前言
Redis 是我们目前大规模使用的缓存中间件,由于它强大高效而又便捷的功能,得到了广泛的使用。
Window环境下载地址:https://github.com/tporadowski/redis/releases
Redis Cluster设计要点
redis cluster在设计的时候,就考虑到了去中心化,去中间件,也就是说,集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
那么redis 是如何合理分配这些节点和数据的呢?
Redis 集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key 分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。
注意的是:必须要3个以后的主节点,否则在创建集群时会失败,我们在后续会实践到。
所以,我们假设现在有3个节点已经组成了集群,分别是:A, B, C 三个节点,它们可以是一台机器上的三个端口,也可以是三台不同的服务器。那么,采用哈希槽 (hash slot)的方式来分配16384个slot 的话,它们三个节点分别承担的slot 区间是:
- 节点A覆盖0-5460;
- 节点B覆盖5461-10922;
- 节点C覆盖10923-16383.
Redis Cluster主从模式
redis cluster 为了保证数据的高可用性,加入了主从模式,一个主节点对应一个或多个从节点,主节点提供数据存取,从节点则是从主节点拉取数据备份,当这个主节点挂掉后,就会有这个从节点选取一个来充当主节点,从而保证集群不会挂掉。
假设集群有ABC三个主节点, 如果这3个节点都没有加入从节点,如果B挂掉了,我们就无法访问整个集群了。A和C的slot也无法访问。
所以我们在集群建立的时候,一定要为每个主节点都添加了从节点, 比如像这样, 集群包含主节点A、B、C, 以及从节点A1、B1、C1, 那么即使B挂掉系统也可以继续正确工作。
B1节点替代了B节点,所以Redis集群将会选择B1节点作为新的主节点,集群将会继续正确地提供服务。 当B重新开启后,它就会变成B1的从节点。
不过需要注意,如果节点B和B1同时挂了,Redis集群就无法继续正确地提供服务了。
话不多说下面以windows环境下在一个机器上模拟这样一个3主3从的集群
Redis Cluster 实践
1.下载Redis3.2 https://github.com/tporadowski/redis/releases 下载后解压可以看到已经内容
三主三从需要启动6个Redis服务端,我们本别定义端口为 7000,7001,7002,7003,7004,7005
为了方便区分配置文件同样以端口新建6个文件夹如下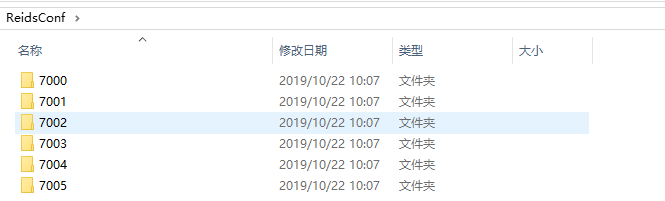
把Redis目录下的redis.windows.conf 分别复制到下面的文件夹中,然后修改配置文件中的端口
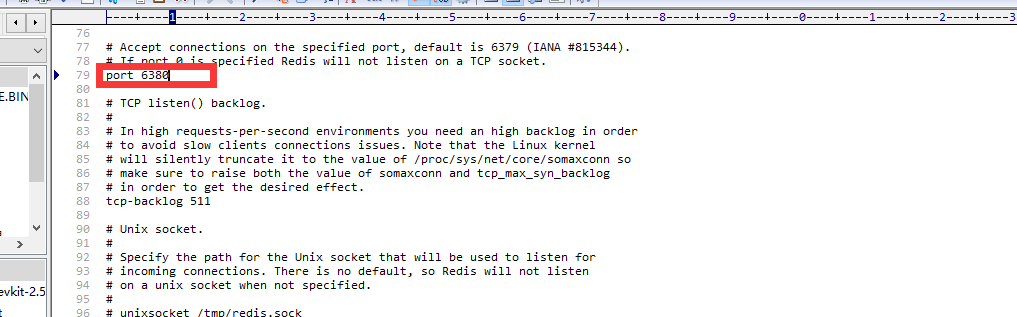

配置文件修改好了之后,我们新建一个批处理文件开快速将Redis 以Windows服务的方式启动起来

打开服务查看是否正常运行
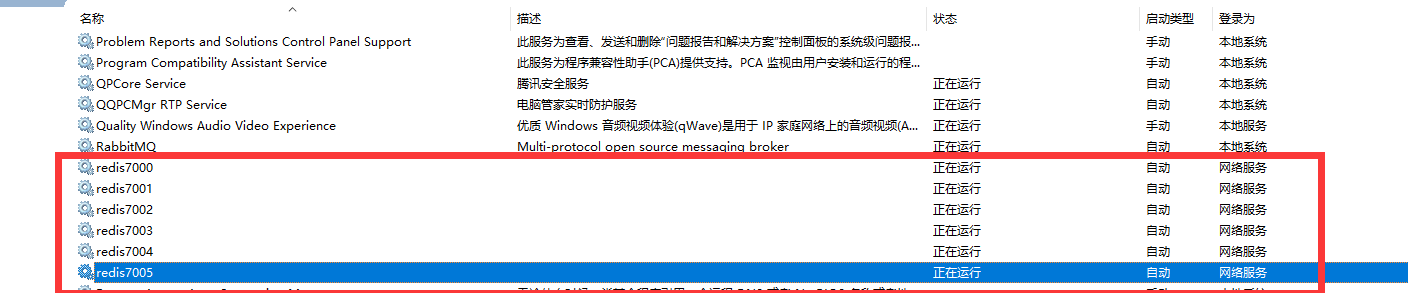
看到全部正在运行说明Redis服务器已经启动成功了,接下来我们就开始构建集群了,
搭建集群需要使用个工具Ruby 官方下载地址:https://www.ruby-lang.org/zh_cn/ 下载后安装,创建集群需要使 redis-trib.rb 这个文件可以从下面下载
链接:https://pan.baidu.com/s/1VmvYiE9D46YCIxcyUZlpOQ&shfl=sharepset
提取码:04xq
下载后将这个文件放在配置文件的目录同级
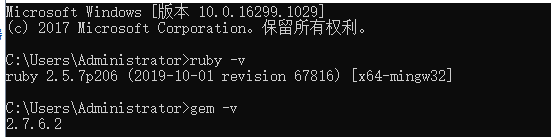
运行cmd 查看Ruby安装是否正常
安装 Ruby 连接Redis插件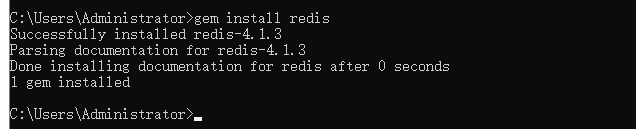
然后cmd到 redis-trib.rb 所在的目录我们开始创建集群
redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
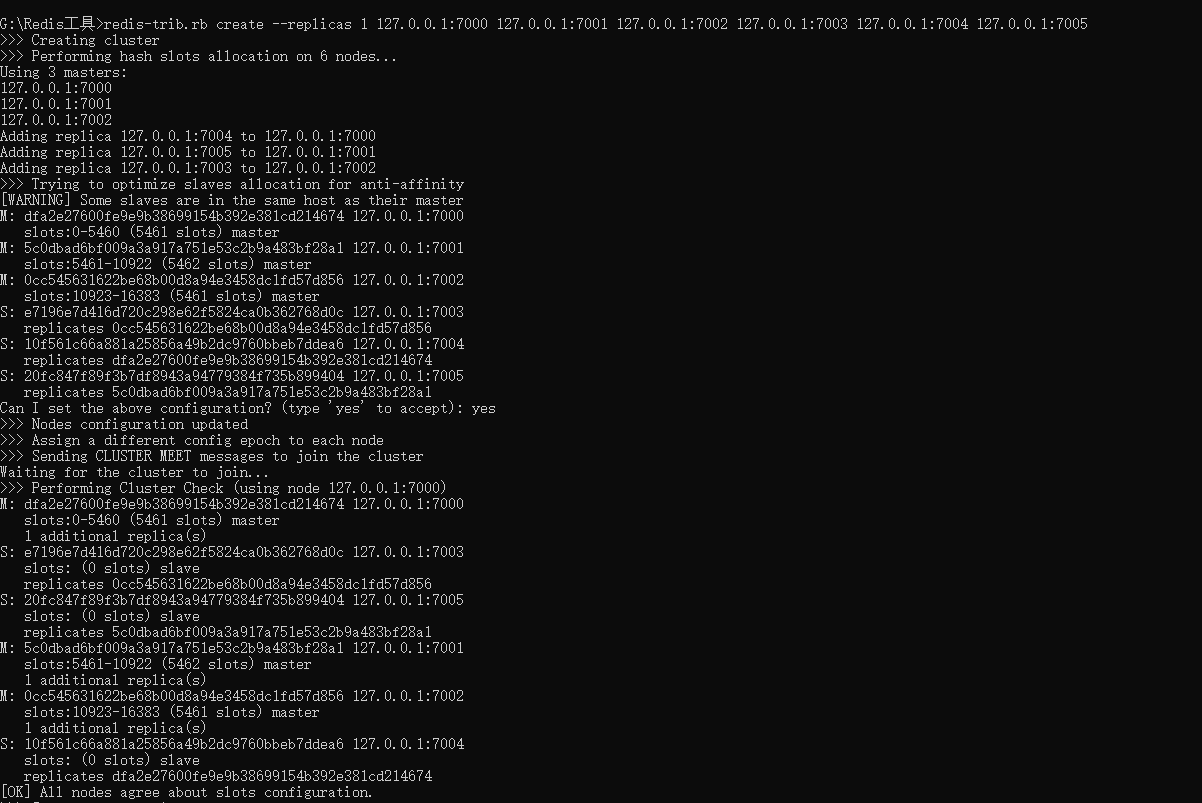
到这里我们的集群已经创建成功了,检查集群信息
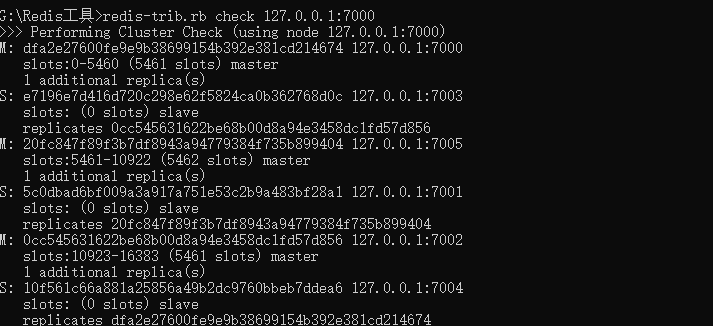
我们打开一个客户端测试下

我们可以关掉其中的任意一个主节点来测试,看是否会自动从节点切换为主节点....
若遇到创建失败等问题,检查防火墙的端口是否打开.