前言
简单介绍一下哈希基本结构和命令。
正文
什么是hash呢? hash也可以叫做字典、关联数组。
哈希类型是键本身又是一个键值对结构:
value={{field1,value1},...{fieldN,valueN}}
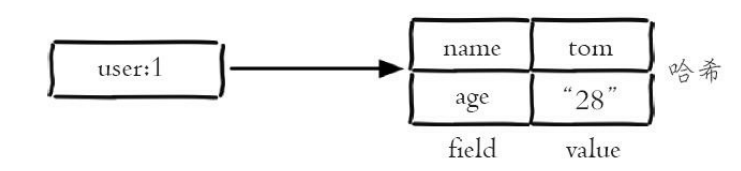
哈希类型中的映射关系叫作field-value,注意这里的value是指field对应 的值,不是键对应的值,请注意value在不同上下文的作用。
来看下命令。
hset key field value

获取值:
hget user:1 name

删除:
hdel key field [field ...]

判断有多少值:

一次性获取多个值:

同样有mset:

然后还可以判断field 是否存在。
hexists key field

获取其全部的key:

获取其全部的值:
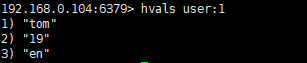
获取全部的keyvalue:

在使用hgetall时,如果哈希元素个数比较多,会存在阻塞Redis的可能。 如果开发人员只需要获取部分field,可以使用hmget,如果一定要获取全部 field-value,可以使用hscan命令,该命令会渐进式遍历哈希类型。
hincrby key field
hincrbyfloat key field
hincrby和hincrbyfloat,就像incrby和incrbyfloat命令一样,但是它们的作 用域是filed。
计算value的字符串长度
hstrlen key field
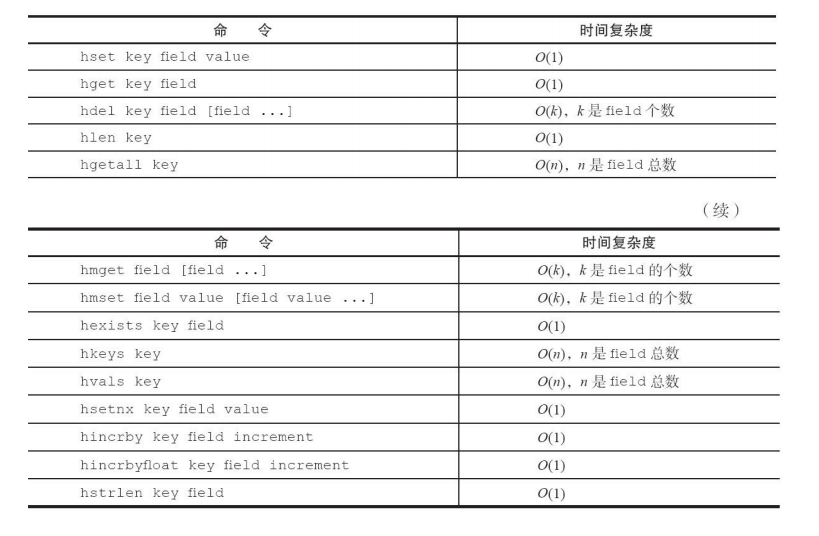
哈希命令复杂度:
内部编码:
·ziplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries 配置(默认512个)、同时所有值都小于hash-max-ziplist-value配置(默认64 字节)时,
Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的 结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。
·hashtable(哈希表):当哈希类型无法满足ziplist的条件时,Redis会使 用hashtable作为哈希的内部实现,因为此时ziplist的读写效率会下降,而 hashtable的读写时间复杂度为O(1)。

使用场景:
- 缓存,比如用作用户信息存储
前面提及到用户信息用字符串存储,然后再系列化。
相比于使用字符串序列化缓存用户信息,哈希类型变得更加直观,并且 102
在更新操作上会更加便捷。可以将每个用户的id定义为键后缀,多对field- value对应每个用户的属性,类似如下伪代码:
UserInfo getUserInfo(long id){ // 用户id作为key后缀 userRedisKey = "user:info:" + id; /
/ 使用hgetall获取所有用户信息映射关系 userInfoMap = redis.hgetAll(userRedisKey);
UserInfo userInfo; if (userInfoMap != null) { // 将映射关系转换为UserInfo userInfo = transferMapToUserInfo(userInfoMap); }
else { // 从MySQL中获取用户信息 userInfo = mysql.get(id); // 将userInfo变为映射关系使用hmset保存到Redis中 redis.hmset(userRedisKey, transferUserInfoToMap(userInfo));
// 添加过期时间 redis.expire(userRedisKey, 3600); }return userInfo; }
这样相比于字符串呢,每次就不用去系列化了,字符串每次都要去进行系列化,然后反系列化存储,具备一定的开销。
然后哈希类型当然也是有缺点的,如果编码是hashtable,那么是比较消耗内存的。
结
下一节redis的list 整理。