链接->网络->传输->应用
连接层
地址解析协议:ARP协议(ARP介于连接层和网络层之间,ARP包需要包裹在一个帧中)的工作方式如下:主机会发出一个ARP包,该ARP包中包含有自己的IP地址和MAC地址。通过ARP包,主机以广播的形式询问局域网上所有的主机和路由:我是IP地址xxxx,我的MAC地址是xxxx,有人知道199.165.146.4的MAC地址吗?拥有该IP地址的主机会回复发出请求的主机:哦,我知道,这个IP地址属于我的一个NIC,它的MAC地址是xxxxxx。由于发送ARP请求的主机采取的是广播形式,并附带有自己的IP地址和MAC地址,其他的主机和路由会同时检查自己的ARP cache,如果不符合,则更新自己的ARP cache。
这样,经过几次ARP请求之后,ARP cache会达到稳定。如果局域网上设备发生变动,ARP重复上面过程。
(在Linux下,可以使用$arp命令来查看ARP的过程。ARP协议只用于IPv4。IPv6使用Neighbor Discovery Protocol来替代ARP的功能。)
网络层
网络层(network layer)是实现互联网的最重要的一层。正是在网络层面上,各个局域网根据IP协议相互连接,最终构成覆盖全球的Internet。更高层的协议,无论是TCP还是UDP,必须通过网络层的IP数据包(datagram)来传递信息。操作系统也会提供该层的socket,从而允许用户直接操作IP包。
IP协议是"Best Effort"式的,IP传输是不可靠的。但这样的设计成就了IP协议的效率。
ICMP(Internet Control Message Protocol)是介于网络层和传输层的协议。它的主要功能是传输网络诊断信息。
ICMP传输的信息可以分为两类,一类是错误(error)信息,这一类信息可用来诊断网络故障。我们已经知道,IP协议的工作方式是“Best Effort”,如果IP包没有被传送到目的地,或者IP包发生错误,IP协议本身不会做进一步的努力。但上游发送IP包的主机和接力的路由器并不知道下游发生了错误和故障,它们可能继续发送IP包。通过ICMP包,下游的路由器和主机可以将错误信息汇报给上游,从而让上游的路由器和主机进行调整。需要注意的是,ICMP只提供特定类型的错误汇报,它不能帮助IP协议成为“可靠”(reliable)的协议。另一类信息是咨询(Informational)性质的,比如某台计算机询问路径上的每个路由器都是谁,然后各个路由器同样用ICMP包回答。
(ICMP基于IP协议。也就是说,一个ICMP包需要封装在IP包中,然后在互联网传送。ICMP是IP套装的必须部分,也就是说,任何一个支持IP协议的计算机,都要同时实现ICMP。)
ICMP协议是实现ping命令和traceroute命令的基础。这两个工具常用于网络排错。
常见的ICMP包类型
回音
回音(Echo)属于咨询信息。ping命令就是利用了该类型的ICMP包。当使用ping命令的时候,将向目标主机发送Echo-询问类型的ICMP包,而目标主机在接收到该ICMP包之后,会回复Echo-回答类型的ICMP包,并将询问ICMP包包含在数据部分。ping命令是我们进行网络排查的一个重要工具。如果一个IP地址可以通过ping命令收到回复,那么其他的网络协议通信方式也很有可能成功。
源头冷却
源头冷却(source quench)属于错误信息。如果某个主机快速的向目的地传送数据,而目的地主机没有匹配的处理能力,目的地主机可以向出发主机发出该类型的ICMP包,提醒出发主机放慢发送速度(请温柔一点吧)。
目的地无法到达
目的地无法到达(Destination Unreachable)属于错误信息。如果一个路由器接收到一个没办法进一步接力的IP包,它会向出发主机发送该类型的ICMP包。比如当IP包到达最后一个路由器,路由器发现目的地主机down机,就会向出发主机发送目的地无法到达(Destination Unreachable)类型的ICMP包。目的地无法到达还可能有其他的原因,比如不存在接力路径,比如不被接收的端口号等等。
