当一个软件遇到了性能瓶颈时,首要的改进是软件功能重构,适当删除可能拖垮系统的业务需求。客户对“实时”相当感兴趣,然而又有几个使用者能够真正清楚什么地方应该是实时的?这一点同样体现在其它行业,生厂商想要降低生产成本,相比于对供应商的原料压价,提高生产率、改进制作工艺、优化生产线是更好的办法。
第二个应当改进的是软件结构,包括部署结构、数据存储结构、软件设计结构。软件设计本身就是一个从结构到行为的过程,能够产生什么样的行为是由它的结构决定的,一个优良的结构能够较为容易地让你定位到影响性能的关键点。小猫能够轻松地爬树,这是由于它有柔软的脊柱和锋利的爪子;相反,人的身体结构对爬树支持的并不友好,所以再怎么训练也比不过小猫。
第三个改进才是算法的选择,一个时间复杂度是常数级别的算法大多数时候都优于一个线性复杂度的算法。
最后一个改进是代码层面的优化。有些代码优化是明显有效的,比如将复杂的重复运算从循环中移出,在逻辑判断时,廉价的判断放在最前面;另一些就不那么明显了,比如当a是一个整数时,用~a+1表示-a,这有些“玩花”的意味,而且并不见得能提高效率,或者效率提升的并不明显,只会让别人迷惑。难以置信的是,也许是为了更能体现出对某种编程语言的精通,软件开发者们往往对代码层上的“玩花”更感兴趣,对其它的改进反而置若罔闻,这也是我们随处可以看到“粘合剂代码”和“意大利面条代码”的原因。
大O表示法
在算法分析时,我们对影响算法的主要因素更感兴趣。当算法效率随着问题规模增长逐渐逼近一个上界时,使用大O表示法。
大O的相关定义
f 和g 是定义在正整数的子集上的函数。如果存在常数c 和k,使得对所有的n≥k,有|f(n)|≤c|g(n)|,则称f是O(g(n))或f是O(g),读作f是g的大O(f is big-O of g)。如果f是O(g)的,f的增长比g慢;如果f是O(g)的,并且g是O(f)的,则称f和g是同阶的,二者的增长速度相差无几。
看起来不是那么容易理解,我们用几个例子来说明。
示例1 用O表示f(n) = n3/2 – n2
使用大O的目的是算法分析,n是算法中问题的规模,因此只考虑n是正整数的情况。
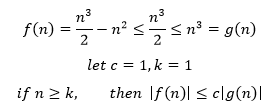
因此f是O(g)的,g=n3,f是O(n3)的,f的增长慢于n3。在本例中,c和k也可以选择其它的常数,当然也可以选择其它的函数作为g,因此也可以说f是O(n3/2)。但由于大O表示法的目的是尽量简化表达式,在数学优化中,常系数1/2又起不了什么作用,因此我们省略这个常系数,使用更简单的O(n3)。
示例2 用O表示f(n)=2n4 – n3和g(n)=n4

因此,当k=1,c=2时,f是O(g)的。反过来:
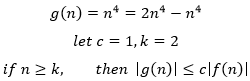
因此,当k=2,c=1时,g是O(f)的。根据定义,f和g是同阶的。
示例3 NlgN = O(?)
根据函数的增长一节的内容:
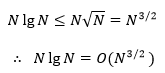
这里需要明确函数逼近和大O逼近的差异:使用函数逼近时,如果cg(n)在n≥k时逼近f(n),那么cg(n)的值可能比f(n)大,也可能比f(n)小,随着n的增大,二者趋近于等同;使用O(g)逼近时,cg(n)在n≥k时总是大于等于f(n),随着n的增大,二者趋近于等同,或O(g)比f(n)略大。
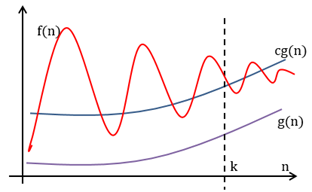
函数逼近

