df_nona['rownum'], df_nona['value'])
df['linear_fill'] = f(df['rownum'])
error = np.round(mean_squared_error(df_orig['value'], df['linear_fill']), 2)
df['linear_fill'].plot(title="Linear Fill (MSE: " + str(error) +")", ax=axes[3], label='Cubic Fill', color='brown', style=".-")
## 5. Mean of 'n' Nearest Past Neighbors ------def knn_mean(ts, n):
out = np.copy(ts)
for i, val in enumerate(ts):
if np.isnan(val):
n_by_2 = np.ceil(n/2)
lower = np.max([0, int(i-n_by_2)])
upper = np.min([len(ts)+1, int(i+n_by_2)])
ts_near = np.concatenate([ts[lower:i], ts[i:upper]])
out[i] = np.nanmean(ts_near)
return out
df['knn_mean'] = knn_mean(df.value.values, 8)
error = np.round(mean_squared_error(df_orig['value'], df['knn_mean']), 2)
df['knn_mean'].plot(title="KNN Mean (MSE: " + str(error) +")", ax=axes[5], label='KNN Mean', color='tomato', alpha=0.5, style=".-")
ok,本篇就这么多内容啦~,感谢阅读O(∩_∩)O。