1. 内存基本介绍
1.计算机基本结构:
电脑之父——冯·诺伊曼提出了计算机的五大部件:输入设备、输出设备、存储器、运算器和控制器
如图: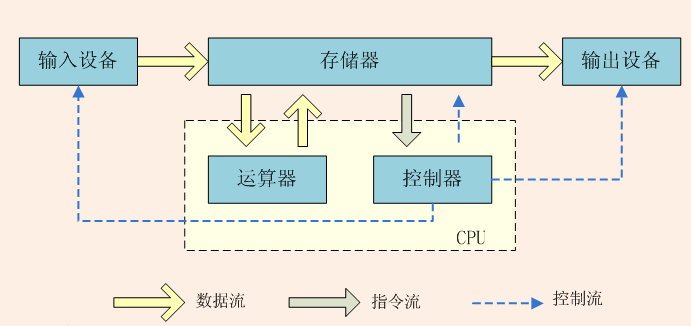
输入设备:键盘鼠标等
CPU:是计算机的运算核心和控制核心,让电脑的各个部件顺利工作,起到协调和控制作用。
存储器:一系列的存储设备,硬盘,内存等
输出设备:如打印机,扬声器等
2.存储器:
我们看一下系统中存储器的层次结构:
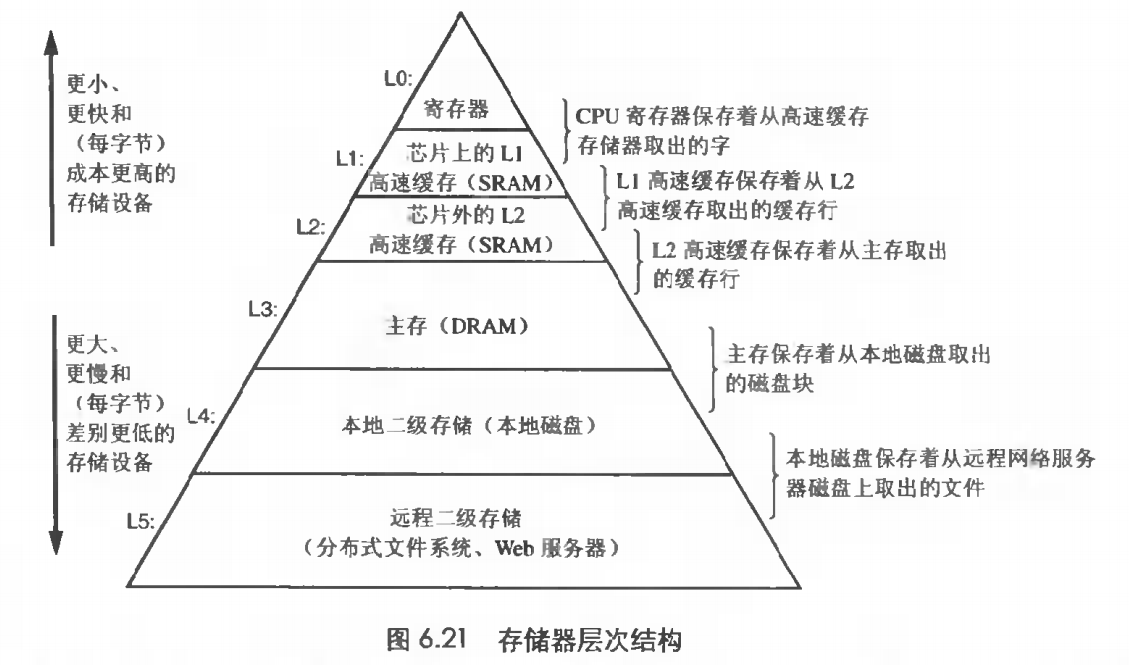
图中L0-L5分别表示系统中所有存储器的层次结构,其中包括高速缓存,主存,磁盘等。 越上层的存储器造价越高,速度也越快,也更加靠近cpu。 正常情况下,我们在开发应用程序时,使用的是主存(L3)。
