注:前提是知道什么是消息队列。不懂的去搜索各种消息队列入门(activeMQ、rabbitMQ、rocketMQ、kafka)
1、为什么要使用MQ?(MQ的好处:解耦、异步、削峰)
(1)解耦:主要解决系统间的耦合度
场景是系统A会产生用户ID:userId,要把userId通过调用系统BCD的接口传给他们做业务处理。若添加新系统,也需要此userId,则要再加一个接口调用。耦合严重。
解耦的做法就是:在系统A与系统BCD之间,增加消息队列MQ,系统A产生userId后,将其放入MQ,系统BCD通过监听MQ,来消费userId。
以上,通过MQ,发布和订阅消息的pub/sub模型。
原耦合模型:用户请求--->A---->BCD; 现解耦模型:用户请求---->A--->MQ---->BCD;
(2)异步:主要解决请求的耗时
场景是用户发送请求到系统A,系统A执行完本地SQL(耗时100ms)后,还要调用BCD三个系统的接口,假设三次调用都耗时200ms。那么,总共一次请求耗时700ms。一旦调用接口变多,耗时会变得更长。
使用MQ解决耗时长的办法就是,在系统A与系统BCD之间分别增加MQ,系统A将数据消息写入MQ(耗时5ms),成功就返回并提示用户,剩余的BCD系统自己监听MQ并做相应业务操作。那么,这个请求耗时也就是100+5 = 105ms。
模型跟解耦一样。
(3)削峰:主要解决并发请求百万级时系统挂了
MYSQL处理能力有限,大概最高2000/秒
场景:某秒杀活动,同一时间大量用请求全怼过来了(100万请求),不用MQ的话系统就被打死了(数据库处理不过来了)
模型是: 用户同时的100万请求--->系统A----每秒5000个请求---> mysql
使用MQ:将用户请求先放入MQ,有多少放多少,系统A每次去拿2000个,并请求MySQL资源,系统不会被打死
模型是:用户100万请求--->全写入MQ---> 系统A每次去MQ消费2000条 --->mysql
2、MQ的缺点
(1)系统可用性降低:ABCD四个系统,忽然加一个MQ进来,维护变多,万一忽然挂了,影响下游多系统
(2)系统复杂性升高:怎么保证MQ里的消息没有被重复消费?消息丢失了怎么处理?消息传递的顺序性怎么保证?
(3)一致性问题:异步里面,A处理完直接返回成功了,但是最后一个系统D写入失败了,咋整
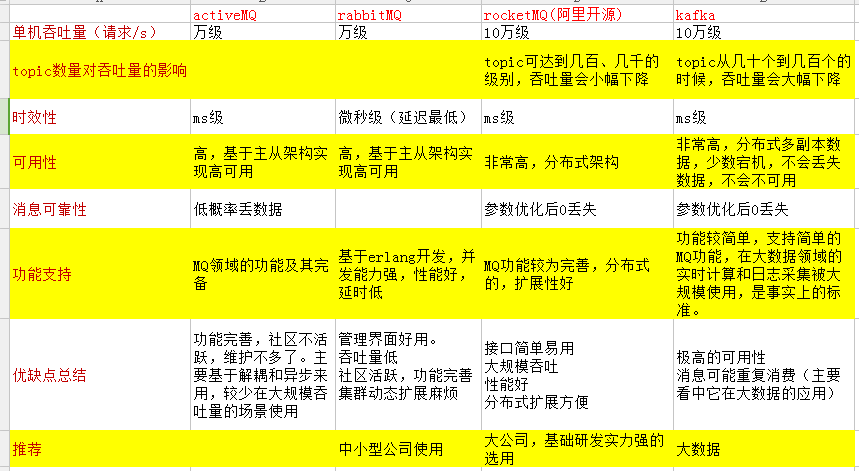
3、activeMQ、rabbitMQ、rocketMQ、kafka的区别
4、如何设计一个MQ,架构如何设计?
汇总几个解决的MQ的线上问题来回答
(1)支持可伸缩性。即需要的时候快速扩容,增加吞吐量和容量,参考kafka的分布式系统
(2)MQ的数据要不要落磁盘?肯定要,保证数据在异常情况下不丢。落的时候顺序写入(kafka的思路)
(3)MQ的高可用性。参考kafka,多副本及leader--follower挂了重新选举的机制
(4)支持数据0丢失。参考kafka数据丢失的解决方案,消费端手动提交offset,kafka端设置参数保证副本个数、及ack要全返回才算写入成功。