超时
超时(Time Exceeded)属于错误信息。IPv4中的Time to Live(TTL)和IPv6中的Hop Limit会随着经过的路由器而递减,当这个区域值减为0时,就认为该IP包超时(Time Exceeded)。Time Exceeded就是TTL减为0时的路由器发给出发主机的ICMP包,通知它发生了超时错误。
traceroute就利用了这种类型的ICMP包。traceroute命令用来发现IP接力路径(route)上的各个路由器。它向目的地发送IP包,第一次的时候,将TTL设置为1,引发第一个路由器的Time Exceeded错误。这样,第一个路由器回复ICMP包,从而让出发主机知道途径的第一个路由器的信息。随后TTL被设置为2、3、4,...,直到到达目的主机。这样,沿途的每个路由器都会向出发主机发送ICMP包来汇报错误。traceroute将ICMP包的信息打印在屏幕上,就是接力路径的信息了。
重新定向
重新定向(redirect)属于错误信息。当一个路由器收到一个IP包,对照其routing table,发现自己不应该收到该IP包,它会向出发主机发送重新定向类型的ICMP,提醒出发主机修改自己的routing table。
IPv6的Neighbor Discovery
ARP协议用于发现周边的IP地址和MAC地址的对应。然而,ARP协议只用于IPv4,IPv6并不使用ARP协议。IPv6包通过邻居探索(ND, Neighbor Discovery)来实现ARP的功能。ND的工作方式与ARP类似,但它基于ICMP协议。ICMP包有Neighbor Solicitation和Neighbor Advertisement类型。这两个类型分别对应ARP协议的询问和回复信息。
总结
ICMP协议是IP协议的排错帮手,它可以帮助人们及时发现IP通信中出现的故障。基于ICMP的ping和traceroute也构成了重要的网络诊断工具。然而,需要注意的是,尽管ICMP的设计是出于好的意图,但ICMP却经常被黑客借用进行网络攻击,比如利用伪造的IP包引发大量的ICMP回复,并将这些ICMP包导向受害主机,从而形成DoS攻击。而redirect类型的ICMP包可以引起某个主机更改自己的routing table,所以也被用作攻击工具。许多站点选择忽视某些类型的ICMP包来提高自身的安全性。
传输层
UDP协议
UDP协议和IP协议一样通过数据包(datagram)的形式传递,同样也是不可靠的,可以将其视为是IP协议暴露在传输层的一个借口。那么,我们为什么不直接使用IP协议而要额外增加一个UDP协议呢? 一个重要的原因是IP协议中并没有端口(port)的概念。IP协议进行的是IP地址到IP地址的传输,这意味者两台计算机之间的对话。但每台计算机中需要有多个通信通道,并将多个通信通道分配给不同的进程使用。一个端口就代表了这样的一个通信通道。UDP协议实现了端口,从而让数据包可以在送到IP地址的基础上,进一步可以送到某个端口。
尽管UDP协议非常简单,但它的产生晚于更加复杂的TCP协议。早期的网络开发者开发出IP协议和TCP协议分别位于网络层和传输层,所有的通信都要先经过TCP封装,再经过IP封装(应用层->TCP->IP)。开发者将TCP/IP视为相互合作的套装。但很快,网络开发者发现,IP协议的功能和TCP协议的功能是相互独立的。对于一些简单的通信,我们只需要“Best Effort”式的IP传输就可以了,而不需要TCP协议复杂的建立连接的方式(特别是在早期网络环境中,如果过多的建立TCP连接,会造成很大的网络负担,而UDP协议可以相对快速的处理这些简单通信)。UDP协议随之被开发出来,作为IP协议在传输层的"傀儡"。这样,网络通信可以通过应用层->UDP->IP的封装方式,绕过TCP协议。由于UDP协议本身异常简单,实际上只为IP传输起到了桥梁的作用。