大O逼近
大O表示法的意义
由示例1可以看出,如果说f是O(g),那么g是一族函数,因此从严格意义上说,用O表示法的数学分析结果是不精确的。尽管如此,我们在进行算法分析时仍然喜欢使用O表示法,这主要基于以下三点原因。
第一个原因是O表示法可以用简单的表达式逼近真实结果,从而在不需要关心程序细节的情况下对程序效率和问题规模的关系作出预测。当问题规模增长时,基本操作要重复执行的次数必定也会增长,我们最关心的是这个执行次数以什么样的数量级增长,这个数量级就称为算法的渐近时间复杂度(asymptotic time complexity),简称为时间复杂度,用T(n)来表示。g(n)是一个和T(n)拥有相同数量级的函数,这类g(n)的集合就是O(g)。正如我们非常关注程序的内部循环一样,O(g)可以让我们忽略问题的小项,明确影响问题的首要项,进而用简洁的表达式逼近真实的结果。
另一个原因是可以限制我们在忽略影响问题的小项时所犯的错误。我们通常是在假定问题规模相当大时进行算法分析,但是如果恰巧n<k,那么此时再说算法的时间复杂度是O(g)就不恰当了。在这种情况下,O表示让我们给予问题规模足够的关注,我们宁愿选择一个运行时间是N4纳秒的运算,而不是一个N小时的运算。
最后的原因是我们常常对算法在什么时候会变慢更感兴趣,O表示法可以让我们基于算法运行时间的上界对算法进行分类,以便为算法排名。
这里重点解释第一个原因。假设有一个特定的算法需要执行两次循环,其中外层执行了N次循环,内层执行了M次循环:
1 num1, num2 = 0, 0 2 for i in range(N): 3 num1 += 1 4 j = 1 5 while j < N: 6 num2 += num1 7 j *= 2
假设内存循环每一次执行计算的时间是a0,平均迭代次数是M,外层循环执行一次计算的时间是a1,初始化的时间是a2,这段代码执行的总时间是:

由于a1N和N同阶,因此可以使用O(N)表示a1N的运行效率。再进一步假设,由于M远小于N,因此可以使用lnN近似地表示平均迭代次数。当使用O表示法时,并不需要找出具体的a0, a1, a2,只要知道它们是一个常数,当N较大时,总时间就可以近似地表示成:
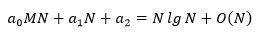
当问题规模翻倍时,和原问题总复杂度的比:
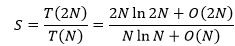
其中:

由此可以用O表示法计算S:

由于2/lnN和1/lnN是等阶的,因此S最终可以近似地表示成:
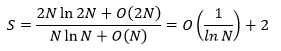
这就是时间复杂度的渐进公式。当N→∞时,S的极限是2,渐进公式能够让我们不需要关心实现的具体细节就可以对算法的效率做出预测。这里也同时看出了渐进表达的不精确性,2/lnN应当是2倍的1/lnN,但我们有理由相信,对于一个大N值,常系数2起不到关键作用,虽然丧失了数学的精确性,但获得的表达上的简单,因此在算法分析时仍然认为二者的效率等同。
大Θ
我们总是对改进算法充满热情,然而程序的效率最终会达到某个终点,对于给定的问题,我们需要知道什么时候应该停止改进,因此需要寻找算法的下界,此时需要用到Θ表示法。
大Θ的相关定义
f 和g 是定义在正整数的子集上的函数。如果存在常数c1,c2 和k,使得对所有的n≥k,有c1g(n) ≤f(n)≤c2g(n),则称f是Θ(g(n))或f是Θ(g),读作f是g的大Θ(f is big-theta of g)。显然Θ(g)是一族函数,由于f夹在c1g(n)和c2g(n)之间,因此Θ(g)中也包括f,Θ(g)中的所有函数都是同阶的,即f=O(g),g=O(f)。
Θ和O存在一些区别,O表示法只强调了渐进上界:
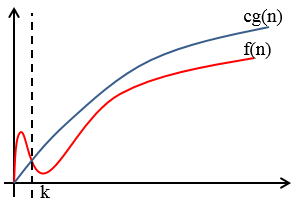
f=O(g)只强调了渐进上界
Θ表示法除了强调同阶之外,还强调了渐进下界:
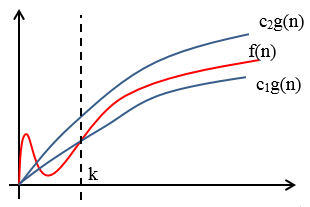
f=Θ(g)同时强调了渐进上界和下界
在算法分析中常用的阶是Θ(1),Θ(lnN),Θ(N),Θ(NlnN),Θ(N2),Θ(N3) ,Θ(2N)。
前面曾经说过:“对于LogN来说,对数的底数会影响常数的值,但影响不大”,因此我们在算法分析中用自然对数lnN。这句话的确切含义是,对于f(n)=logb(n)与g(n)=ln(n)来说,f是Θ(g)——对于任何底数的logb(n)都与ln(n)等阶。真的如此吗?来看一个简单的证明。
令a是一个常数,根据换底公式:
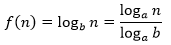
当a=2时:

反过来,还是根据换底公式:
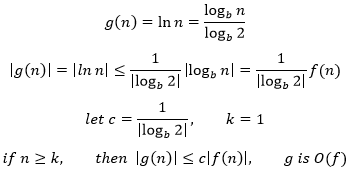
因此二者同阶,可以用Θ(lnN)表示。
大Θ的规则
Θ有几个常用的规则,它们对于O同样适用:
1. Θ(1)是增长最低的,具有0增长的特性;
2. 对于任意函数f,如果存在常数a≠0,则Θ(af) = Θ(f);
3. 如果h是一个非零函数,并且Θ(f)低阶于Θ(g),则Θ(hf)低阶于Θ(hg);
4. 如果Θ(f) 低阶于Θ(g),则Θ(f+g)= Θ(g);
5. 对于任意nk和a>1,Θ(nk)的增长速度要慢于Θ(an),也意味着大于1为底的指数函数要比所有的幂函数增长的都快。
示例 an2 + bn + c=Θ(?),ln(n) + an=Θ(?),1.1n+n10 =Θ(?)
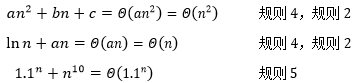
对于某些问题,我们能够证明任何算法都必须使用特定数目的基本操作;而对于另一些问题,下界的证明并不容易,正因为如此,我们才更多地看到O表示法。
二分查找有多快
对于一个有序的大型集合,如何找出其中有一个元素是集合中的第几项?一个不假思索的方案就是蛮力查找。假设有一个大型有序数组data_set,下面的代码能够找出val是数组中的第几项:
def search_bf(data_set, val): for i in range(0, len(data_set)): if data_set[i] == val: return i return -1
对于一个有N个元素的数组,search_bf在最坏情况下要执行N次循环,平均情况下执行N/2次,因此算法的时间复杂度是O(N)。它的改进版就是著名的二分查找:
def search_bin(data_set, val): low = 0 high = len(data_set) - 1 while low <= high: mid = (low + high) // 2 if data_set[mid] == val: return mid elif data_set[mid] > val: high = mid - 1 else: low = mid + 1 return -1
我们都知道二分查找的性能远高于蛮力法,对于每一次折半,问题规模都缩小了2倍,这等同于下面的递归公式:

其中的1可以理解为迭代一次的计算度量,N是问题的复杂度,当然,只有N能被2整除时上式才有意义。假设问题的复杂度是N=2n,对于每一次折半,问题规模都缩小了2倍,公式可以进一步计算:
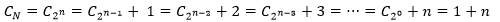
通过1+n次运算得出了CN,只要计算出n的值就可以得到问题的时间复杂度:
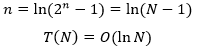
lnN的增长远远慢于N,这也是折半查找的效率远高于蛮力法的原因。
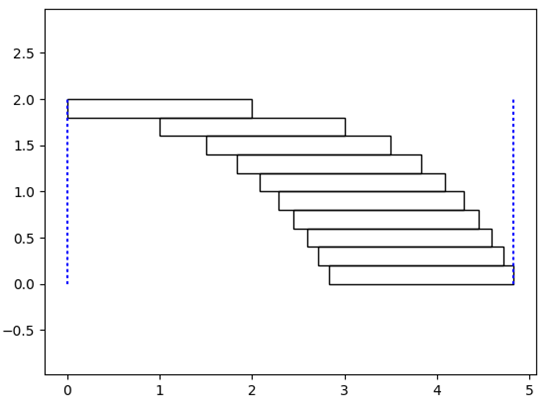
积木能搭多远
女儿喜欢搭积木,有一天她问我,能不能用长方形的积木在床上搭一个“跨床大桥”?我随口告诉她不可以,但是她仍然不断尝试,下图是她的做法:
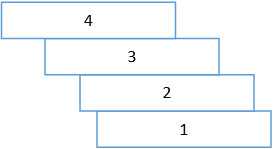
编号是积木摆放的顺序,1号第一个摆放的,4号是最后一个摆放的。暂且把能否搭成大桥放到一边,先说这种方法并不能发挥每一块积木的最大价值。我当然比幼儿园的小朋友聪明一点,使用了另一种方法,从终点开始向下搭:
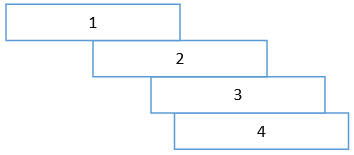
抛开积木的宽度,假设每块积木的长度是2,那么它的重心是在1的位置,如果第二块积木的边缘正好能够支撑住第一块积木的重心,则两块积木能够搭成最远的大桥。现在,1号和2号形成了一个新的整体,它的重心将发生偏移,用3号的边缘支撑住新的重心……以此类推,每一块积木都能够充分利用,这就是算法中的“贪心法”。
虽然是最优方案,但是积木的利用率显然越来越低,随着积木的增多,累加的长度是趋近于某一个极限还是能达到无限远端?在尝试回答这个问题前,先来复习一下物理学中关于重心的公式。还是抛开积木的高度,设Ci和mi表示第i块积木的重心位置和质量,则n块积木搭在一起的重心位置是:

每块积木的长度都是2,因此第N+1块积木的重心位置是上面N块积木的重心位置加1:

设每块积木的质量是1,把N块积木看成一个整体,它总质量将是N,因此N+1块积木的总体重心是:

这是一个递归表达式:

好了,这就是最终的重心位置,当N趋近于无穷时,lnN也趋近于无穷,看来随口的答案并不正确。然而搭桥工程的进度相当缓慢,想要达到lnN的长度,需要有2N块积木,又是一个有O(2N)复杂度的工程,根本不具备可操作性,这样看来,随口的答案也不是那么不靠谱。
“跨床大桥”的工程肯定是没法实际操作了,使用程序模拟一下小规模问题(这里的问题规模是桥的长度,程序中的输入是积木的数量)还是可以的:
import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as mpathes # 积木重心缓存 C = [0, 1] def get_Cn(n): '''搭到第n层时,整体重心在x轴的坐标''' if n <= 1: return C[n] Cn = get_Cn(n - 1) + 1/n C.append(Cn) return Cn def paint(n): fig, ax = plt.subplots() # 每个积木的长度和宽度 u_lehgth, u_weight = 2, 0.2 # 设置每个积木的位置 for i in range(n): xy = np.array([get_Cn(i), u_weight * (n - i - 1)]) rect = mpathes.Rectangle(xy, u_lehgth, u_weight, fill=False) ax.add_patch(rect) # 积木的起点和终点位置(在start和end之间搭积木) start = ([0, 0], [0, u_weight * n]) end = ([get_Cn(n - 1) + 2, get_Cn(n - 1) + 2], [0, u_weight * n]) plt.plot(start[0], start[1], color='blue', linestyle=':') plt.plot(end[0], end[1], color='blue', linestyle=':') plt.axis('equal') plt.show() if __name__ == '__main__': paint(10)
作者:我是8位的
