在视频通话中,视频前处理模块可以有效提升用户参与实时视频时的体验,并保护用户隐私,主要包括虚拟背景、美颜和视频降噪等。腾讯会议在视频前处理场景下,遇到哪些技术难点,如何进行优化?【腾讯技术开放日 · 云视频会议专场】中,腾讯云高级工程师李峰从算法和工程优化的角度进行了分享。
视频前处理场景探索
视频是连续的,在转播的时候需要经过编码和解码的流程,所以视频处理需要分为前处理和后处理。所谓前处理就是指编码前的视频处理,比如背景虚化。所谓后处理就是指解码后的视频处理,比如视频超分。
有哪些前处理算法可以应用在视频会议的处理场景下呢?理想情况下,多多益善,能够想到的都可以落地,但是考虑到会议场景的计算资源非常有限,而且要不影响其它高优先级的服务,所以需要挖掘用户最迫切的需求,利用有限的计算资源为用户提供更好的视频体验。
数据分析发现会议场景下大家开摄像头的比例不是很高,我们分析主要有三个原因:第一担心泄漏隐私,第二不够自信,第三画质不好。针对这几个点腾讯会议陆续推出了虚拟背景、美颜、视频降噪、暗场景增强等一系列的处理算法。
虚拟背景可以很好的保护用户隐私,创造一个公平的环境,这里贴了一个用户的反馈,这是一个在线课堂老师反馈虚拟背景可以为许多孩子取消歧视,让家庭背景、家庭条件不再成为孩子的负担。美颜的话,相信大家都是非常了解,也是经常用的,它可以鼓励大家参与到视频通话的场景中来。视频降噪可以降低摄像头的噪声,消除灯光造成闪烁的问题,进而提升视频画面的质量。暗场景增强可以提升暗光场景下的视频体验。

虚拟背景的算法探索与实践
所谓虚拟背景是指允许用户在使用腾讯会议期间上传自定义的图片或者视频,作为视频场景下的虚拟背景或者将视频背景模糊掉,满足用户保护隐私和个性化视频的需求。
虚拟背景的框架主要包括数据、模型、损失、训练和前向推理引擎五大模块。

对于深度学习任务,大家都知道数据的数量和质量是效果的关键。由于腾讯会议中的数据非常敏感,涉及非常多的隐私,我们拿不到用户使用时的真实数据,所以腾讯会议采取了自采和精细标注两种方案,目前数据流程是一种闭环式的迭代优化。训练过程中数据也会做一系列的增广,比如说颜色变换、随机噪声、随机模糊等等来增加数据的多样性。
从模型层面,利用编码器得到输入图像的多层特征表示,其中第一层分辨率比较高,编码了人像的边缘细节信息,而高层特征空间分辨率比较低,只能编码人像的抽象语义信息。如果我们将高层特征表示送到解码器里进行融合学习,解码过程中分辨率又会逐级回升。腾讯会议还会在解码之后接一个轻量级的调优模块,这样就可以在高分辨率上恢复更多的细节。
网络输出后还要经过一系列的膨胀、腐蚀、边缘、羽化等等多项后处理算法的优化。损失函数也是训练流程的关键,它决定了这个网络能够聚焦在哪一些目标上进行学习,腾讯会议目前采用了多损失约束的方式来指导网络的学习。
交叉熵损失是对每个象素点进行约束,分割任务中的一项基础损失。
为了增加时域的平滑性,要约束网络对输入经过轻微干扰和原输入的距离,这样可以在一定程度上模拟实际运行中前后帧之间的稳定性和连续性。
边缘准确性对于人像分割的直观体验影响非常大,所以腾讯会议还利用了一个单独的分支和边缘损失来提升网络边缘处理的准确性。
虚拟背景是跑在各个端上,而不是服务器上,这就对神经网络的高效、轻量提出非常高要求,这也使得网络的深度和宽度非常受限,学习能力相比服务器端的模型有较大程度的下降。为了弥补网络带来的准确率的下降,腾讯会议采用了多种蒸馏方式,约束线上的小模型与服务器之间大模型的距离,使得小模型与服务器模型之间的输出分布尽量靠近。这种多蒸馏损失可以提升蒸馏的有效性,从而提升线上小模型的准确率与融贯性。实际训练的过程中,腾讯会议还采用了分布式等可以快速提升训练速度的多种优化的方式,并且支持在线和离线两种蒸馏方式。
最后是前向推理引擎,它可以对算法模型进行针对性的异构和并行计算优化,从而达到性能和效果之间良好的平衡,是算法最终能够落地的一个关键技术。
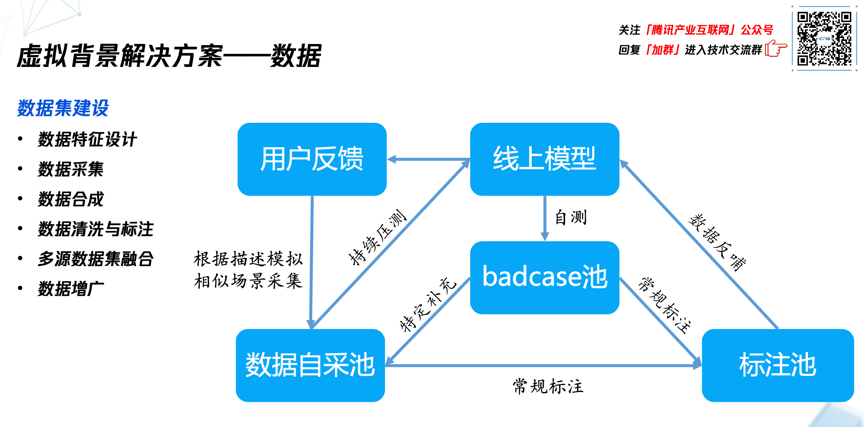
- 数据
数据流程闭环是怎么形成的?具体来讲,首先是建立一个自采池,存放自采的数据。需要注意的是,由于用户数据的敏感性,腾讯会议拿不到任何线上实际的数据,所以只能模拟线上会议的场景来进行采集,比如大家一起进行自采,如果说这时候有用户反馈的话,会根据用户反馈的文字或者图片、或者视频的描述,来增加模拟布置类似的场景进行采集补充。
对于池子里面的数据会不断进行标注,并且把标注的数据提交到标注池,然后将标注后的数据提供给线上模型进行迭代训练。对于线上模型,会将自采的数据抽样进行自测和压测,将分割不达标的图片添加到自采池和badcase池。并且我们会对badcase池里的所有badcase通过分析特点进行存量分布归类,对归类的数据再进行特定的补充采集。
这就是整个数据流程的闭环式迭代优化,它有效推动了线上模型质量的持续提升。
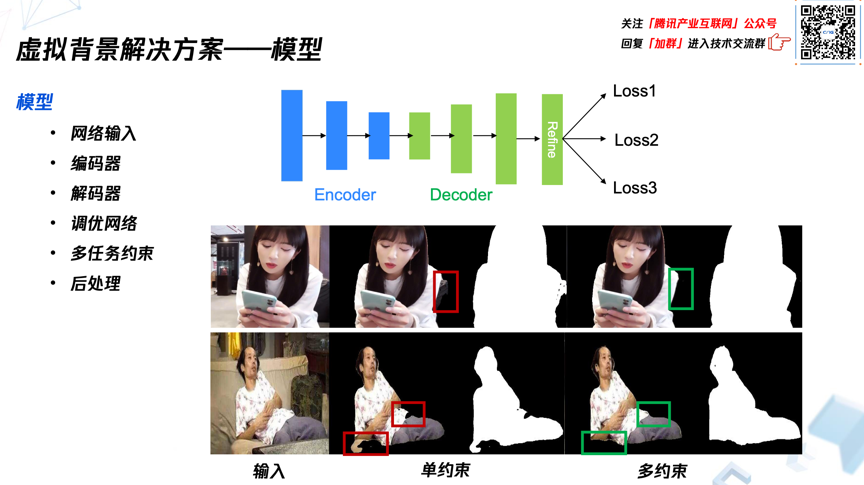
- 模型
腾讯会议目前采用了经典的编码、解码、refine的结构。编码器会不断地降低分辨率并逐级抽象,而解码模块则是对多级特征进行融合学习,实现分辨率回升。同时腾讯会议还采用了多任务约束,下面的图中可以看到实验结果,经过多损失约束限制,输出的图会更加准确,边缘的一致性也得到了提升。
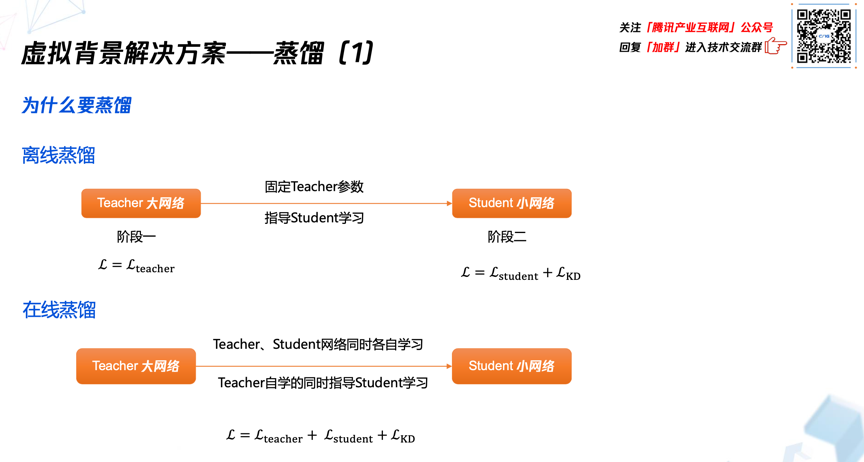
- 损失
前面提到为了弥补网络带来的准确率的下降,腾讯会议采用了多种蒸馏方式约束线上的小模型与服务器之间大模型的距离。
为什么要做蒸馏?蒸馏作为一种只增加训练耗时而不增加线上测试耗时的方法,在损失约束中被大量采用,对于线上超轻量的小模型来说,蒸馏可以比较好的缩小服务器、教师网络和学生网络之间的差距。并且在实际操作过程中发现经过蒸馏后的学生网络能够比蒸馏前的网络具有更好的稳定性。
目前腾讯会议支持离线蒸馏和在线蒸馏两种方式。其中离线蒸馏是单独训练老师网络,然后固定老师网络的参数,通过老师网络指导学生网络进行学习。在线蒸馏是教师网络带着学生网络一起学习,这样对网络而言既包括了教师网络的自我学习,还有同步指导学生模型的蒸馏学习,也包括学生网络的自我学习。
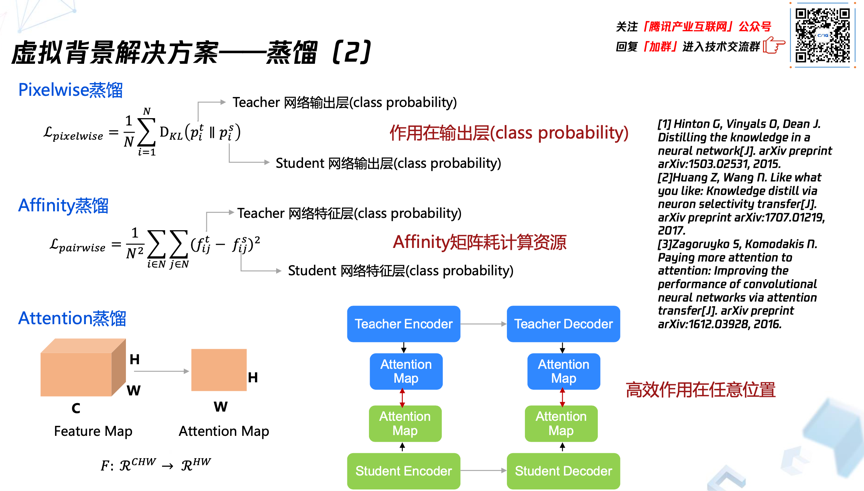
常用的蒸馏损失包括下面图中列出来的三种。Pixelwise蒸馏是象素级的,Affinity蒸馏是临近关系的方式,Attention蒸馏是注意力的方式。
象素级的蒸馏主要作用在输出层,也就是说利用教师网络的输出作为软标签约束学生网络的输出。
基于Affinity矩阵的蒸馏的时候,教师网络和学生网络分别计算各自的Affinity矩阵,这种能够建模象素间的关系,然后该领域的信息知识从教师网络就迁移到了学生网络里面。虽然信息迁移能有效补充单象素点独立建模信息不足的问题,但是计算量相对比较大。
腾讯会议目前采用的是第三种,注意力蒸馏的方式,它是一种高效的约束中间特征层的蒸馏方法。从图中可以看出,经过建模空间注意力特征图从三维直接降到了二维,之后再进行约束,这样可以大幅降低计算量,提升蒸馏的效率。
- 前向推理引擎
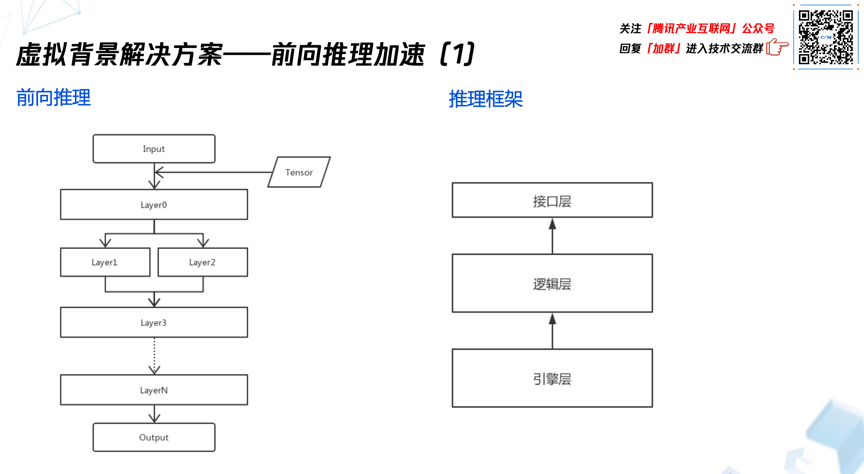
深度学习算法落地的过程中,前向推理加速是非常重要的一环。前向推理简单来说,如图所示,以输入数据为出发点,经过一层层的神经网络得到最终的输出数据。层之间的数据通常是用tensor表示,每个tensor就表示了一个多维矩阵。
腾讯会议自研推理引擎主要有三个方面的优势:
第一, 音频是腾讯会议的核心能力之一,自研推理引擎在音频算法性能优化方向积累丰富,并已经上线了量化和量化训练的支持;
第二, 桌面端是腾讯会议的核心场景之一,自研推理引擎在桌面端的异构计算和并行计算优化方向积累丰富,有力的支撑了桌面端的音视频算法。
第三, 自研推理引擎可以快速定制化和响应业务的需求,特别是对于腾讯会议这种快速迭代的产品来说,快速定制化和迭代的能力非常重要。
目前腾讯会议前向推理框架主要分为三层:引擎层、逻辑层、接口层,从下到上。其中引擎层主要负责对各种神经网络算子进行计算优化,而逻辑层封装了与各个业务相关的逻辑,接口层是提供了跨平台的业务接口。
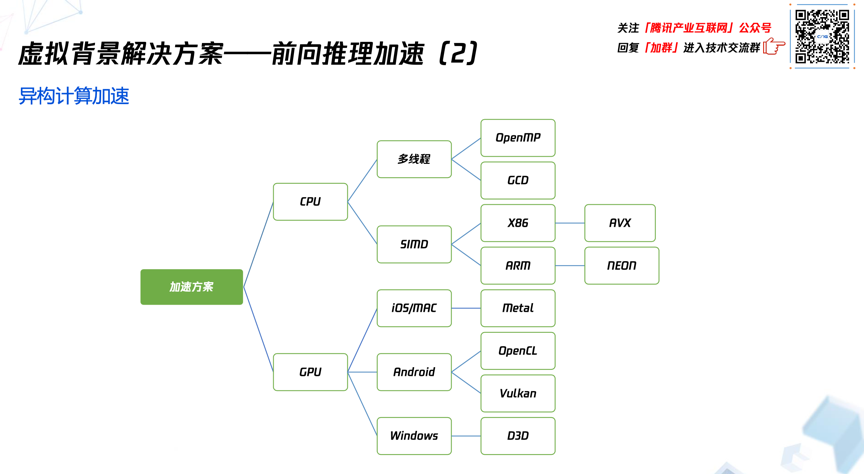
下面列了一些目前腾讯会议前向推理引擎支持的加速方案,由于不同的硬件或者处理器、设计理念不同,应用场景也不同,因此不同的方法在不同的处理器上会有不同的性能瓶颈,所以需要具体问题具体分析。举个例子,通常来说CPU适合处理逻辑比较复杂的计算,而GPU适合处理数据并行的计算密集型运算。而且还需要考虑在不同处理器之间的数据交互可能给性能带来的影响,这个消耗有时候会成为整体算法性能的一个瓶颈。以虚拟背景为例,视频人像分割深度学习模型适合运行在GPU上,而后处理的一些算法就更适合运行在CPU上。
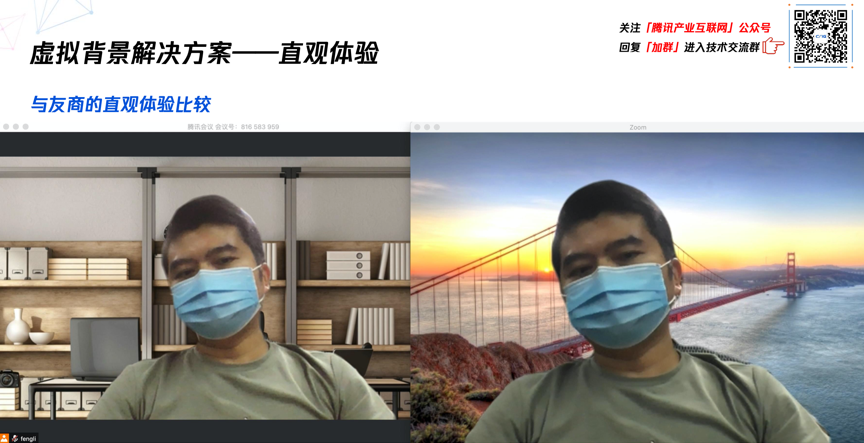
看一下跟友商的虚拟背景效果的直观体验对比视频,在某些场景下腾讯会议的体验要稍好一些,比如抬手的场景,腾讯会议要分割的更准确,左边是腾讯会议。
美颜功能的算法探索与实践
大家经常用美颜。它可以提升用户的视频体验,鼓励用户参与到语视频通话的场景中来。从技术的角度来说,美颜通常包括磨皮、美形和美妆三个部分。
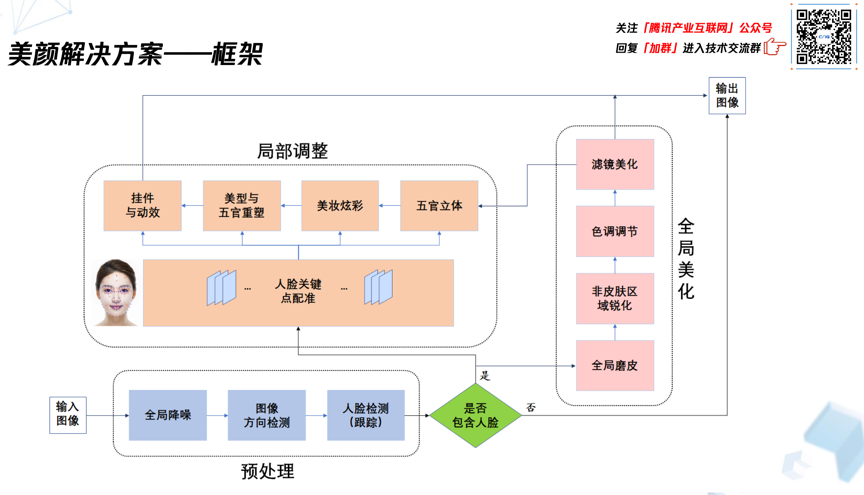
看一下美颜整体解决方案的框架,它包括三个部分:预处理模块、全局美化模块、局部调整模块。输入图像首先进入预处理模块,通过全局降噪图像处理提升图像质量,在实际应用中如果检测到人脸就可以进行全局美化或者局部美化,否则就直接输出降噪后的图像。全局美化模块实现图片整体美化效果,比如全局磨皮、非皮肤区域的润化色调调节,经过全局美化后的图片是可以具备比较好的整体视觉,是可以直接输出的。当然,也可以进一步进行局部调整,在这里是基于人脸关键点配准设计的一套算法,主要是实现五官立体、化妆等局部内容调整,最后是将调整后的图片输出。
在不断优化美颜解决方案的实践过程中,我们会遇到一些困难,比如:
如何在性能和效果之间取得平衡?
目前腾讯会议上线的是全局美化,还是因为性能问题要做出取舍。我们会有更多的针对不同机型采用不同的美颜策略,比如中低端的机型采用磨皮美白,高端机型可以放开美形、美妆这样的能力。
强噪声的摄像头数据下如何保证美颜体验?
在进行美颜磨皮的时候需要考虑三个因素,一个是光滑皮肤的区域,二是保留人脸五官的细节,三是抑制噪声。目前腾讯会议是在图像预处理的时候会采用降噪的方式先对整体的图像进行整体预处理。要注意的是,要避免使用锐化的细节强化的处理,那样有可能导致噪声更加凸显。
为什么人脸检测和人脸配准要分开设计?
一方面是基于性能的考虑,没有人脸的时候考虑降噪和增强的基本操作,有人脸的时候才需要进行美化处理。另外一方面是模型的稳定性,直接对图像进行人脸配准往往包含大量背景冗余信息,会造成关键点配准难度加大而且不稳定,如果经过人脸检测之后,只对人脸区域进行人脸配准的话,通常结果是比较稳定的。
美颜策略如何适配巨大的分辨率跨度?在视频会议里面分辨率跨度大,比如网络的因素就会使得图像分辨率会在一定的范围之间波动。这里腾讯会议主要分了三种场景:第一种就是在分辨率很低的时候,会直接放弃磨皮,因为这时候整个画面比较糊,再使用磨皮往往导致整个画面更糊。第二是在中段的分辨率里面,那么采用一种叫做上采样然后进行美化之后再进行下采样的方式,这样会有优化效果,但是会增加一定的计算开销。第三是高分辨率,那就可以直接使用前面讲的那些美颜算法。
应用场景中如何精简美颜处理复杂度?
如果前面背景虚化已经把人像分割出来了,那么这时候其实不需要浪费计算资源对背景进行磨皮的操作,类似这种都是可以降低美颜处理复杂度的方式。