一、XGBoost参数
xgboost参数可以分为三种类型:通用参数、booster参数以及学习目标参数
- General parameters:参数控制在提升(boosting)过程中使用哪种booster,常用的booster有树模型(tree)和线性模型(linear model)。
- Booster parameters:这取决于使用哪种booster。
- Learning Task parameters:控制学习的场景,例如在回归问题中会使用不同的参数控制排序。
- 命令行参数:与XGBoost的CLI版本的行为有关
官网文档地址:https://xgboost.readthedocs.io/en/latest/parameter.html
下面详细介绍每种类型的参数
二、General Parameters通用参数
(1)booster [default=gbtree] :
可以gbtree,gblinear或者dart; gbtree并dart使用基于树的模型,同时gblinear使用线性函数
(2)silent [default=0] :
取0时表示打印出运行时信息,取1时表示以缄默方式运行,不打印运行时的信息。缺省值为0
建议取0,过程中的输出数据有助于理解模型以及调参。另外实际上我设置其为1也通常无法缄默运行。。
(3)nthread [如果未设置,默认为最大可用线程数] :
XGBoost运行时的线程数。缺省值是当前系统可以获得的最大线程数
如果你希望以最大速度运行,建议不设置这个参数,模型将自动获得最大线程,使用线程数,一般我们设置成-1,使用所有线程。如果有需要,我们设置成多少就是用多少线程
(4)num_pbuffer [由XGBoost自动设置,无需由用户设置]:
预测缓冲区的大小,通常设置为训练实例数。缓冲区用于保存最后提升步骤的预测结果
(5)num_feature [由XGBoost自动设置,无需由用户设置] :
boosting过程中用到的特征维数,设置为特征个数。XGBoost会自动设置,不需要手工设置
三、Booster Parameters
Parameter for Tree Booster
(1)eta[默认= 0.3,别名:learning_rate]
-
在更新中使用步长收缩以防止过度拟合。在每个增强步骤之后,我们都可以直接获得新特征的权重,并
eta缩小特征权重以使增强过程更加保守。 -
范围:[0,1],通常最后设置eta为0.01~0.2
(2)gamma[默认= 0,别名:min_split_loss]
-
在树的叶子节点上进行进一步分区所需的最小损失减少。越大
gamma,算法将越保守。 - 模型在默认情况下,对于一个节点的划分只有在其loss function 得到结果大于0的情况下才进行,而gamma 给定了所需的最低loss function的值,在模型中应该进行调参。
-
范围:[0,∞]
(3)max_depth [default=6]
- 树的最大深度。
缺省值为6 - 取值范围为:[1,∞]
- 指树的最大深度
- 树的深度越大,则对数据的拟合程度越高(过拟合程度也越高)。即该参数也是控制过拟合
- 建议通过交叉验证(xgb.cv ) 进行调参
- 通常取值:3-10
(4)min_child_weight [默认值= 1]
- 子节点中最小的样本权重和。如果一个叶子节点的样本权重和小于min_child_weight则拆分过程结束。在线性回归模型中,这个参数是指建立每个模型所需要的最小样本数。该成熟越大算法越conservative。即调大这个参数能够控制过拟合。
- 取值范围为: [0,∞]
(5)max_delta_step [默认= 0]
-
我们允许每个叶子输出的最大增量步长。如果将该值设置为0,则表示没有约束。如果将其设置为正值,则可以帮助使更新步骤更加保守。通常不需要设置这个值,但在使用logistics 回归时,若类别极度不平衡,则调整该参数[1,10]可能有效果
-
范围:[0,∞]
(6)subsample [默认值= 1]
- 用于训练模型的子样本占整个样本集合的比例。如果设置为0.5则意味着XGBoost将随机的从整个样本集合中抽取出50%的子样本建立树模型,这能够防止过拟合。
- 取值范围为:(0,1]
(7)sampling_method[默认= uniform]
-
用于对训练实例进行采样的方法。
-
uniform:每个训练实例被选择的可能性相同。通常将subsample> = 0.5 设置 为良好的效果。 -
gradient_based:每个训练实例的选择概率与规则化的梯度绝对值成正比 (更具体地说,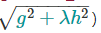 )。
)。 subsample可以设置为低至0.1,而不会损失模型精度。请注意,只有tree_method将设置为时,才支持此采样方法gpu_hist。其他树方法仅支持uniform采样
(8)colsample_bytree,colsample_bylevel,colsample_bynode[默认= 1]
-
这是用于抽取列(特征)的一组参数。
-
所有
colsample_by*参数的范围为(0,1],默认值为1,并指定要进行二次采样的列的分数。 -
colsample_bytree:在建立树时对特征随机采样的比例。 -
colsample_bylevel决定每次节点划分时子样例的比例,通常不使用,因为subsample和colsample_bytree已经可以起到相同的作用了 -
colsample_bynode是每个节点(拆分)的列的子样本比率。每次评估新的分割时,都会进行一次二次采样。列是从为当前级别选择的一组列中进行子采样的。 -
