SpringData入门以及为什么学习SpringData
写在最前:
学习一项新的技术,一个新的框架,总是要基于某个问题去学习,而不能是为了学框架而学框架,这样不仅学习过程痛苦,学习成效也不高。俗话说,熟能生巧,大概说的是使用的多了就用起来就顺手了的意思,如果单纯是为了学习而学习,而没有去实践它,学了也会很快就忘记。所以,在这个入门,我会从最简单的jdbc,到使用Spring的JdbcTemplate再到SpringData,一步步分析各自的优缺点,明明都可以做一样的工作,为什么要选SpringData而不是原生jdbc或者JdbcTemplate?原生JDBC和JdbcTemplate我们略微介绍,重点放在SpringData
正文
一 .原生JDBC
在原生的JDBC开发中,我们通常会先定义一个DAO接口,这里我们只举一个例子查询所有学生
public interface StudentDAO {
/**
* 查询所有学生
* @return 所有学生
*/
public List<Student> query();
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
实现StudentDAO接口:
public class StudentDAOImpl implements StudentDAO{
@Override
public List<Student> query() {
List<Student> students = new ArrayList<Student>();
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
String sql = "select id, name , age from student";
try {
connection = JDBCUtil.getConnection();//这里我们把获取连接操作写在一个工具类中,方便调用
preparedStatement = connection.prepareStatement(sql);
resultSet = preparedStatement.executeQuery();
Student student = null;
while (resultSet.next()) {
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
int age = resultSet.getInt("age");
student = new Student();
student.setId(id);
student.setName(name);
student.setAge(age);
students.add(student);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtil.release(resultSet,preparedStatement,connection);//关闭操作也写在工具类中,方便调用
}
return students;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
如果只有这个方法可能看不出什么问题,但问题就在于,我们的应用系统通常会涉及很多对数据库的CRUD操作,如果你使用JDBC,你会发现你大部分的时间是用于复制一份已有的代码,然后对sql语句以及结果集进行修改之类的操作而已,并且,这里的获得连接以及关闭连接封装在一个工具类中,如果是直接写在方法体内,你可能会发现,这个方法里50行代码核心只有5行。
这就暴露出一个问题,代码过于冗余,另外值得一提的是,原生的JDBC连接使用完需要手工关闭,如果没有关闭会导致数据库连接过多,而每次获取连接和关闭连接会加大数据库的负担。
然而优秀的程序员都是“懒”的,他们会想:我怎么能把时间花在copy一些冗余的代码上呢?这些冗余的代码基本上都是一样的,能不能用一个模板把它们封装起来,我需要写核心代码就行呢?没错,这就是接下来要讲的Spring的JdbcTemplate。
二. JdbcTemplate
第一步,还是先定义DAO接口,这里我们使用上面定义的接口,就不重复贴代码上来了。
这里还是实现DAO接口:
/**
* StudentDAO访问接口实现类:通过Spring jdbc的方式操作
*/
public class StudentDAOSpringJdbcImpl implements StudentDAO{
private JdbcTemplate jdbcTemplate;//使用SpringIoc注入
public List<Student> query() {
final List<Student> students = new ArrayList<Student>();
String sql = "select id, name , age from student";
jdbcTemplate.query(sql, new RowCallbackHandler(){
//RowCallbackHandler是一个接口,这里使用内部类的方式实现接口
@Override
public void processRow(ResultSet rs) throws SQLException {
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
Student student = new Student();
student.setId(id);
student.setName(name);
student.setAge(age);
students.add(student);
}
});
return students;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
这里解释一下这个接口:接口中的processRow方法参数是一个ResultSet,也就是一个结果集,我们可以定制自己对结果集的操作。
我们可以清楚的看到,相对于原生的JDBC,很多冗余的代码都不见了,代码也清爽了许多。这貌似看起来已经很不错了,然后程序员是真的很“懒”呀,他们又想:我们拿到结果集之后还要自己一个个将值设置到对象中,这个机械化的操作,能不能也有类似模板的东西帮我们去做?答案是可以的,结果集直接映射成对应的实体类,我们拿到的结果就是若干个实体类,省去了手动设值的过程,也就是ORM(Object Relational Mapping,对象关系映射)。
三. SpringData
先看看什么是SpringData?
Spring Data 项目的目的是为了简化构建基于 Spring 框架应用的数据访问计数,包括非关系数据库、Map-Reduce 框架、云数据服务等等;另外也包含对关系数据库的访问支持。
Spring Data 包含多个子项目:
- Commons - 提供共享的基础框架,适合各个子项目使用,支持跨数据库持久化
- Hadoop - 基于 Spring 的 Hadoop 作业配置和一个 POJO 编程模型的 MapReduce 作业
- Key-Value - 集成了 Redis 和 Riak ,提供多个常用场景下的简单封装
- Document - 集成文档数据库:CouchDB 和 MongoDB 并提供基本的配置映射和资料库支持
- Graph - 集成 Neo4j 提供强大的基于 POJO 的编程模型
- Graph Roo AddOn - Roo support for Neo4j
- JDBC Extensions - 支持 Oracle RAD、高级队列和高级数据类型
- JPA - 简化创建 JPA 数据访问层和跨存储的持久层功能
- Mapping - 基于 Grails 的提供对象映射框架,支持不同的数据库
- Examples - 示例程序、文档和图数据库
- Guidance - 高级文档
说了这么多,SpringData就是给我们提供了一种通用的代码格式,统一数据访问API。并且对于不同的数据库有很好的支持,不仅是关系型数据库,非关系型数据库也可以,在我看来SpringData是站在一个高的层次去统一API,底层可以是不同厂商的实现。可以参考下图 
首先我们做一个简单的DEMO,我们还是定义一个接口,注意这里我们继承了一个Repository接口,具体含义我后面会解释
public interface StudentRepository extends Repository<Student,Integer>{
public Student findByName(String name);
}- 1
- 2
- 3
然后我们就可以用了!!你看到这里可能会想,定义一个接口都没具体实现就可以使用,开玩笑吧?然而真的不需要我们去实现它,就可以使用了,当然这是有前提的,你的方法名需要按照一定命名规范。
现在我们解释一下为什么这么神奇,首先,Repository接口中第一个类型是你要映射的实体类类型,第二个类型是主键的类型,继承之后框架就能帮你实现映射功能,源码我们就不深入了,暂时知道是这样子就可以了,另外还可以使用注解的方式,就不用继承接口了。。
@RepositoryDefinition(domainClass = Student.class, idClass = Integer.class)
public interface StudentRepository {
public Student findByName(String name);
}- 1
- 2
- 3
- 4
而关于方法的命名规范,由于约定由于配置的思想,SpringData框架可以根据你的方法名,自动生成对应的SQL语句并执行,命名规范可以在官网中找到,搜索引擎搜一个也能找到,这里给出规则表
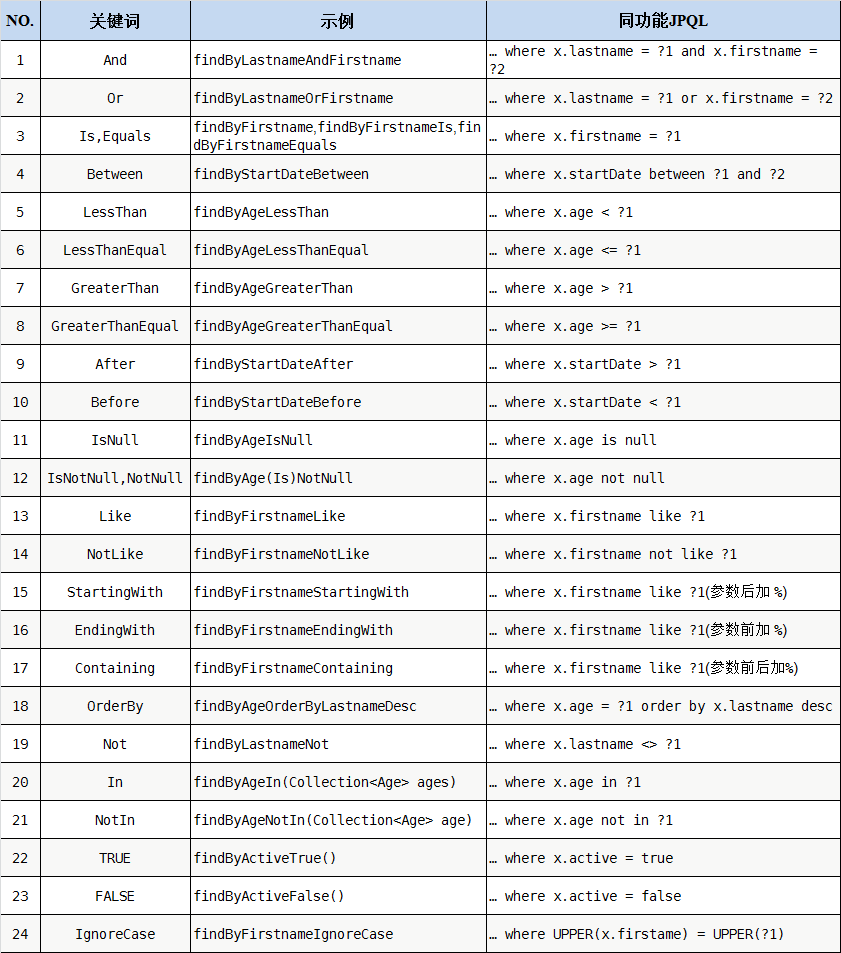
我们可以根据自己的SQL语句,编写对应的方法,但又有一个问题,对于简单的查询还能接受,如果是一些很复杂的查询,那么方法名就会变得很长很长,读起来很辛苦怎么办?SpringData也考虑到这个问题,我们可以通过注解的方式,将自己写的SQL语句传进去,方法名就自由啦。
@RepositoryDefinition(domainClass = Student.class, idClass = Integer.class)
public interface StudentRepository {
//注意,这里from后的不是数据表名,而是对于的实体类名
@Query("select o from Student o where id=(select max(id) from Student t1)")
public Student getStudentByMaxId();
//这里的?是占位符,在执行是会替换成对应位置的参数,比如这里?1会被替换成name的值
@Query("select o from Student o where o.name=?1 and o.age=?2")
public List<Student> queryParams1(String name, Integer age);
//这里的:+参数名则是绑定参数,在参数列中使用@Param注解绑定参数,则可在SQL语句中使用:+参数名得到相应参数的值
@Query("select o from Student o where o.name=:name and o.age=:age")
public List<Student> queryParams2(@Param("name")String name, @Param("age")Integer age);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
使用@Quer注解传入SQL语句,我们就可以实现一些比较复杂的查询。除了查询,我们平时还会有更新、插入、删除的操作,如果你模仿上述方法编写,你是无法执行的。原因是插入、更新、删除是DML,select是DQL。
要实现插入、更新、删除操作,我们只需要再多加一个注解@Modifying,告诉框架,它是一个DML操作即可。
@RepositoryDefinition(domainClass = Student.class, idClass = Integer.class)
public interface StudentRepository {
@Modifying
@Query("update Student o set o.age = :age where o.id = :id")
public void update(@Param("id")Integer id, @Param("age")Integer age);
}- 1
- 2
- 3
- 4
- 5
- 6
又或许你必须要使用原生的SQL语句怎么办?只需要在@Query注解中设置nativeQuery即可
@RepositoryDefinition(domainClass = Student.class, idClass = Integer.class)
public interface StudentRepository {
//注意,这里使用原生的SQL语句,from后的表名应该是数据库表名
@Query(nativeQuery = true, value = "select count(1) from student")
public long getCount();
}- 1
- 2
- 3
- 4
- 5
- 6
看到这里,相信大家对于SpringData已经有了初步的了解,以及熟悉基本的操作了。在介绍SpringData的时候,我们可以看到对于不同的数据库厂商,SpringData提供了不同的Repository接口。
以JDBC为例,我们可以看到有JpaRepository,它是继承了PagingAndSortingRepository接口,PagingAndSortingRepository接口继承了CrudRepository接口,CrudRepository接口又继承了Repository。
所以JpaRepository的功能相比Repository要丰富了许多,除了基本的CRUD操作之外,还支持分页和排序功能。具体功能可以在使用中慢慢熟悉了解,我们也不需要把全部功能都列一遍,毕竟使用起来和Repository都是大同小异的。(之后有时间可能会再更一下JpaRepository的分页和排序功能如何使用)
转自:https://blog.csdn.net/Changui_/article/details/78484935