在开发应用程序时,我们接触最多的应该是内存和磁盘文件,也知道访问磁盘存储器的时候,需要进行I/O操作,相比内存十分耗时间,那两者具体相差多少,我们可以看一下下面这一段描述(DRAM为主存):

也就是说,在这个例子里面,磁盘访问时间是内存的10万倍,当然,数据不是绝对的,在不同情况下,数据应该会存在偏差,我们大概有个概念就可以。
3.内存和磁盘的主要作用:
硬盘:存储资料和软件等数据的设备,有容量大,断电数据不丢失的特点。也被人们称之为“数据仓库”。
内存:1. cpu无法直接访问硬盘,必须通过内存,因此内存一个作用是负责硬盘等硬件上的数据与CPU之间数据交换处理;2. 缓存系统中的临时数据。3. 断电后数据会丢失。
2. Linux 系统内存管理
一. 物理寻址与虚拟寻址
计算机系统的主存(内存)被组织成一个由M个连续的字节大小的单元组成的数组。每个字节都拥有唯一的物理地址,cpu直接对物理地址进行寻址称为物理寻址,很早期的pc使用的是物理寻址,示意图如下:
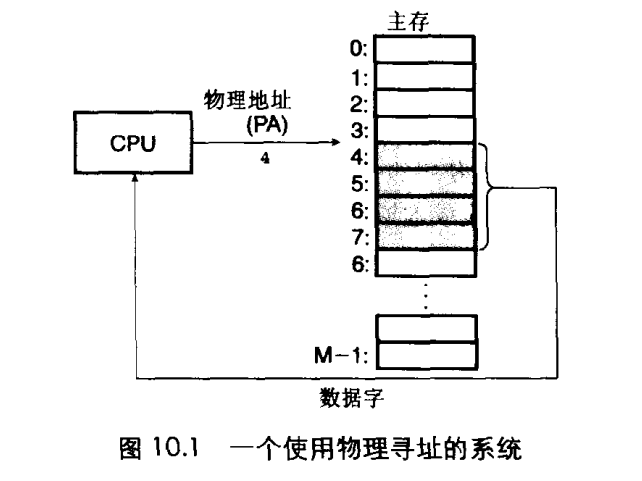为通用计算设计的现代处理器使用的是虚拟寻址。根据虚拟寻址,cpu在访问主存之前,需将虚拟地址转换成物理地址(通过地址翻译MMU)。示意图如下:
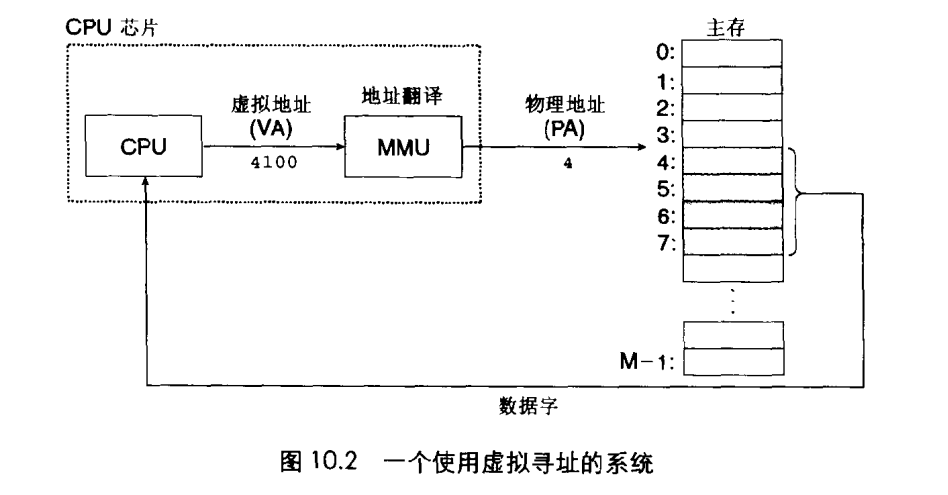也就是说,在虚拟寻址的系统中,一个数据对象拥有两个地址空间,关于地址空间,我们看一下下面这一段话:
那这两个地址空间多大呢? 首先,我们知道一个32位的系统,每一个地址对应的数据空间为32位,也就是4个字节。一个地址用32位二进制表示,那么所有地址的可能性就是为2的32次方,大小为4G。因此,虚拟地址的地址空间和物理地址的地址空间取决于虚拟地址和物理地址的位数。
二. 系统引入虚拟地址的原因
我们以Linux系统为例,来解释一下为什么要引入虚拟地址,直接用物理地址不是更快吗? 最根本的原因是因为Linux系统是一个多任务系统,而虚拟地址可以很好的保证系统进程的并发性,独立性。
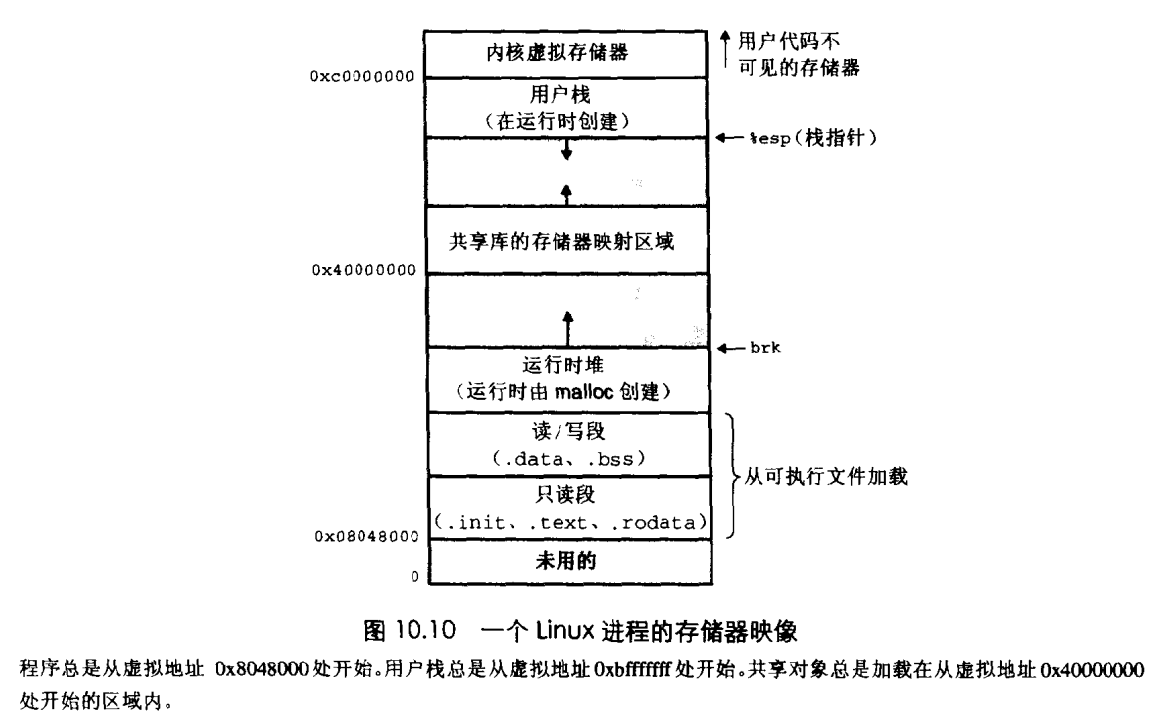
Linux 进程内存分配结构图(原因中有涉及):
原因:
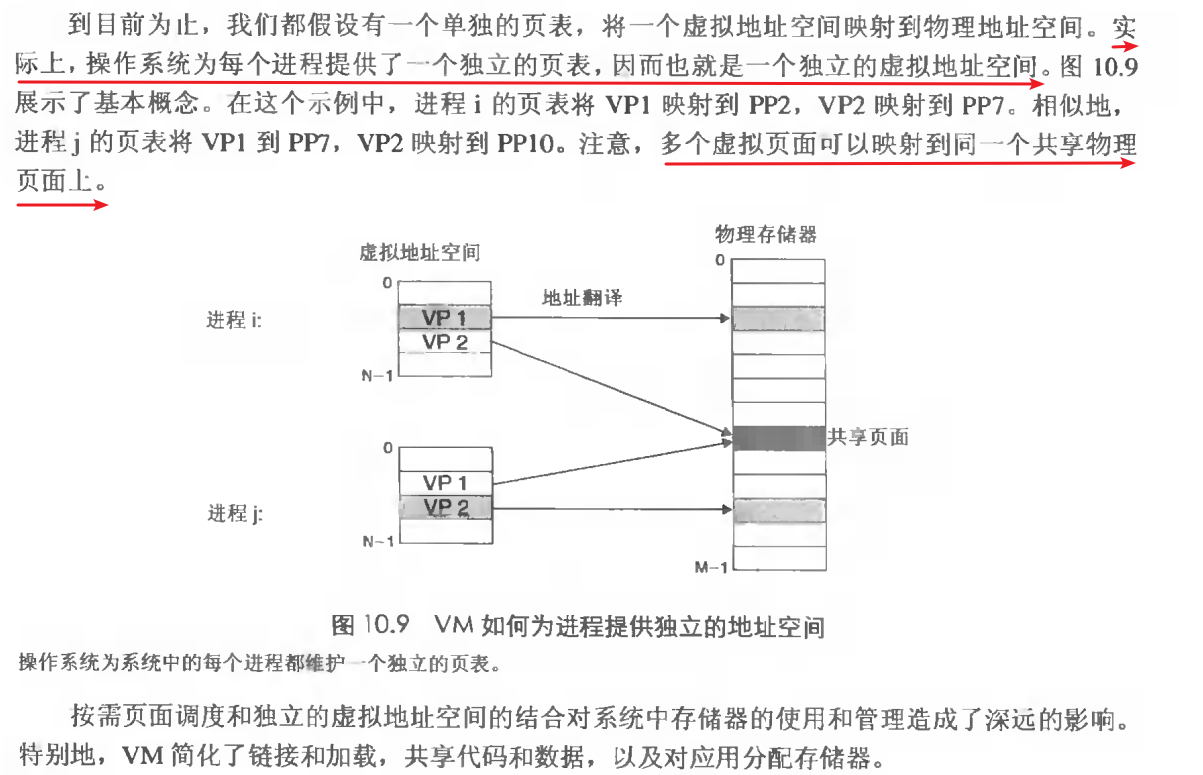
1. 简化存储器管理。每个进程一个独立页表,独立虚拟地址空间
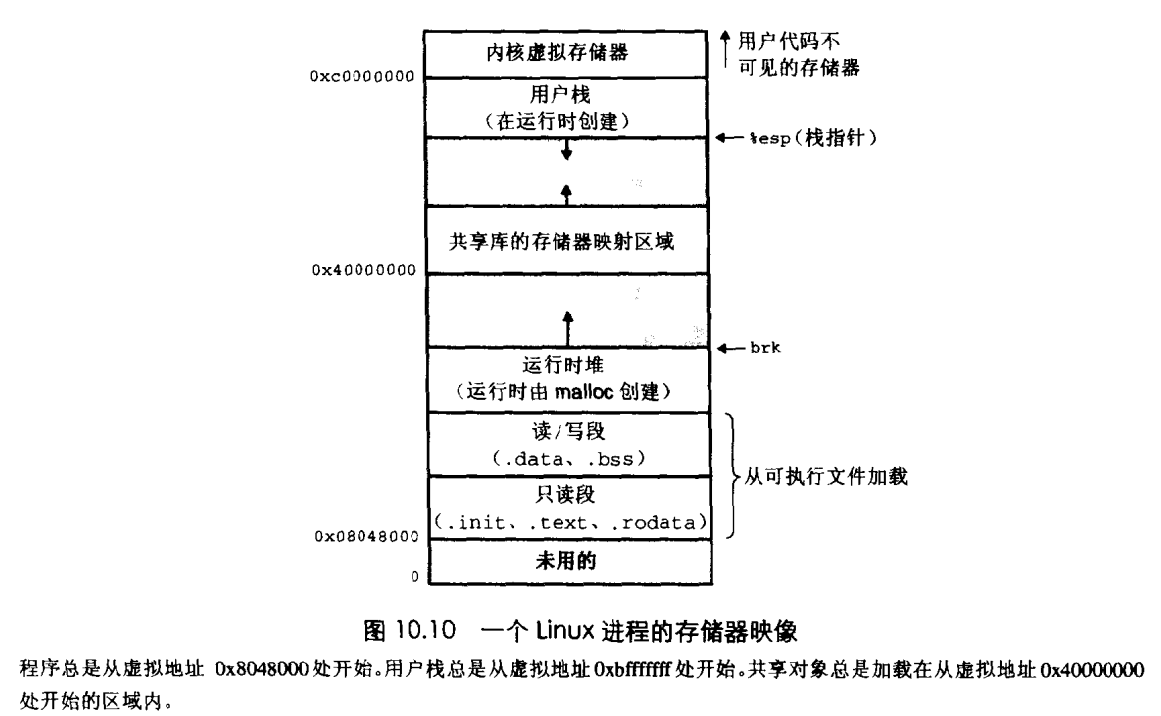
1.1. 简化链接。因为进程虚拟地址空间独立,以32位系统为例,每个进程分配的虚拟内存均为4G,其中堆段,栈,数据段,代码段各自所在的位置是一致的,这样可以简化链接器的设计与实现。如图:10.10
1.2. 简化共享。一般而言,每个进程都有自己私有代码,数据,堆以及栈区域,是不和其他进程共享的,那这时候就需要多个物理页面来进行存储,但是在一些情况下,还是会需要进程之间来共享代码和数据。例如:操作系统的内核代码,c程序中的标准库代码,比如printf。操作系统将不同进程中适当的虚拟页面映射到相同的物理页面,从而达到多个进程共享这部分代码的一个拷贝。而不是在每个进程中都包括单独的内核和c标准库拷贝。
1.3. 简化存储器分配。分配的物理页面可以不连续。
1.4. 简化加载。 和链接差不多,进程加载elf文件到存储器的虚拟地址是相同的。
2. 保护存储器。控制用户进程对存储器的访问,对某些特殊区段,用户进程禁止访问修改,保证安全性和独立性
三. 虚拟存储系统如何工作
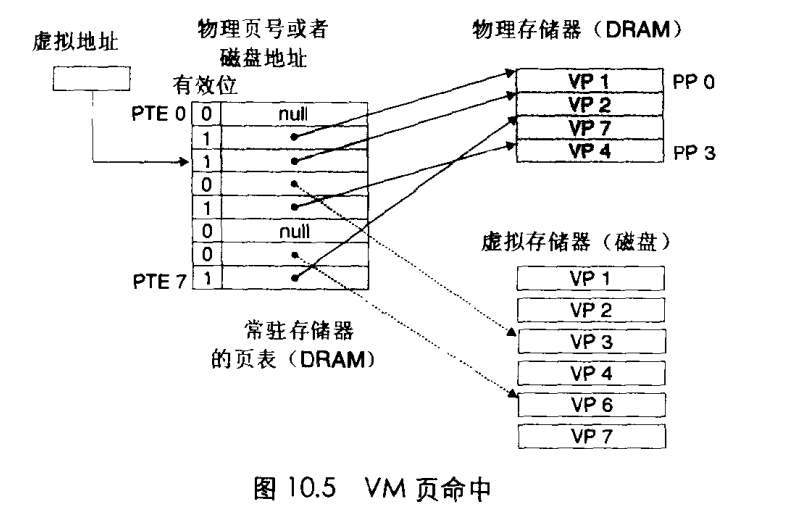
同任何缓存一样,虚拟存储系统必须有某种方法来判定一个虚拟页是否存在于DRAM中,如果存在,还需要确定这个虚拟页存放在哪个物理页。如果没用命中,系统必须判断这个虚拟页存放在磁盘哪个位置,在物理页中选择一个牺牲页,并将虚拟页拷贝到DRAM,替换这个牺牲页。要完成这部分工作,需要哪些角色参与进来呢? 看下面介绍:

看上图,可以清楚到看到,虚拟内存是如何映射到物理地址和磁盘的。下面我们来介绍一个概念页命中,当cpu从虚拟内存中读取一个字节,如果通过页表可以成功映射到物理存储器,则称为页命中,具体见下图:
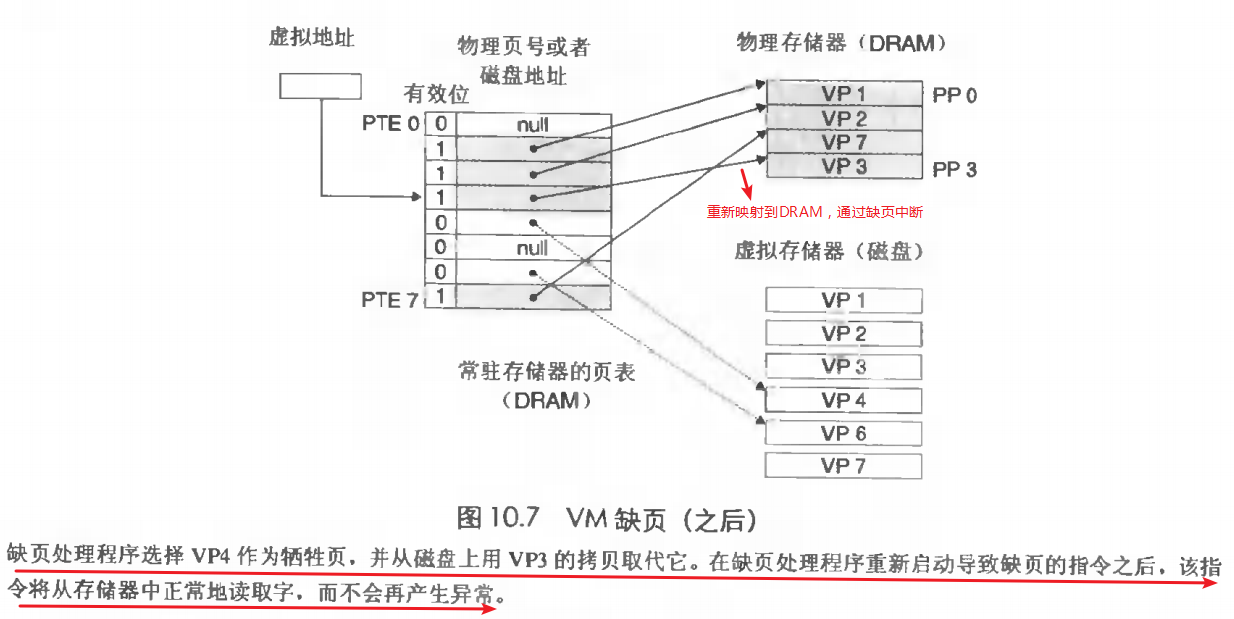
如果虚拟页没有映射到物理内存,而是映射到磁盘,那这种现象就叫做缺页。这时候,地址翻译硬件,判断虚拟页未缓存到DRAM中,然后会触发一个缺页异常(也叫缺页中断)。将虚拟页重新映射到DRAM。 在磁盘与存储器之间传送页的活动叫做页面调度,涉及的算法叫页面置换算法(如:OPT,FIFO,LRU) 。 缺页中断过程如下。
缺页前:
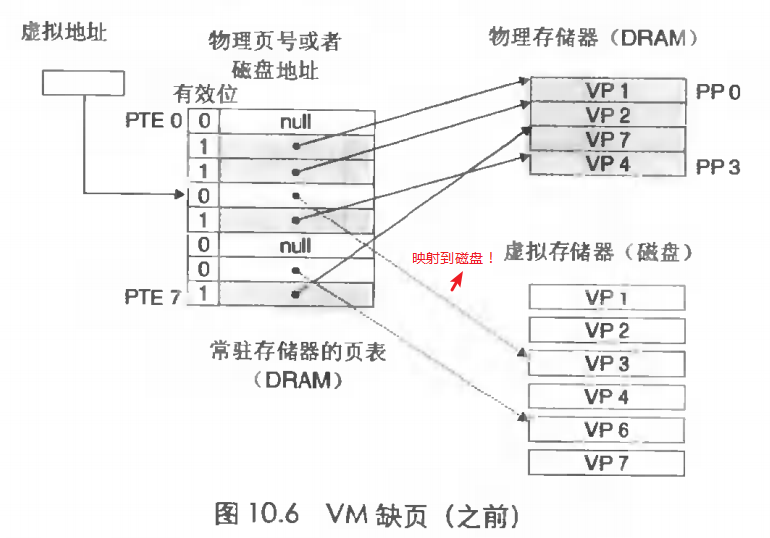缺页后:
Linux系统层面的内存管理调度大概就介绍到这里,下面我们进入进程层面的内存分析!
3. Linux 进程级内存管理
首先,我们再次把进程的空间结构图附上:
一. 内核态和用户态
我们知道程序访问的地址都是虚拟地址,用32位操作系统来讲,系统访问的地址空间为4G,linux会将4G分为两部分,如上图所示,其中从0x00000000 到 0xbfffffff的线性地址为用户空间,0xc0000000 到 0xffffffff为内核空间
进程在用户态只能访问0~3G,只有进入内核态才能访问3G~4G 。
用户空间:在Linux中,每个用户进程都可以访问4GB的线性虚拟内存空间。其中从0到3GB的虚存地址是用户空间,通过每个进程自己的页目录、页表,用户进程可以直接访问。
内核空间:从3GB到4GB的虚存地址为内核态空间,存放供内核访问的代码和数据,用户态进程不能访问,也就是说对于用户代码来说是不可见的,只有内核态进程才能寻址。所有进程从3GB到4GB的虚拟空间都是一样的,linux以此方式让内核态进程共享代码段和数据段。(页表就存放在内核虚拟空间)
二. 进程用户态空间
如果不是做内核开发,在写代码的过程中,我们主要涉及到的是用户态空间,在代码层面可以进行优化和分析的也是用户态空间,内核空间主要由系统进行管理,因此我们着重介绍一下用户态空间,至于内核空间,其中可能涉及到一些比较好的算法思路(伙伴,slab等),如果有时间可以单独去学习其思想。
程序空间:
1. 堆段
对于堆段,程序层面我们平常会使用new,delete,malloc,free方式来申请内存。而Linux内核会为进程分配一段内存地址,随着进程申请内存增加,进程会通过系统调用brk,让内核来拓展这段内存空间;当进程释放内存时,进程又通过系统调用brk,来告诉内核缩减这段内存,内核将其一部分物理地址进行回收。当程序调用内存申请接口(malloc)时,具体分配流程如下:

1.1. 小块内存分配
对于堆段的内存分配,如果是小块内存分配,为了减少内存碎片,glibc库对于某些相邻的内存肯进行合并,但是为了节省cpu和内存,对于过小的内存并不会进行合并,具体阈值可以通过接口进行设置,如下接口:
1.2. 大块内存分配
如果是大块内存分配,当申请内存数量大于一个阈值,glibc会采用mmaps为进程分配一块虚拟空间,而不是采用brk,来拓展栈顶指针。如下接口:

1.3. 内存释放
至于内存释放,当我们调用free时,系统并不会立即将内存回收,而是将其cache,保留到下次使用。原因是频繁申请释放会造成大量的系统调用,会影响进程效率。对于free后,是否系统回收,也可以通过接口设置。如下接口:
1.4. 内存空洞
还有一个概念我们需要知道,就是内存空洞,就是一段内存,中间的释放了,但是堆顶没用释放,导致所有的内存无法被系统回收。 对于内存空洞,见下面这段文字描述:

注:如何区分内存空洞和内存泄漏

从上面描述知道,对于内存空洞,我们只需了解即可,按照就近原则释放即可。当然对于内存空洞,其实是有另外的内存管理机制可以解决的,如果感兴趣,可以另外了解一下。
2. 栈段
用于维护函数调用的上下文空间,一般为 8M ,可通过 ulimit –s 查看(函数堆栈打印就是基于此实现) 。 那在使用的过程中,我们需注意,1. 尽量避免在栈空间申请大量内存;2. 尽量避免递归使用
3. 数据段
也就是我们进程空间中的.bss和.data,主要用来保存全局变量、静态变量,两者区别:
4. 代码段
代码段是整个系统共享的,位于进程只读段。
5. 共享映射
我们看进程的空间结构图可以知道,还有一个文件映射区域,这里只要是动态库、共享内存等映射物理空间的内存,一般是 mmap 函数所分配的虚拟地址空间。
四. 总结
文章中出现的图片和相关文字描述截图主要出自书籍<<深入理解计算机系统>>, <<嵌入式Linux性能详解>>,两本书都非常不错!
文章主要是对内存做了一个整体介绍,自底向上,从系统层面,进程层面,到用户代码层面,进行了详细的分析和总结,使得我们对Linux内存管理有了一个系统的认识!
2018年9月15日12:33:02