端口(port)是伴随着传输层诞生的概念。它可以将网络层的IP通信分送到各个通信通道。UDP协议和TCP协议尽管在工作方式上有很大的不同,但它们都建立了从一个端口到另一个端口的通信。
随着我们进入传输层,我们也可以调用操作系统中的API,来构建socket。Socket是操作系统提供的一个编程接口,它用来代表某个网络通信。应用程序通过socket来调用系统内核中处理网络协议的模块,而这些内核模块会负责具体的网络协议的实施。这样,我们可以让内核来接收网络协议的细节,而我们只需要提供所要传输的内容就可以了,内核会帮我们控制格式,并进一步向底层封装。因此,在实际应用中,我们并不需要知道具体怎么构成一个UDP包,而只需要提供相关信息(比如IP地址,比如端口号,比如所要传输的信息),操作系统内核会在传输之前会根据我们提供的相关信息构成一个合格的UDP包(以及下层的包和帧)。
TCP协议
TCP(Transportation Control Protocol)协议与IP协议是一同产生的。事实上,两者最初是一个协议,后来才被分拆成网络层的IP和传输层的TCP。
“流”通信
TCP协议是传输层协议,实现的是端口到端口(port)的通信。更进一步,TCP协议实现了文本流(byte stream)的通信。
IP协议和和UDP协议采用的是数据包的方式传送,后发出的数据包可能早到,我们并不能保证数据到达的次序。TCP协议确保了数据到达的顺序与文本流顺序相符。
“流”的要点是次序(order),然而实现这一点并不简单。TCP协议是基于IP协议的,所以最终数据传送还是以IP数据包为单位进行的。如果一个文本流很长的话,我们不可能将整个文本流放入到一个IP数据包中,那样有可能会超过MTU。所以,TCP协议封装到IP包的不是整个文本流,而是TCP协议所规定的片段(segment)。与之前的一个IP或者UDP数据包类似,一个TCP片段同样分为头部(header)和数据(payload)两部分 (“片段”这个名字更多是起提醒作用:嘿,这里并不是完整的文本流)。整个文本流按照次序被分成小段,而每一段被放入TCP片段的数据部分。一个TCP片段封装成的IP包不超过整个IP接力路径上的最小MTU,从而避免令人痛苦的碎片化(fragmentation)。
(给文本流分段是在发送主机完成的,而碎片化是在网络中的路由器完成的。路由器要处理许多路的通信,所以相当繁忙。文本流提前在发送主机分好段,可以避免在路由器上执行碎片化,可大大减小网络负担)
TCP片段的头部(header)会存有该片段的序号(sequence number)。这样,接收的计算机就可以知道接收到的片段在原文本流中的顺序了,也可以知道自己下一步需要接收哪个片段以形成流。比如已经接收到了片段1,片段2,片段3,那么接收主机就开始期待片段4。如果接收到不符合顺序的数据包(比如片段8),接收方的TCP模块可以拒绝接收,从而保证呈现给接收主机的信息是符合次序的“流”。
可靠性
片段编号这个初步的想法并不能解决我们所有的问题。IP协议是不可靠的,所以IP数据包可能在传输过程中发生错误或者丢失。而IP传输是"Best Effort" 式的,如果发生异常情况,我们的IP数据包就会被轻易的丢弃掉。另一方面,如果乱序(out-of-order)片段到达,根据我们上面说的,接收主机不会接收。这样,错误片段、丢失片段和被拒片段的联手破坏之下,接收主机只可能收到一个充满“漏洞”的文本流。
TCP的解决方案:接受方收到一个正确顺序的片段之后回复一个TCP片段,我们称之为ACK回复。如果接受的TCP编号为L,回复的ACK编号为L+1。如果发送方在一定时间等待之后,还是没有收到ACK回复,那么它推断之前发送的片段一定发生了异常。发送方会重复发送(retransmit)那个出现异常的片段,等待ACK回复,如果还没有收到,那么再重复发送原片段... 直到收到该片段对应的ACK回复(回复号为L+1的ACK)。
当发送方收到ACK回复时,它看到里面的回复号为L+1,也就是发送方下一个应该发送的TCP片段序号。发送方推断出之前的片段已经被正确的接收,随后发出L+1号片段。ACK回复也有可能丢失。对于发送方来说,这和接收方拒绝发送ACK回复是一样的。发送方会重复发送,而接收方接收到已知会过的片段,推断出ACK回复丢失,会重新发送ACK回复。
滑窗
上面的工作方式中,发送方保持发送->等待ACK->发送->等待ACK...的单线工作方式,这样的工作方式叫做stop-and-wait。stop-and-wait虽然实现了TCP通信的可靠性,但同时牺牲了网络通信的效率。在等待ACK的时间段内,我们的网络都处于闲置(idle)状态。我们希望有一种方式,可以同时发送出多个片段。然而如果同时发出多个片段,那么由于IP包传送是无次序的,有可能会生成乱序片段(out-of-order),也就是后发出的片段先到达。在stop-and-wait的工作方式下,乱序片段完全被拒绝,这也很不效率。毕竟,乱序片段只是提前到达的片段。我们可以在缓存中先存放它,等到它之前的片段补充完毕,再将它缀在后面。然而,如果一个乱序片段实在是太过提前(太“乱”了),该片段将长时间占用缓存。我们需要一种折中的方法来解决该问题:利用缓存保留一些“不那么乱”的片段,期望能在段时间内补充上之前的片段(暂不处理,但发送相应的ACK);对于“乱”的比较厉害的片段,则将它们拒绝(不处理,也不发送对应的ACK)。
滑窗(sliding window)被同时应用于接收方和发送方,以解决以上问题。发送方和接收方各有一个滑窗。当片段位于滑窗中时,表示TCP正在处理该片段。滑窗中可以有多个片段,也就是可以同时处理多个片段。滑窗越大,越大的滑窗同时处理的片段数目越多(当然,计算机也必须分配出更多的缓存供滑窗使用)。
TCP连接
网络层在逻辑上提供了端口的概念。一个IP地址可以有多个端口。一个具体的端口需要IP地址和端口号共同确定(我们记为IP:port的形式)。一个连接为两个IP:port之间建立TCP通信。
TCP连接是双向(duplex)的。TCP传输是单向的,双向连接实际上就是建立两个方向的TCP传输,所以概念上并不复杂。这时,连接的每一方都需要两个滑窗,以分别处理发送的文本流和接收的文本流。由于连接的双向性,我们也要为两个方向的文本流编号。这两个文本流的编号相互独立。为文本流分段和编号由发送方来处理,回复ACK则由接收的一方进行。
应用层
DNS协议
域名(domain name)是IP地址的代号。域名通常是由字符构成的。对于人类来说,字符构成的域名,比如www.yahoo.com,要比纯粹数字构成的IP地址(106.10.170.118)容易记忆。域名解析系统(DNS, domain name system)就负责将域名翻译为对应的IP地址。在DNS的帮助下,我们可以在浏览器的地址栏输入域名,而不是IP地址。这大大减轻了互联网用户的记忆负担。另一方面,处于维护和运营的原因,一些网站可能会变更IP地址。这些网站可以更改DNS中的对应关系,从而保持域名不变,而IP地址更新。由于大部分用户记录的都是域名,这样就可以降低IP变更带来的影响。
从机器和技术的角度上来说,域名并不是必须的。但Internet是由机器和用户共同构成的。鉴于DNS对用户的巨大帮助,DNS已经被当作TCP/IP套装不可或缺的一个组成部分。
域名和IP地址的对应关系存储在DNS服务器(DNS server)中。所谓的DNS服务器,是指在网络中进行域名解析的一些服务器(计算机)。这些服务器都有自己的IP地址,并使用DNS协议(DNS protocol)进行通信。DNS协议主要基于UDP,是应用层协议。
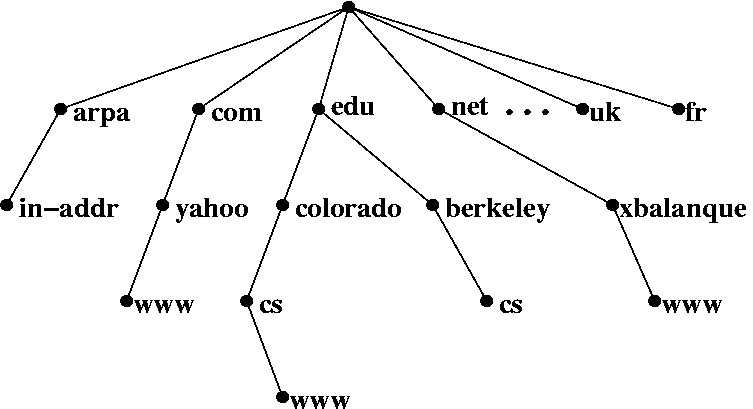
DNS服务器构成一个分级(hierarchical)的树状体系。上图中,每个节点(node)为一个DNS服务器,每个节点都有自己的IP地址。树的顶端为用户电脑出口处的DNS服务器。在Linux下,可以使用cat /etc/resolv.conf,在Windows下,可以使用ipconfig /all,来查询出口DNS服务器。树的末端是真正的域名/IP对应关系记录。一次DNS查询就是从树的顶端节点出发,最终找到相应末端记录的过程。
中间节点根据域名的构成,将DNS查询引导向下一级的服务器。比如说一个域名cs.berkeley.edu,DNS解析会将域名分割为cs, berkeley, edu,然后按照相反的顺序查询(edu, berkeley, cs)。出口DNS首先根据edu,将查询指向下一层的edu节点。然后edu节点根据berkeley,将查询指向下一层的berkeley节点。这台berkeley服务器上存储有cs.berkeley.edu的IP地址。所以,中间节点不断重新定向,并将我们引导到正确的记录。
在整个DNS查询过程中,无论是重新定向还是最终取得对应关系,都是用户计算机和DNS服务器使用DNS协议通信。用户计算机根据DNS服务器的反馈,依次与下一层的DNS服务器建立通信。用户计算机经过递归查询,最终和末端节点通信,并获得IP地址。

缓存
用户计算机的操作系统中的域名解析模块(DNS Resolver)负责域名解析的相关工作。任何一个应用程序(邮件,浏览器)都可以通过调用该模块来进行域名解析。
并不是每次域名解析都要完整的经历解析过程。DNS Resolver通常有DNS缓存(cache),用来记录最近使用和查询的域名/IP关系。在进行DNS查询之前,计算机会先查询cache中是否有相关记录。这样,重复使用的域名就不用总要经过整个递归查询过程。
反向DNS
上面的DNS查询均为正向DNS查询:已经知道域名,想要查询对应IP。而反向DNS(reverse DNS)是已经知道IP的前提下,想要查询域名。反向DNS也是采用分层查询方式,对于一个IP地址(比如106.10.170.118),依次查询in-addr.arpa节点(如果是IPv6,则为ip6.arpa节点),106节点,10节点,170节点,并在该节点获得106.10.170.118对应的域名。
HTTP协议
TCP协议实现了数据流的传输。然而,人们更加习惯以文件为单位传输资源,比如文本文件,图像文件,超文本文档(hypertext document)。
HTTP协议解决文件传输的问题。HTTP是应用层协议,主要建立在TCP协议之上(偶尔也可以UDP为底层)。它随着万维网的发展而流行。HTTP协议目的是,如何在万维网的网络环境下,更好的利用TCP协议,以实现文件,特别是超文本文件的传输。
早期的HTTP协议主要传输静态文件,即真实存储在服务器上的文件。随着万维网的发展,HTTP协议被用于传输“动态文件”,服务器上的程序根据HTTP请求即时生成的动态文件。我们将HTTP的传输对象统称为资源(resource)。
格式
HTTP协议的通信是一次request-responce交流。客户端(guest)向服务器发出请求(request),服务器(server)回复(response)客户端。

HTTP协议规定了请求和回复的格式:
起始行 (start line)
头信息 (headers)
主体(entity body)
起始行只有一行。它包含了请求/回复最重要的信息。请求的起始行表示(顾客)“想要什么”。回复的起始行表示(后厨)“发生什么”。
头信息可以有多行。每一行是一对键值对(key-value pair),比如:
Content-type: text/plain
它表示,包含有一个名为Content-type的参数,该参数的值为text/plain。头信息是对起始行的补充。请求的头信息对服务器有指导意义 (好像在菜单上注明: 鸡腿不要辣)。回复的头信息则是提示客户端(比如,在盒子上注明: 小心烫)
主体部分包含了具体的资源。上图的请求中并没有主体,因为我们只是在下单,而不用管后厨送什么东西 (请求是可以有主体内容的)。回复中包含的主体是一段文本文字(Hello World!)。这段文本文字正是顾客所期待的,鸡腿汉堡。
