使用firefox浏览器,查看页面元素,我们以“百度网页”为示例
一、ID定位元素 利用find_element_by_id()方法来定位网页元素对象
①、定位百度首页,输入框的元素

②、编写示例代码信息如下:
#coding=utf-8 from selenium import webdriver driver=webdriver.Chrome() #打开chrome,如果没有安装chrome,换成firefox或ie浏览器 driver.maximize_window() #最大化浏览器窗口 driver.implicitly_wait(8) #设置隐式时间等待 driver.get("https://www.baidu.com") #进入百度网页 #利用ID定位元素 try: driver.find_element_by_id("kw") #在①中可以查看定位到输入框的id为“kw” print('test pass : ID found') except Exception as e: print("Exception found",format(e))
driver.quit()
③ 运行代码后,会打印出 “test pass : ID found”的成功信息
二、Xpath定位元素 利用find_element_by_xpath()方法来定位网页元素对象,示例中,①我们先定位搜索输入框元素②在输入框输入selenium③再定位搜索按钮(百度一下)④在搜索结果中定位都selenium官网相关元素
①如下三个截图是分别定位的输入框元素、搜索按钮元素、搜索结果中selenium官网元素的xpath
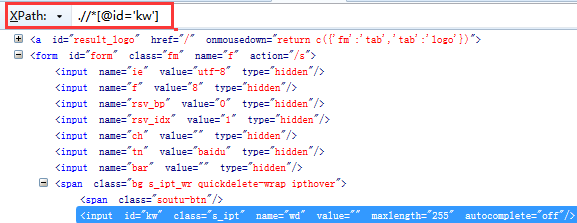
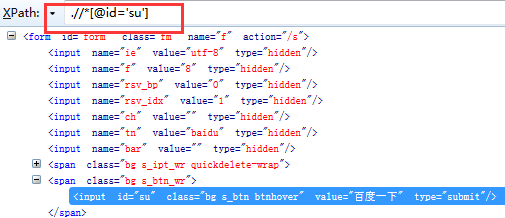
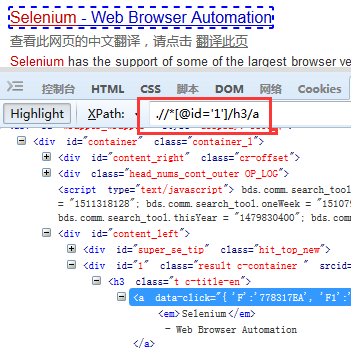
②编写示例代码信息如下:
#coding=utf-8 import time from selenium import webdriver driver=webdriver.Chrome() #打开chrome,如果没有安装chrome,换成firefox或ie浏览器 driver.maximize_window() #最大化浏览器窗口 driver.implicitly_wait(8) #设置隐式时间等待 driver.get("https://www.baidu.com") #进入百度网页 #利用 xpath定位元素 driver.find_element_by_xpath(".//*[@id='kw']").send_keys("selenium") #定位搜索输入框,并在输入框输入selenium搜索信息 driver.find_element_by_xpath(".//*[@id='su']").click() #定位“百度一下”的搜索按钮,并点击 time.sleep(2) #第一种断言方法 #这里通过元素xpath表达式来确定该元素显示在结果列表,从而判断Selenium官网这个连接显示在结果列表 #这里采用了相对元素定位方法/.../ #通过selenium方法is_displayed() 来判断我们的目标元素是否在页面显示 driver.find_element_by_xpath(".//*[@id='1']/h3/a").is_displayed() #第二种判断方法 ele_string=driver.find_element_by_xpath(".//*[@id='1']/h3/a").text if(ele_string==u"Selenium - Web Browser Automation"): print("测试成功,结果和预期结果匹配")
driver.quit()
③上面代码运行后,会打印出“测试成功,结果和预期结果匹配”的成功信息
三、tag name 定位元素 利用 find_element_by_tag_name() 方法 来定位页面元素
①定位百度搜索输入框的tag name,如下截图

