交叉熵(cross entropy)是深度学习中常用的一个概念,一般用来求目标与预测值之间的差距。
1. 什么是熵(Entropy)
1.1. 信息量

首先是信息量。假设我们听到了两件事,分别如下:
- 事件A:巴西队进入了2018世界杯决赛圈。
- 事件B:中国队进入了2018世界杯决赛圈。
仅凭直觉来说,显而易见事件B的信息量比事件A的信息量要大。究其原因,是因为事件A发生的概率很大,事件B发生的概率很小。所以当越不可能的事件发生了,我们获取到的信息量就越大。越可能发生的事件发生了,我们获取到的信息量就越小。那么信息量应该和事件发生的概率有关。
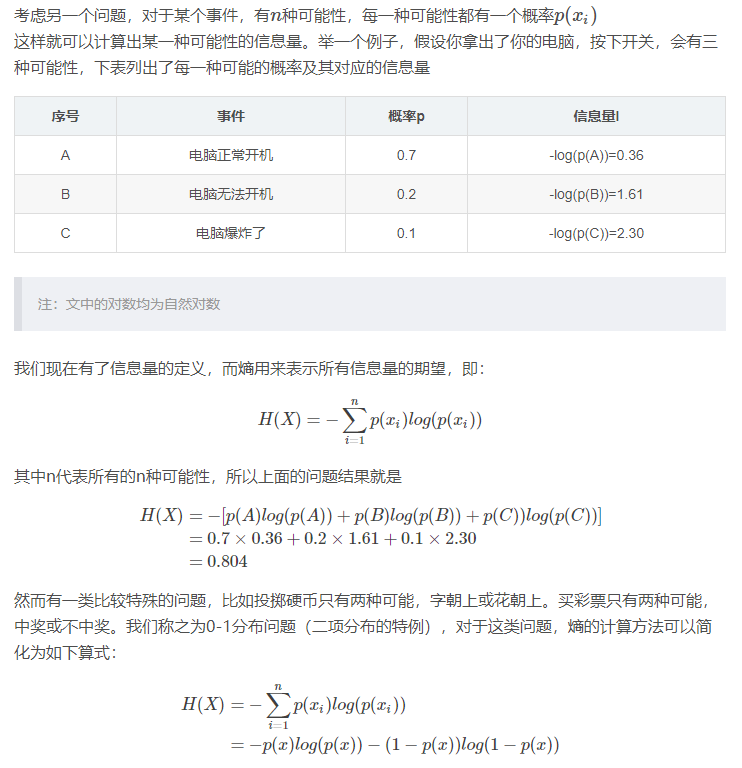
1.2. 熵
熵用来表示所有信息量的期望。
1.3. 相对熵(KL散度)
相对熵又称KL散度,如果我们对于同一个随机变量 x 有两个单独的概率分布 P(x) 和 Q(x),我们可以使用 KL 散度(Kullback-Leibler divergence)来衡量这两个分布的差异。

1.4. 交叉熵

2. 总结
一个简单的交叉熵修正不仅可以用来估计稀有事件的概率,还可以用来解决困难的组合优化问题(COP)。这是通过将“确定性”优化问题转化为相关的“随机”优化问题来完成的。Reuven Y.Rubinstein 还通过几个应用证明了CE方法的强大功能,作为解决NP难问题的通用实用工具。
交叉熵方法已成功应用于动态模型中稀有事件概率的估计,特别是涉及轻,重尾(light/heavy-tailed)输入分布的排队模型。目前,交叉熵方法能应用范围包括但不限于:缓冲区分配、静态模拟模型、电信系统的排队模型、神经计算、控制和导航、DNA序列比对、调度、车辆路线、强化学习、项目管理、重尾分布、网络可靠性分析、可修复系统。
传统交叉熵方法可以高效地处理大部分的简单优化问题,并且具有极快的收敛速度。但是当目标函数较复杂或约束函数数目较多时,由于交叉熵方法的收敛速度过快,所以比较容易陷入局部最优,计算性能不足;且如果初期的优化方向错误,则方法可能无法收敛。不过目前有一些研究专注于改进传统交叉熵方法。