请求
我们深入一些细节。先来看一下请求:
GET /index.html HTTP/1.1
Host: www.example.com
在起始行中,有三段信息:
- GET 方法。用于说明想要服务器执行的操作。
- /index.html 资源的路径。这里指向服务器上的index.html文件。
- HTTP/1.1 协议的版本。HTTP第一个广泛使用的版本是1.0,当前版本为1.1。
早期的HTTP协议只有get方法。遵从HTTP协议,服务器接收到GET请求后,会将特定资源传送给客户。这类似于客户点单,并获得汉堡的过程。使用GET方法时,是客户向服务器索取资源,所以请求往往没有主体部分。
GET方法也可以用于传输一些不重要的数据。它是通过改写URL的方式实现的。GET的数据利用URL?变量名=变量值的方法传输。比如向http://127.0.0.1发送一个变量“q”,它的值为“a”。那么,实际的URL为http://127.0.0.1?q=a。服务器收到请求后,就可以知道"q"的值为"a"。
GET方法之外,最常用的是POST方法。它用于从客户端向服务器提交数据。使用POST方法时,URL不再被改写。数据位于http请求的主体。POST方法最用于提交HTML的form数据。服务器往往会对POST方法提交的数据进行一定的处理,比如存入服务器数据库。
样例请求中有一行头信息。该头信息的名字是Host。HTTP的请求必须有Host头信息,用于说明服务器的地址和端口。HTTP协议的默认端口是80,如果在HOST中没有说明端口,那么将默认采取该端口。在该例子中,服务器的域名为www.example.com,端口为80。域名将通过DNS服务器转换为IP地址,从而确定服务器在互联网上的地址。
回复
服务器在接收到请求之后,会根据程序,生成对应于该请求的回复,比如:
HTTP/1.1 200 OK
Content-type: text/plain
Content-length: 12
Hello World!
回复的起始行同样包含三段信息
- HTTP/1.1 协议版本
- 200 状态码(status code)。
- OK 状态描述
OK是对状态码200的文字描述,它只是为了便于人类的阅读。电脑只关心三位的状态码(status code),即这里的200。200表示一切OK,资源正常返回。状态码代表了服务器回应动作的类型。
其它常见的状态码还有:
- 302,重新定向(redirect): 我这里没有你想要的资源,但我知道另一个地方xxx有,你可以去那里找。
- 404,无法找到(not found): 我找不到你想要的资源,无能为力。
(重新定向时,客户端可以根据302的建议前往xxx寻找资源,也可以忽略该建议。)
Content-type说明了主体所包含的资源的类型。根据类型的不同,客户端可以启动不同的处理程序(比如显示图像文件,播放声音文件等等)。下面是一些常见的资源
- text/plain 普通文本
- text/html HTML文本
- image/jpeg jpeg图片
- image/gif gif图片
Content-length说明了主体部分的长度,以字节(byte)为单位。
回应的主体部分为一段普通文本,即
Hello World!
无状态
根据早期的HTTP协议,每次request-reponse时,都要重新建立TCP连接。TCP连接每次都重新建立,所以服务器无法知道上次请求和本次请求是否来自于同一个客户端。因此,HTTP通信是无状态(stateless)的。服务器认为每次请求都是一个全新的请求,无论该请求是否来自同一地址。
想象高级餐厅和快餐店。高级餐厅会知道客人所在的位置,如果新增点单,那么服务员知道这和上一单同一桌。而在快餐店中,不好意思,服务员并不记录客人的特征。想再次点单?请重新排队……
随着HTTP协议的发展,HTTP协议允许TCP连接复用,以节省建立连接所耗费的时间。但HTTP协议依然保持无状态的特性。