上面图片中红色圈选区域的标签名称都是tag name;实际上我们目标元素是输入框,应该是input这个tag name,在图中蓝色高亮区域。但是如果只是通过input这个tag name来定位,发现上面有很多input的选项。所以我们扩大节点的参照选择,我们选择上面这个form来作为我们tag name
②示例代码如下
1 #coding=utf-8 2 3 from selenium import webdriver 4 5 driver=webdriver.Chrome() #打开chrome,如果没有安装chrome,换成firefox或ie浏览器 6 driver.maximize_window() #最大化浏览器窗口 7 driver.implicitly_wait(8) #设置隐式时间等待 8 9 driver.get("https://www.baidu.com") #进入百度网页 10 11 #利用tag name定位元素 12 driver.find_element_by_tag_name("form") 13 print("test pass : tag name found")
driver.quit()
③代码运行后,打印“test pass : tag name found” 成功提示
四、link text 定位元素 利用find_element_by_link_text()方法 定位页面元素
①定位百度首页“新闻”这个文本字段来定义这个跳转链接元素

②示例代码如下:
1 #coding=utf-8 2 3 from selenium import webdriver 4 5 driver=webdriver.Chrome() #打开chrome,如果没有安装chrome,换成firefox或ie浏览器 6 driver.maximize_window() #最大化浏览器窗口 7 driver.implicitly_wait(8) #设置隐式时间等待 8 9 driver.get("https://www.baidu.com") #进入百度网页 10 11 #利用 link text定位元素 12 driver.find_element_by_link_text("新闻") 13 print("test pass ") 14 driver.quit()
运行代码成功,打印成功信息
五、partial link text定位元素,partial link text和link text有点类似,区别就是选择这个元素的link text中一部分字段, 利用find_element_by_partial_link_text()方法定义页面元素
①以下面截图中被选中的信息做目标元素

②示例代码如下:
1 #coding=utf-8 2 3 from selenium import webdriver 4 5 driver=webdriver.Chrome() #打开chrome,如果没有安装chrome,换成firefox或ie浏览器 6 driver.maximize_window() #最大化浏览器窗口 7 driver.implicitly_wait(8) #设置隐式时间等待 8 9 driver.get("https://www.baidu.com") #进入百度网页 10 #利用partial link text 定位元素 11 driver.find_element_by_partial_link_text("设为主页").click() 12 print("test pass : Success") 13 time.sleep(10) #停留时间,是为了查看点击进入的页面,是否成功 14 driver.quit()
运行成功后,可以查看到进入的页面,和打印的成功信息
六、class name定位元素 ,利用find_element_by_class_name()方法来定义页面元素
①定义百度首页输入框元素,查看class如下截图

②示例代码如下:
#coding=utf-8 from selenium import webdriver driver=webdriver.Chrome() #打开chrome,如果没有安装chrome,换成firefox或ie浏览器 driver.maximize_window() #最大化浏览器窗口 driver.implicitly_wait(8) #设置隐式时间等待 driver.get("https://www.baidu.com") #进入百度网页 #利用class name定位元素 driver.find_element_by_class_name("s_ipt") print("test pass :Success!!") driver.quit()
运行代码后,打印成功信息
七、CSS 定位元素 利用find_element_by_css() 方法
示例代码如下:
1 #coding=utf-8 2 from selenium import webdriver 3 4 driver=webdriver.Chrome() #打开chrome,如果没有安装chrome,换成firefox或ie浏览器 5 driver.maximize_window() #最大化浏览器窗口 6 driver.implicitly_wait(8) #设置隐式时间等待 7 8 driver.get("https://www.baidu.com") #进入百度网页 9 driver.find_element_by_css_selector("#su") # 找 百度一下 这个按钮 10 print ('test pass') 11 12 driver.quit()
八、name定位 ,利用find_element_by_name()方法
①定位百度输入框元素的name

②示例代码如下:
#coding=utf-8 from selenium import webdriver driver=webdriver.Chrome() #打开chrome,如果没有安装chrome,换成firefox或ie浏览器 driver.maximize_window() #最大化浏览器窗口 driver.implicitly_wait(8) #设置隐式时间等待 driver.get("https://www.baidu.com") #进入百度网页 driver.find_element_by_name("wd") # 这里百度搜索输入框有name = 'wd'这个节点信息 print ('test pass: element found by name value') driver.quit()
运行代码后,打印出成功信息