colsample_by*参数累积工作。例如,具有64个功能的组合将在每个拆分中保留8个功能供您选择。{'colsample_bytree':0.5, 'colsample_bylevel':0.5, 'colsample_bynode':0.5}在Python界面上,可以设置
feature_weightsfor DMatrix来定义使用列采样时每个功能被选中的概率。fitsklearn界面中的方法有一个类似的参数
(9)lambda[默认= 1,别名:reg_lambda]
- L2正则化权重项(线性回归)。增加此值将使模型更加保守。
(10)alpha[默认= 0,别名:reg_alpha]
-
L1正则化权重项(逻辑回归)。增加此值将使模型更加保守。
(11)tree_method字符串[default = auto] 也就是算法原理提到的贪心算法之类的
-
XGBoost中使用的树构建算法。请参阅参考文件中的描述。
-
XGBoost支持
approx,hist并gpu_hist用于分布式培训。外部存储器实验支持可用于approx和gpu_hist。 -
选择:
auto,exact,approx,hist,gpu_hist,这是常用的更新程序的组合。对于其他更新程序,例如refresh,updater直接设置参数。 -
auto:使用启发式选择最快的方法。-
对于小型数据集,
exact将使用精确贪婪()。 -
对于较大的数据集,
approx将选择近似算法()。它建议尝试hist,并gpu_hist用大量的数据可能更高的性能。(gpu_hist)支持。external memory -
由于旧行为总是在单个计算机上使用完全贪婪,因此,当选择近似算法来通知该选择时,用户将收到一条消息。
-
-
exact:精确的贪婪算法。枚举所有拆分的候选人。 -
approx:使用分位数草图和梯度直方图的近似贪婪算法。 -
hist:更快的直方图优化的近似贪婪算法。 -
gpu_hist:GPUhist算法的实现。
(12)sketch_eps [默认值= 0.03]
-
仅用于
tree_method=approx。 -
这大致转化为箱数。与直接选择垃圾箱数量相比,这具有草图准确性的理论保证。
O(1 / sketch_eps) -
通常,用户不必对此进行调整。但是,请考虑设置较低的数字,以更精确地枚举拆分后的候选人。
-
范围:(0,1)
(13)scale_pos_weight [默认值= 1]
-
控制正负权重的平衡,这对于不平衡的类别很有用。需要考虑的典型值:。有关更多讨论,请参见参数调整。另外,请参见Higgs Kaggle竞赛演示,例如:R,py1,py2,py3。
sum(negative instances) / sum(positive instances)
(14)updater[默认= grow_colmaker,prune]
-
逗号分隔的字符串,定义要运行的树更新程序的序列,提供了构建和修改树的模块化方法。这是一个高级参数,通常会根据其他一些参数自动设置。但是,它也可以由用户显式设置。存在以下更新程序:
-
grow_colmaker:基于树的非分布式列结构。 -
grow_histmaker:基于直方图计数的全局建议,基于行的数据拆分的分布式树结构。 -
grow_local_histmaker:基于本地直方图计数。 -
grow_quantile_histmaker:使用量化直方图生长树。 -
grow_gpu_hist:使用GPU种植树。 -
sync:同步所有分布式节点中的树。 -
refresh:根据当前数据刷新树的统计信息和/或叶子值。注意,不对数据行进行随机子采样。 -
prune:修剪损失<min_split_loss(或伽玛)的分割。
-
-
在分布式设置中,
grow_histmaker,prune默认情况下会将隐式更新程序序列值调整为,您可以将其设置tree_method为hist使用grow_histmaker
学习任务参数
指定学习任务和相应的学习目标。目标选项如下:
-
objective[默认= reg:squarederror]-
reg:squarederror:损失平方回归。 -
reg:squaredlogerror:对数损失平方回归 12[log(pred+1)−log(label+1)]212[log(pred+1)−log(label+1)]2。所有输入标签都必须大于-1。另外,请参阅指标rmsle以了解此目标可能存在的问题。 -
reg:logistic:逻辑回归 -
reg:pseudohubererror:使用伪Huber损失进行回归,这是绝对损失的两倍可微选择。 -
binary:logistic:二元分类的逻辑回归,输出概率 -
binary:logitraw:用于二进制分类的逻辑回归,逻辑转换之前的输出得分 -
binary:hinge:二进制分类的铰链损失。这使预测为0或1,而不是产生概率。 -
count:poisson–计数数据的泊松回归,泊松分布的输出平均值-
max_delta_step在泊松回归中默认设置为0.7(用于维护优化)
-
-
survival:cox:针对正确的生存时间数据进行Cox回归(负值被视为正确的生存时间)。请注意,预测是按危险比等级返回的(即,比例危险函数中的HR = exp(marginal_prediction))。h(t) = h0(t) * HR -
survival:aft:用于检查生存时间数据的加速故障时间模型。有关详细信息,请参见具有加速故障时间的生存分析。 -
aft_loss_distribution:survival:aft目标和aft-nloglik度量使用的概率密度函数。 -
multi:softmax:设置XGBoost以使用softmax目标进行多类分类,还需要设置num_class(类数) -
multi:softprob:与softmax相同,但是输出的向量,可以进一步调整为矩阵。结果包含属于每个类别的每个数据点的预测概率。ndata * nclassndata * nclass -
rank:pairwise:使用LambdaMART进行成对排名,从而使成对损失最小化 -
rank:ndcg:使用LambdaMART进行列表式排名,使标准化折让累积收益(NDCG)最大化 -
rank:map:使用LambdaMART进行列表平均排名,使平均平均精度(MAP)最大化 -
reg:gamma:使用对数链接进行伽马回归。输出是伽马分布的平均值。例如,它对于建模保险索赔的严重性或对于可能是伽马分布的任何结果可能是有用的。 -
reg:tweedie:使用对数链接进行Tweedie回归。它可能有用,例如,用于建模保险的总损失,或用于可能是Tweedie分布的任何结果。
-
-
base_score[默认值= 0.5]-
所有实例的初始预测得分,全局偏差
-
对于足够的迭代次数,更改此值不会有太大影响。
-
-
eval_metric[根据目标默认]-
验证数据的评估指标,将根据目标分配默认指标(回归均方根,分类误差,排名的平均平均精度)
-
用户可以添加多个评估指标。Python用户:记住将指标作为参数对的列表而不是映射进行传递,以使后者
eval_metric不会覆盖前一个 -
下面列出了这些选择:
-
rmse:均方根误差 -
rmsle:均方根对数误差: 1N[log(pred+1)−log(label+1)]2−−−−−−−−−−−−−−−−−−−−−−−−−−−√1N[log(pred+1)−log(label+1)]2。reg:squaredlogerror目标的默认指标。此指标可减少数据集中异常值所产生的错误。但是由于log采用功能,rmsle可能nan在预测值小于-1时输出。有关reg:squaredlogerror其他要求,请参见。 -
mae:平均绝对误差 -
mphe:平均伪Huber错误。reg:pseudohubererror目标的默认指标。 -
logloss:负对数似然 -
error:二进制分类错误率。计算公式为。对于预测,评估会将预测值大于0.5的实例视为肯定实例,而将其他实例视为否定实例。#(wrong cases)/#(all cases) -
error@t:可以通过提供't'的数值来指定不同于0.5的二进制分类阈值。 -
merror:多类分类错误率。计算公式为。#(wrong cases)/#(all cases) -
mlogloss:多类logloss。 -
auc:曲线下面积 -
aucpr:PR曲线下的面积 -
ndcg:归一化累计折扣 -
map:平均平均精度 -
ndcg@n,map@n:'n'可以指定为整数,以切断列表中的最高位置以进行评估。 -
ndcg-,map-,ndcg@n-,map@n-:在XGBoost,NDCG和MAP将评估清单的比分没有任何阳性样品为1加入-在评价指标XGBoost将评估这些得分为0,是在一定条件下一致“”。 -
poisson-nloglik:泊松回归的负对数似然 -
gamma-nloglik:伽马回归的对数似然比为负 -
cox-nloglik:Cox比例风险回归的负对数似然率 -
gamma-deviance:伽马回归的剩余偏差 -
tweedie-nloglik:Tweedie回归的负对数似然(在tweedie_variance_power参数的指定值处) -
aft-nloglik:加速故障时间模型的负对数可能性。有关详细信息,请参见具有加速故障时间的生存分析。 -
interval-regression-accuracy:其预测标签位于间隔检查的标签中的数据点的分数。仅适用于间隔检查的数据。有关详细信息,请参见具有加速故障时间的生存分析。
-
-
-
seed[默认= 0]-
随机数种子。在R程序包中将忽略此参数,请改用set.seed()。
-
命令行参数
以下参数仅在控制台版本的XGBoost中使用
-
num_round-
提升轮数
-
-
data-
训练数据的路径
-
-
test:data-
测试数据进行预测的路径
-
-
save_period[默认= 0]-
保存模型的时间段。设置
save_period=10意味着XGBoost每10轮将保存一个模型。将其设置为0意味着在训练期间不保存任何模型。
-
-
task[默认=train]选项:train,pred,eval,dump-
train:使用数据进行训练 -
pred:预测测试:数据 -
eval:用于评估指定的统计信息eval[name]=filename -
dump:用于将学习到的模型转储为文本格式
-
-
model_in[默认值= NULL]-
路径输入模型,需要的
test,eval,dump任务。如果在训练中指定了XGBoost,它将从输入模型继续训练。
-
-
model_out[默认值= NULL]-
训练完成后输出模型的路径。如果未指定,则XGBoost将输出名称为
0003.modelwhere0003of boosting rounds的文件。
-
-
model_dir[默认=models/]-
训练期间保存的模型的输出目录
-
-
fmap-
特征图,用于转储模型
-
-
dump_format[default =text]选项:text,json-
模型转储文件的格式
-
-
name_dump[默认=dump.txt]-
模型转储文件的名称
-
-
name_pred[默认=pred.txt]-
预测文件的名称,在pred模式下使用
-
-
pred_margin[默认= 0]-
预测利润率而不是转换概率
-