题目:
使用MobaXterm连接(当然也可以使用别的软件进行连接,用的顺手就行)
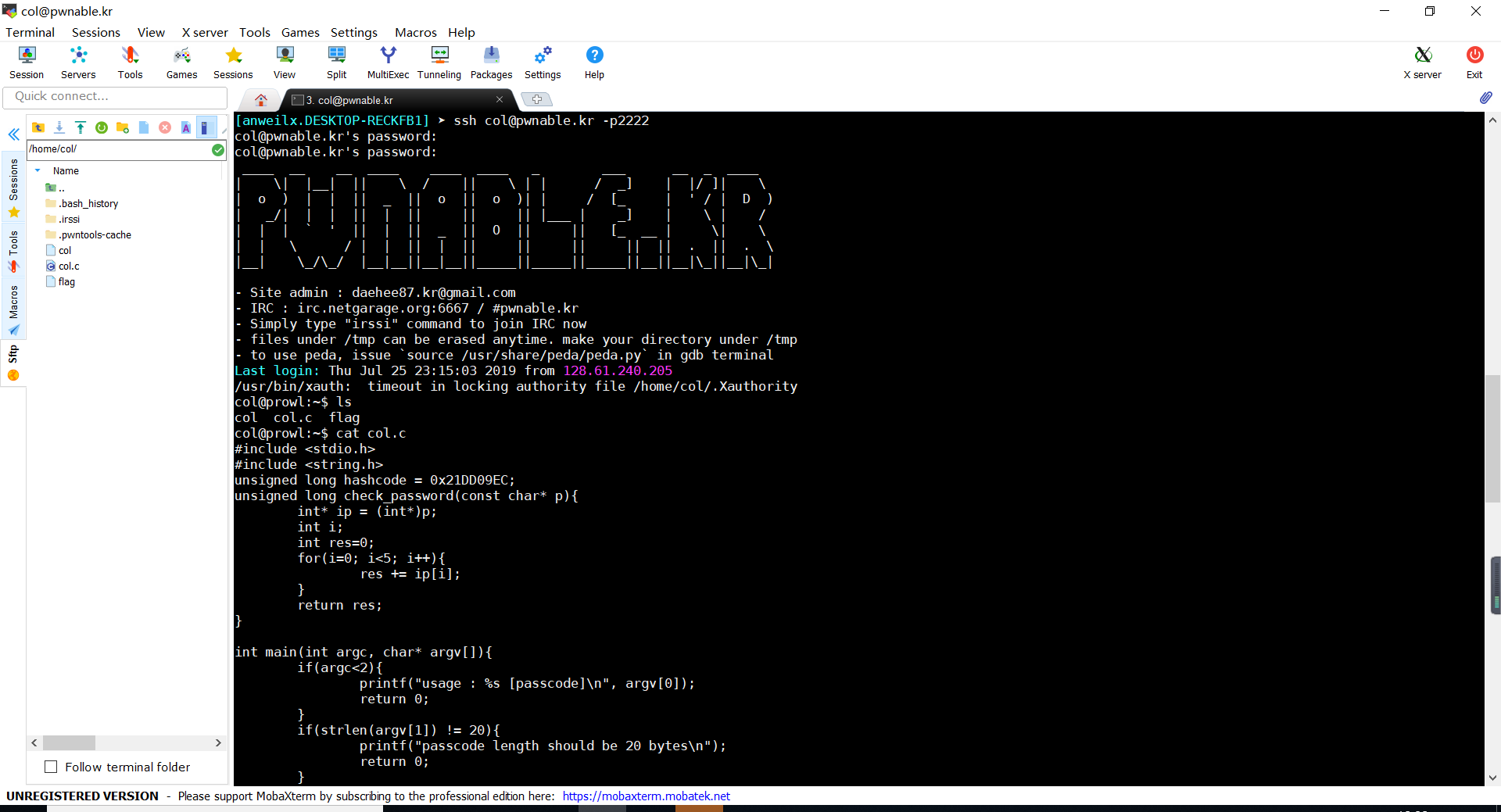
连接成功后所以“ls”命令查看目录
可以看到三个文件
查看源码
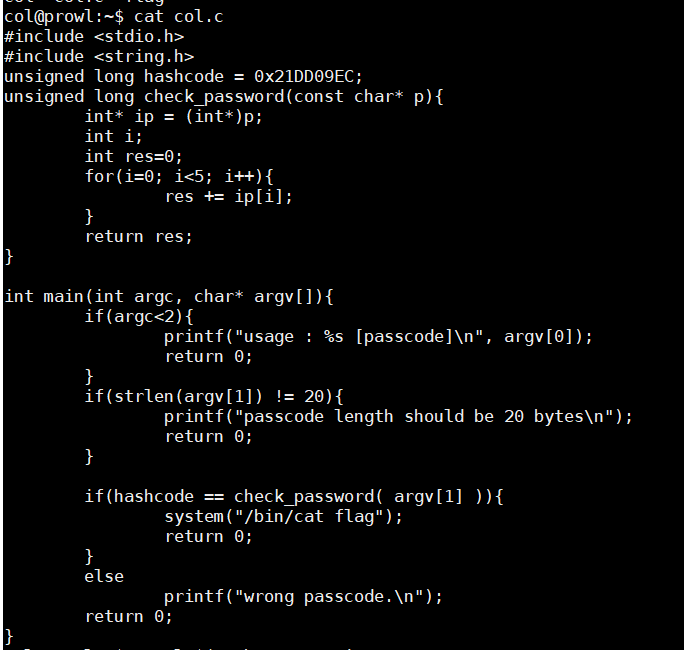
可以看出,需要输入20个字符,如果输入了20个字符,就进入check_password()函数,进行校验密码
这个函数,将传进来的那20个字符p,进行(int *)强制转换也就是会把这20个分成4 个char类型为一组,一共分5组,因为char 是 1个字节,所以4个为一组,一共5组,刚好20个字节,刚好20个输入字符串。

然后把没四个字符看成一共int型的数字,进行5次循环相加,结果放入res中。
然后分析函数入栈情况。
因为
unsigned long hashcode = 0x21DD09EC;
所以只要让我们的输入字符串四个一组加起来等于0x21DD09EC就可以啦,所以没有确定的值,只要符合即可。
注意:必须是小端格式
大端和小端:
1) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
2) Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
举一个例子,比如数字0x12 34 56 78在内存中的表示形式为:
1)大端模式:
低地址 -----------------> 高地址
0x12 | 0x34 | 0x56 | 0x78
2)小端模式:
低地址 ------------------> 高地址
0x78 | 0x56 | 0x34 | 0x12
可见,大端模式和字符串的存储模式类似。
3)下面是两个具体例子:
16bit宽的数0x1234在Little-endian模式(以及Big-endian模式)CPU内存中的存放方式(假设从地址0x4000开始存放)为:
内存地址 小端模式存放内容 大端模式存放内容
0x4000 0x34 0x12
0x4001 0x12 0x34
32bit宽的数0x12345678在Little-endian模式以及Big-endian模式)CPU内存中的存放方式(假设从地址0x4000开始存放)为:
内存地址 小端模式存放内容 大端模式存放内容
0x4000 0x78 0x12
0x4001 0x56 0x34
0x4002 0x34 0x56
0x4003 0x12 0x78
4)大端小端没有谁优谁劣,各自优势便是对方劣势:
小端模式 :强制转换数据不需要调整字节内容,1、2、4字节的存储方式一样。
大端模式 :符号位的判定固定为第一个字节,容易判断正负。
了解了什么是大端和小端后,我们需要以小端格式构造字符串
写一个python脚本执行
得到flag

在题后输入flag,变成这个样子就算完成了。

在解题过程中需要具备一定的编程基础,需要看得懂代码,理解其中的逻辑。
在解题时碰到了不会的内容,可以去查,及时做笔记。
多问,多查,多想。