1.1.1 map端连接-CompositeInputFormat连接类
(1)使用CompositeInputFormat连接类需要满足三个条件:
1)两个数据集都是大的数据集,不能用缓存文件的方式。
2)数据集都是按照相同的键进行排序;
3)数据集有相同的分区数,同一个键的所有记录在同一个分区中,输出文件不可分割;
要满足这三个条件,输入数据在达到map端连接函数之前,两个数据集被reduce处理,reduce任务数量相同都为n,两个数据集被分区输出到n个文件,同一个键的所有记录在同一个分区中,且数据集中的数据都是按照连接键进行排序的。reduce数量相同、键相同且都是按键排序、输出文件是不可切分的(小于一个HDFS块,或通过gzip压缩实现),则就满足map端连接的前提条件。利用org.apach.hadoop.mapreduce.join包中的CompositeInputFormat类来运行一个map端连接。
(2)CompositeInputFormat类简介
CompositeInputFormat类的作用就将job的输入格式设置为job.setInputFormatClass(CompositeInputFormat.class);同时通过conf的set(String name, String value)方法设置两个数据集的连接表达式,表达式内容包括三个要素:连接方式(inner、outer、override、tbl等) ,读取两个数据集的输入方式,两个数据集的路径。这三个要素按照一定的格式组织成字符串作为表达式设置到conf中。
//设置输入格式为 CompositeInputFormat
job.setInputFormatClass(CompositeInputFormat.class);
//conf设置连接的表达式public static final String JOIN_EXPR = "mapreduce.join.expr";
Configuration conf = job.getConfiguration();
conf.set(CompositeInputFormat.JOIN_EXPR, CompositeInputFormat.compose(
"inner", KeyValueTextInputFormat.class,
FileInputFormat.getInputPaths(job)));
//等价转换之后就是如下表达式
//conf.set("mapreduce.join.expr", CompositeInputFormat.compose(
// "inner", KeyValueTextInputFormat.class, userPath,commentPath));
CompositeInputFormat类的源码如下
// // Source code recreated from a .class file by IntelliJ IDEA // (powered by Fernflower decompiler) // package org.apache.hadoop.mapreduce.lib.join; import java.io.IOException; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import java.util.Map.Entry; import java.util.regex.Matcher; import java.util.regex.Pattern; import org.apache.hadoop.classification.InterfaceAudience.Public; import org.apache.hadoop.classification.InterfaceStability.Stable; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.mapreduce.InputFormat; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.JobContext; import org.apache.hadoop.mapreduce.RecordReader; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.join.Parser.CNode; import org.apache.hadoop.mapreduce.lib.join.Parser.Node; import org.apache.hadoop.mapreduce.lib.join.Parser.WNode; @Public @Stable public class CompositeInputFormat<K extends WritableComparable> extends InputFormat<K, TupleWritable> { public static final String JOIN_EXPR = "mapreduce.join.expr"; public static final String JOIN_COMPARATOR = "mapreduce.join.keycomparator"; private Node root; public CompositeInputFormat() { } public void setFormat(Configuration conf) throws IOException { this.addDefaults(); this.addUserIdentifiers(conf); this.root = Parser.parse(conf.get("mapreduce.join.expr", (String)null), conf); } protected void addDefaults() { try {//有默认的四种连接方式,每种连接方式都有对应的Reader CNode.addIdentifier("inner", InnerJoinRecordReader.class); CNode.addIdentifier("outer", OuterJoinRecordReader.class); CNode.addIdentifier("override", OverrideRecordReader.class); WNode.addIdentifier("tbl", WrappedRecordReader.class); } catch (NoSuchMethodException var2) { throw new RuntimeException("FATAL: Failed to init defaults", var2); } } private void addUserIdentifiers(Configuration conf) throws IOException { Pattern x = Pattern.compile("^mapreduce\.join\.define\.(\w+)$"); Iterator i$ = conf.iterator(); while(i$.hasNext()) { Entry<String, String> kv = (Entry)i$.next(); Matcher m = x.matcher((CharSequence)kv.getKey()); if (m.matches()) { try { CNode.addIdentifier(m.group(1), conf.getClass(m.group(0), (Class)null, ComposableRecordReader.class)); } catch (NoSuchMethodException var7) { throw new IOException("Invalid define for " + m.group(1), var7); } } } } public List<InputSplit> getSplits(JobContext job) throws IOException, InterruptedException { this.setFormat(job.getConfiguration()); job.getConfiguration().setLong("mapreduce.input.fileinputformat.split.minsize", 9223372036854775807L); return this.root.getSplits(job); } public RecordReader<K, TupleWritable> createRecordReader(InputSplit split, TaskAttemptContext taskContext) throws IOException, InterruptedException { this.setFormat(taskContext.getConfiguration()); return this.root.createRecordReader(split, taskContext); } //按格式组织连接表达式 public static String compose(Class<? extends InputFormat> inf, String path) { return compose(inf.getName().intern(), path, new StringBuffer()).toString(); } //连接方式(inner、outer、override、tbl等) 、读取两个数据集的输入方式、两个数据集的路径 public static String compose(String op, Class<? extends InputFormat> inf, String... path) { String infname = inf.getName();//org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat StringBuffer ret = new StringBuffer(op + '('); String[] arr$ = path; int len$ = path.length; for(int i$ = 0; i$ < len$; ++i$) { String p = arr$[i$]; compose(infname, p, ret); ret.append(','); } ret.setCharAt(ret.length() - 1, ')'); return ret.toString(); } public static String compose(String op, Class<? extends InputFormat> inf, Path... path) { ArrayList<String> tmp = new ArrayList(path.length); Path[] arr$ = path; int len$ = path.length; for(int i$ = 0; i$ < len$; ++i$) { Path p = arr$[i$]; tmp.add(p.toString()); } return compose(op, inf, (String[])tmp.toArray(new String[0])); } private static StringBuffer compose(String inf, String path, StringBuffer sb) { sb.append("tbl(" + inf + ",""); sb.append(path); sb.append("")"); return sb; } }
其中主要的函数就是compose函数,他是一个重载函数:
public static String compose(String op, Class<? extends InputFormat> inf, String... path);
op表示连接类型(inner、outer、override、tbl),inf表示数据集的输入方式,path表示输入数据集的文件路径。这个函数的作用是将传入的表达式三要素:连接方式(inner、outer、override、tbl等) 、读取两个数据集的输入方式、两个数据集的路径组成字符串。假设conf按如下方式传入三要素:
conf.set("mapreduce.join.expr", CompositeInputFormat.compose(
"inner", KeyValueTextInputFormat.class,“/hdfs/inputpath/userpath”, “/hdfs/inputpath/commentpath”));
compose函数最终得出的表达式为:
inner(tbl(org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat,” /hdfs/inputpath/userpath”),tbl(org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat,” /hdfs/inputpath/ commentpath”))
现在我只能深入到这里,至于为什么要满足三个条件才可以连接?设置表达式之后内部又是如何实现连接?有知道的欢迎留言讨论。
(3)CompositeInputFormat实现map端连接的实例
成绩数据和名字数据通过CompositeInputFormat实现map连接
成绩数据:
1,yuwen,100
1,shuxue,99
2,yuwen,99
2,shuxue,88
3,yuwen,99
3,shuxue,56
4,yuwen,33
4,shuxue,99名字数据:
1,yaoshuya,25
2,yaoxiaohua,29
3,yaoyuanyie,15
4,yaoshupei,26
文件夹定义如下:

代码:
package Temperature; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileUtil; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat; import org.apache.hadoop.mapreduce.lib.join.CompositeInputFormat; import org.apache.hadoop.mapreduce.lib.join.TupleWritable; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.File; import java.io.IOException; public class CompositeJoin extends Configured implements Tool { private static class CompositeJoinMapper extends Mapper<Text, TupleWritable,Text,TupleWritable> { @Override protected void map(Text key, TupleWritable value, Context context) throws IOException, InterruptedException { context.write(key,value); } } public int run(String[] args) throws Exception { Path userPath = new Path(args[0]); Path commentPath = new Path(args[1]); Path output = new Path(args[2]); Job job=null; try { job = new Job(getConf(), "mapinnerjoin"); } catch (IOException e) { e.printStackTrace(); } job.setJarByClass(getClass()); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(TupleWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(TupleWritable.class); // 设置两个输入数据集的目录 FileInputFormat.addInputPaths(job, args[0]); FileInputFormat.addInputPaths(job, args[1]); //设置输出目录 FileOutputFormat.setOutputPath(job,output); Configuration conf = job.getConfiguration(); //设置输入格式为 CompositeInputFormat job.setInputFormatClass(CompositeInputFormat.class); conf.set("mapreduce.input.keyvaluelinerecordreader.key.value.separator", ","); //conf设置连接的表达式public static final String JOIN_EXPR = "mapreduce.join.expr"; //conf.set(CompositeInputFormat.JOIN_EXPR, CompositeInputFormat.compose( // "inner", KeyValueTextInputFormat.class, // FileInputFormat.getInputPaths(job))); //等价转换之后就是如下表达式 String strExpretion=CompositeInputFormat.compose("inner", KeyValueTextInputFormat.class, userPath,commentPath); conf.set("mapreduce.join.expr",strExpretion ); job.setOutputFormatClass(TextOutputFormat.class); job.setNumReduceTasks(0);//map端连接,reduce为0,不使用reduce job.setMapperClass(CompositeJoinMapper.class); //键值属性分隔符设置为空格 //删除结果目录,重新生成 FileUtil.fullyDelete(new File(args[2])); return job.waitForCompletion(true)?0:1; } public static void main(String[] args) throws Exception { //三个参数,两个连接的数据路径,一个输出路径 int exitCode= ToolRunner.run(new CompositeJoin(),args); System.exit(exitCode); } }
设置run->edit Configuration设置输入输出路径,两个输入,一个输出
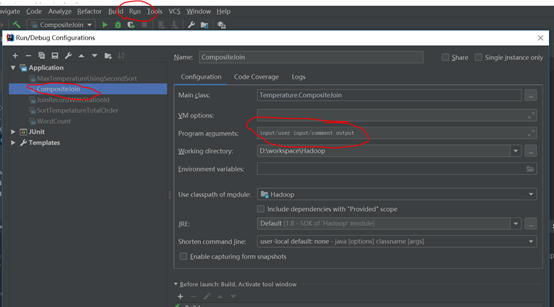
运行该类的main函数得到结果

自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取: