https://www.cnblogs.com/Yuanjing-Liu/p/9391964.html
正文
1、数据挖掘工具对比
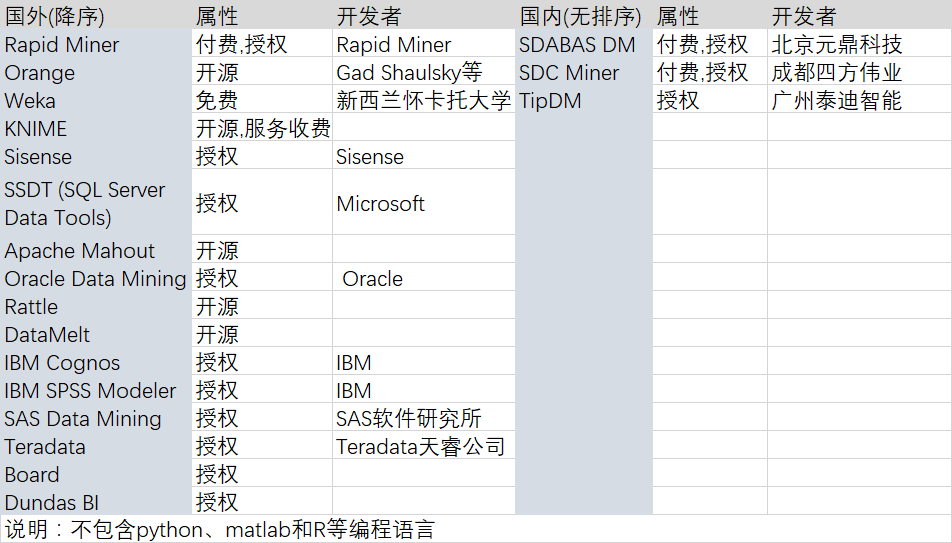
数据来源:Top 15 Best Free Data Mining Tools: The Most Comprehensive List — Software Testing Help
2、Rapid Miner
3、Orange
4、Weka
4.1 介绍
Weka的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),同时weka也是新西兰的一种鸟名,而Weka的主要开发者来自新西兰。Weka作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。如果想自己实现数据挖掘算法的话,可以参考Weka的接口文档。在Weka中可以方便地集成自己的算法或者借鉴它的方法自己实现可视化工具。
4.2 使用准备
- Weka安装后有GUI和命令行两种打开方式。
- Weka支持的数据集有arff、csv、xrff格式,可以在安装目录的 data 文件夹下找到示例。
- Weka安装目录下有使用文档和类说明文档以及源码,若要调用Weka算法只需要在程序中引入Weka.jar包就可以了。
- Weka安装后不支持中文数据。
4.3 主要功能与使用
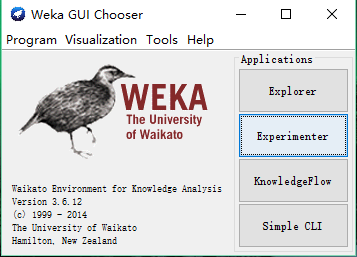
(1)打开GUI,点击Explorer按钮,此时会出现Explorer界面:
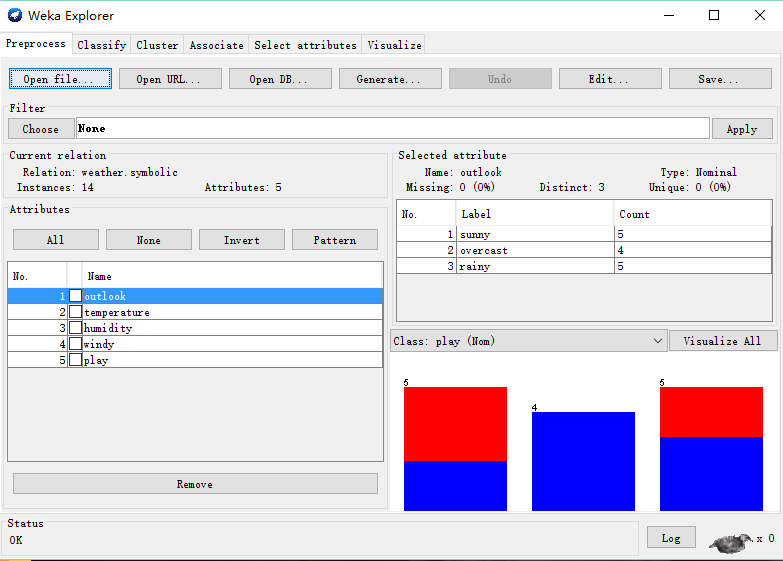
(2)点击Open,选择data文件下的任意一个数据集,例如 weather.nominal.arff 数据集,这里面记录的是一些天气数据:
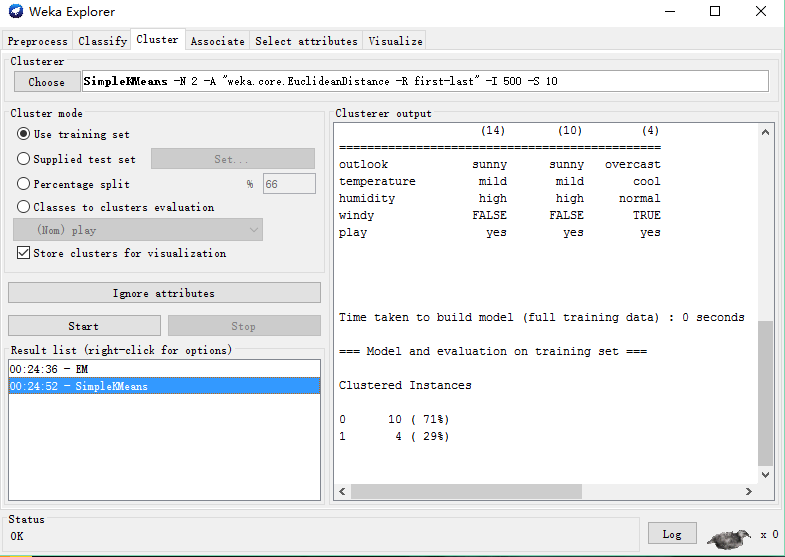
(3)此时可以在栏目上选择不同的算法(数据集不支持的算法会变暗)。选中可以使用的算法,再点击Start,就可以在右侧的output中看到计算结果:
(4)当然你也可以自定义数据集,用Weka进行分析测试,十分方便。
(5)这只是Weka的基本功能,要想使用其它功能还需要深入了解
4.4 优缺点
优点
- weka是开源软件,代码是公开的,Java编写,可以寻找合适方案进行二次开发
- 当维度为适当维度,如百维及以内,训练样本在万级以内的时候,其挖掘的应用和效果都是可圈可点的。
缺点
- weka是小而美的数据挖掘工具,当维度特别高时,如达到千维及以上,训练样本数达到万级以上时候,其可用性是极差的。
- 算法库有限,仅有完善的聚类,分类和相关性分析,当然了ETL还是比较完善
4.5 开发资源
5、KNIME
5.1 介绍
KNIME (Konstanz Information Miner) 是一个用户友好,智能的,并有丰演的开源的数据集成,数据处理,数据分析和数据勘探平台。它给了用户有能力以可视化的方式创建数据流或数据通道,可选择性地运行一些或全部的分析步骤,并以后面研究结果,模型 以及 可交互的视图。 KNIME 由Java写成,其基于 Eclipse 并通过插件的方式来提供更多的功能。通过以插件的文件,用户可以为文件,图片,和时间序列加入处理模块,并可以集成到其它各种各样的开源项目中,比如:R 语言,Weka, Chemistry Development Kit, 和 LibSVM。
- KNIME发音为:[naim](就是用“k”,就像“knife”一样)。
- 它由康斯坦茨大学的Michael Berthold小组开发。
- KNIME系统是基于Eclipse开发环境来精心开发的数据挖掘工具。无需安装,方便使用。KNIME也是用Java开发的,可以扩展使用Weka中的挖掘算法。
- KNIME采用的是类似数据流(data flow)的方式来建立分析挖掘流程。挖掘流程由一系列功能节点(node)组成,每个节点有输入/输出端口(port),用于接收数据或模型、导出结果。KNIME中每个节点都带有交通信号灯,用于指示该节点的状态(未连接、未配置、缺乏输入数据时为红灯;准备执行为黄灯;执行完毕后为绿灯)。
- 在KNIME中有个特色功能——HiLite,允许用户在节点结果中标记感兴趣的记录,并进一步展开后续探索。
5.2 主要功能与使用
(1)采用完全图型化的操作方式,以下为KNIME的主要操作界面:

(2)支持各类方式的数据载入,包括文件、数据库等
(3)支持各类数据处理方式,包括按列(如分拆、合并等)、按行(过滤、变形)、矩阵(转置)和PMML(字段投影、一对多、多对一、正态化、反正态化等)
(4)支持各类数据视图,如点图、直方图、饼图、分布图
(5)支持假设检验和回归方法
(6)支持决策树、贝叶斯、聚类、规则推导、神经网络等挖掘方法
(7)支持流程控制
5.3 优缺点
优点
- 提供完全图型化的操作方式,操作流程简便、结果产出直观;
- 提供丰富的数据读取和加工操作,支持从数据库中获取数据;
- 提供较为完备的数据挖掘方法;
缺点
- 正由于其主要是基于图型的操作,故难于与其它系统进行集成;
- 对于统计模型的支持略显不足。
5.4 开发资源
6 Apache Mahout
6.1 简介
Apache Mahout 是 Apache Software Foundation (ASF) 开发的一个全新的开源项目,其主要目标是创建一些可伸缩的机器学习算法,供开发人员在 Apache 在许可下免费使用。该项目已经发展到了它的最二个年头,目前只有一个公共发行版。Mahout 包含许多实现,包括集群、分类、CP 和进化程序。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。
Mahout 项目是由 Apache Lucene(开源搜索)社区中对机器学习感兴趣的一些成员发起的,他们希望建立一个可靠、文档翔实、可伸缩的项目,在其中实现一些常见的用于集群和分类的机器学习算法。该社区最初基于 Ng et al. 的文章 “Map-Reduce for Machine Learning on Multicore”,但此后在发展中又并入了更多广泛的机器学习方法。Mahout 的目标还包括:
- 建立一个用户和贡献者社区,使代码不必依赖于特定贡献者的参与或任何特定公司和大学的资金。
- 专注于实际用例,这与高新技术研究及未经验证的技巧相反。
- 提供高质量文章和示例。
6.2 主要特性
Apache Mahout 运行环境包括
- 针对分布式的优化
- 支持Scala API
- 支持线性代数操作
- 支持Scalak扩展
- 支持IScala REPL的交互式shell
- 集成MLLib库
- 可以运行在 Spark、H2O和Flink上
- 支持稀疏矩阵和向量的加速计算
- 和Apache Zeppelin整合转换矩阵tsv
Apache Mahout Samsara 算法包括
- 随机矩阵的奇异值分解算法ssvd、dssvd
- 随机主成分分析算法(spca、dspca)
- 分布式Cholesky QR(thinQR)
- 分布式正则化交替最小二乘法(dals)
- 协同过滤算法::Item和Row的相似性
- 朴素贝叶斯分类算法
- 核心分布算法
6.3 Mahout安装、配置
(1)下载并解压Mahout
http://archive.apache.org/dist/mahout/ tar -zxvf mahout-distribution-0.9.tar.gz
(2)配置环境变量
# set mahout environment export MAHOUT_HOME=/mnt/jediael/mahout/mahout-distribution-0.9 export MAHOUT_CONF_DIR=$MAHOUT_HOME/conf export PATH=$MAHOUT_HOME/conf:$MAHOUT_HOME/bin:$PATH
(3)安装mahout
[jediael@master mahout-distribution-0.9]$ pwd /mnt/jediael/mahout/mahout-distribution-0.9 [jediael@master mahout-distribution-0.9]$ mvn install
(4)验证Mahout是否安装成功
执行命令mahout。若列出一些算法,则成功:
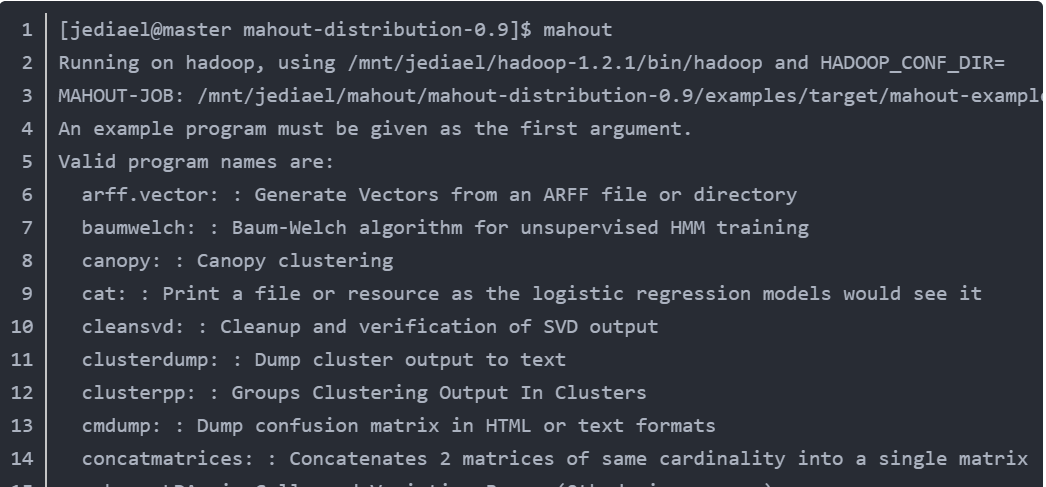
6.4 使用简单示例验证mahout
(1)启动Hadoop
(2)下载测试数据
http://archive.ics.uci.edu/ml/databases/synthetic_control/链接中的synthetic_control.data
或者百度一下也很容易找到这个示例数据。
(3)上传测试数据
hadoop fs -put synthetic_control.data testdata
(4)使用Mahout中的kmeans聚类算法,执行命令:
mahout -core org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
花费9分钟左右完成聚类 。
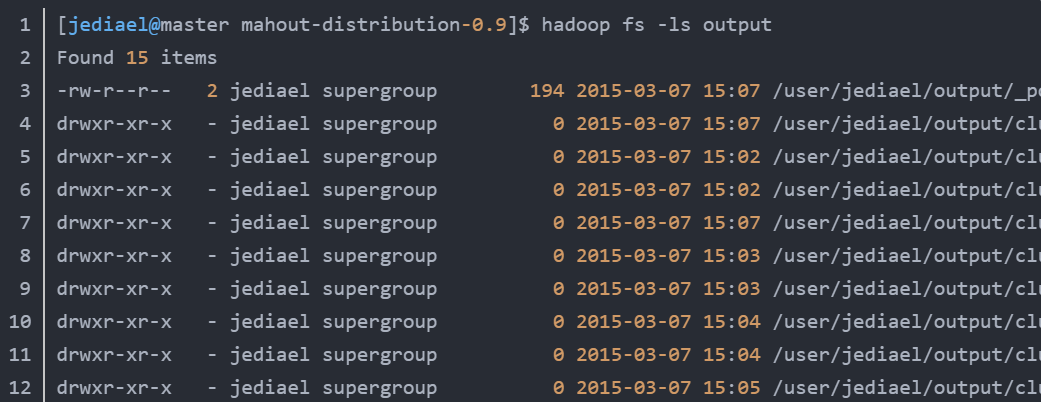
(5)查看聚类结果
执行hadoop fs -ls /user/root/output,查看聚类结果。
6.5 优缺点
优点
- 作为开源项目,源码开放,Java编写,可以集成到大多数大数据平台和语言中
- 最大的优点就是基于hadoop实现,把很多以前运行于单机上的算法,转化为了MapReduce模式,这样大大提升了算法可处理的数据量和处理性能。
缺点
- 无图形化GUI,只是一个算法库,使用接口开发
文献
Top 15 Best Free Data Mining Tools: The Most Comprehensive List — Software Testing Help
Weka:一个开源的机器学习和数据挖掘软件 - 资源 - 伯乐在线
数据挖掘RapidMiner工具使用----产品介绍与安装过程 - CSDN博客
大数据-机器学习-Apache Mahout-初级 - 简书
Apache Mahout:经典机器学习算法库 - 资源 - 伯乐在线
Mahout学习之Mahout简介、安装、配置、入门程序测试 | IT瘾