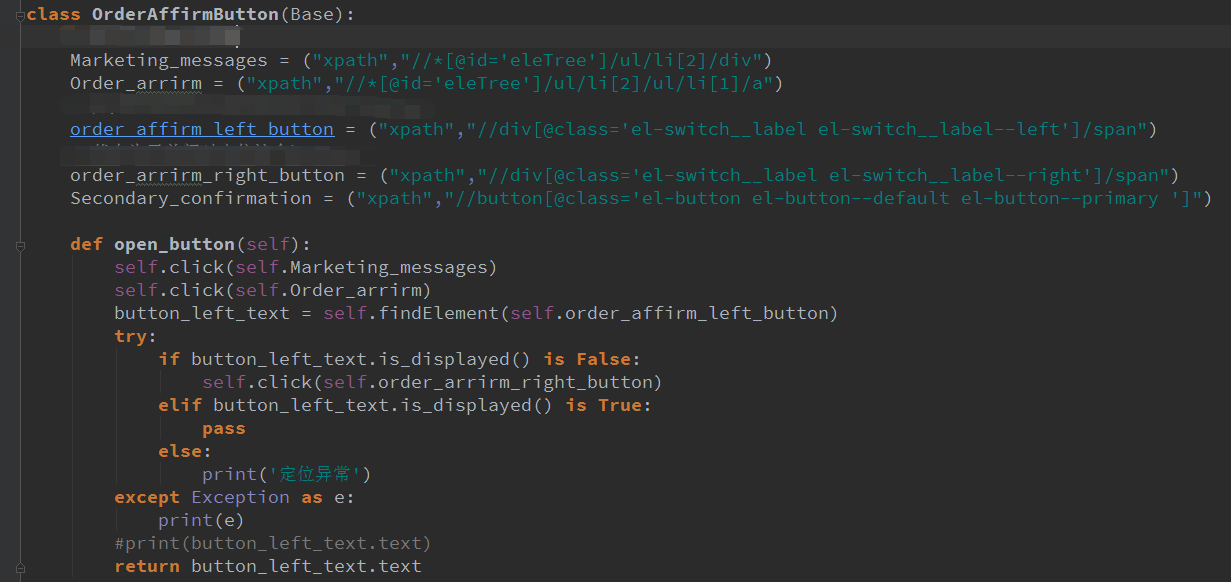
1、二次封装之前,先来复习下selenium的三种等待方式。
1、sleep(强制等待,进程休眠)
1、作用于局部。浪费时间。看情况使用。
2、implicitly_wait(30)(隐式等待)
1、作用于全局。
2、需等待页面完全加载完成,之后才会去查找元素。(游览器左上角转圈结束表示加载完成)
3、如果页面元素加载已完成。但是部分js之类的加载失败(此时页面转圈是一直在转的),会继续加载,直到30s。
4、且有切换页面的时候。需加强制等待,不然会报错。
&一般自动化脚本不会用隐式等待
3、WebDriverWait(显示等待)
WebDriverWait(self, driver, timeout, poll_frequency=POLL_FREQUENCY, ignored_exceptions=None)
1、在a秒内,每间隔b秒内查询一次。查询到了就返回,没查询到就等待下一次查询,超过a秒还未查询到就抛出timeout异常。
2、作用于局部
3、格式如下:
1、element = WebDriverWait(driver,10).until(lambda x: x.find_element_by_id("kw"))
element.send_keys("xxx")
注:对照上面,第一个参数self忽略,第二参数传driver不用说,第三个参数timeout传10,可以自行修改。第四个参数poll_frequency不修改默认0.5,可以自行修改。
第五个ignored_exceptions默认忽略异常。(这里的x传的是driver。lambda学过python基础应该都知道)
4、定位方法优化:
我们常用的定位方法有find_element_by_id、by_name、by、xpath等等。但是这些我们可以统一用By方法来实现:
from selenium.webdriver.common.by import By ---首先导入by方法
比如我们之前id定位就可以改成driver.find_element(By.ID,"值"),然后我们可以去看看By这个方法的源码。
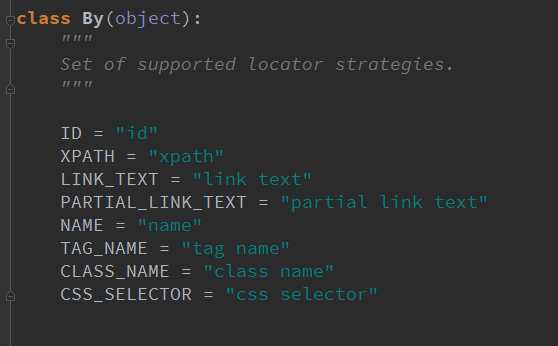
其实我们写的导入By,写了个By.ID实际上等于引入了一个“id”而已。所以我们可以再优化一下,比如我们之前id定位就可以改成driver.find_element(“id”,"值"),其余几种定位也是如此。
5、现在我们就可以来封装一个比如元素定位的方法了。
1、新建一个类。Base,继承object类。
2、定义一个方法。比如findElement。

注:loctor只是一个参数,不具备别的意义,你可以修改命名,self.t就是 poll_frequency。*号代表参数分开传递,学过python基础的应该都知道。
3、同时。self.driver,self.timeout,self.t这种都要用到的参数我们可以放在init初始函数里面,还可以设置个默认值,如下:----(如果你不写在init里面就放在findelement里面传也行。)

4、这样。一个基本的元素定位封装就好了。但是现在问题还是很多的。比如。我们传值不符合要求时,会报错。我们可以来加个判断。
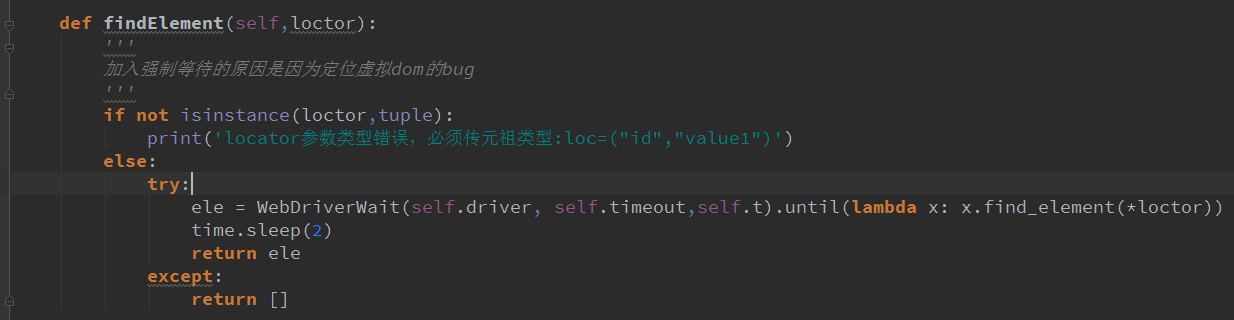
5、最后我们还可以打印一下定位的步骤。如下:

这样。一个较为成熟的元素定位的二次封装的就完成了。且连日志都不需要再去写了。
之后。像click、sendkeys、clear啥的都这个基础上进行就可以了。
demo如下: