数据集中共有12个字段,PassengerId:乘客编号,Survived:乘客是否存活,Pclass:乘客所在的船舱等级;Name:乘客姓名,Sex:乘客性别,Age:乘客年龄,SibSp:乘客的兄弟姐妹和配偶数量,Parch:乘客的父母与子女数量,Ticket:票的编号,Fare:票价,Cabin:座位号,Embarked:乘客登船码头,共有891位乘客的数据信息。其中277位乘客的年龄数据缺失,2位乘客的登船码头数据缺失,687位乘客的船舱数据缺失。
1.1 数据加载与描述性统计
加载所需数据与所需的python库。
import statsmodels.api as sm import statsmodels.formula.api as smf import statsmodels.graphics.api as smg import patsy %matplotlib inline import matplotlib.pyplot as plt import numpy as np import pandas as pd from pandas import Series,DataFrame from scipy import stats import seaborn as sns #导入CSV数据 train=pd.read_csv('F:/python/titanic_data.csv')
描述性统计
train.info()
train.describe()
描述性统计分析结果显示,共有38.3%的乘客存活,乘客船舱等级的平均值介于2和3之间,大部分乘客等级较低。乘客年龄的平均值为29.7岁,最小值为0.42岁,最大值为80岁。乘客的兄弟姐妹和配偶数目平均值为0.52,最小值为0,最大值为8个。乘客的父母和子女数目平均值为0.38,最小值为0,最大值为6个。乘客票价的平均值为32,最小值为0,最大值为512,75%分位数为31,表明大部分乘客的消费能力较低
1.2单变量探索
1.2.1 年龄与费用
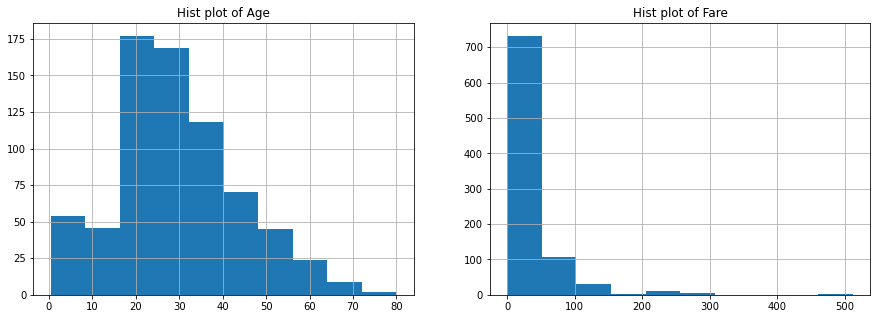
画出训练集中乘客年龄和费用的分布直方图,如下所示。可以发现,大部分乘客的年龄位于20-40岁之间,总体上呈正态分布。大部分乘客的票价很低,位于0-100之间,其他少部分乘客的票价较高
fig,ax = plt.subplots(nrows=1,ncols=2,figsize=(15,5)) train["Age"].hist(ax=ax[0]) ax[0].set_title("Hist plot of Age") train["Fare"].hist(ax=ax[1]) ax[1].set_title("Hist plot of Fare")
1.2.2 乘客是否获救
画出乘客获救与没有获救的条形图,如下所示。可以发现,大部分乘客没有获救
fig,ax = plt.subplots(figsize=(7,5)) train["Survived"].value_counts().plot(kind="bar") ax.set_xticklabels(("Not Survived","Survived"), rotation= "horizontal" ) ax.set_title("Bar plot of Survived ")
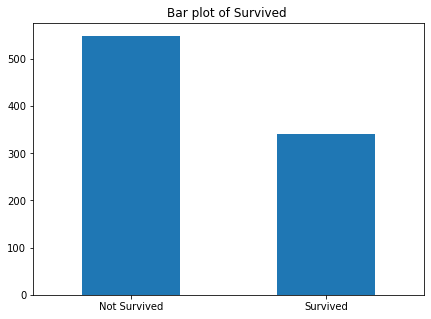
1.2.3 性别
画出乘客性别条形分布图,如下所示。可以发现,大部分乘客为男性。
fig,ax = plt.subplots(figsize=(7,5)) train["Sex"].value_counts().plot(kind="bar") ax.set_xticklabels(("male","female"),rotation= "horizontal" ) ax.set_title("Bar plot of Sex ")
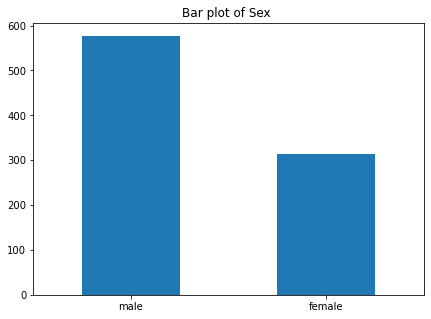
1.2.4 乘客所在的船舱等级
画出乘客的Pclass条形分布图,如下所示。可以发现,大部分乘客位于第三等级,第一等级和第二等级的乘客各有200个左右。
fig,ax = plt.subplots(figsize=(7,5)) train["Pclass"].value_counts().plot(kind="bar") ax.set_xticklabels(("Class3","Class1","Class2"),rotation= "horizontal" ) ax.set_title("Bar plot of Pclass ")

1.2.5 乘客座位号
对乘客座位号数据进行处理,将缺失值赋值为Unknown。从乘客座位号数据可以发现,第一个字母可能代表了船舱号码,将该字符提取出来,赋值给Cabin,视为船舱号。
train.Cabin.fillna("Unknown",inplace=True) for i in range(0, 891): train.Cabin[i]= train.Cabin[i][0]
画出乘客的船舱号的条形分布图,如下所示。可以发现,大部分乘客的船舱号为未知。
fig,ax = plt.subplots(figsize=(7,5)) train.Cabin.value_counts().plot(kind="bar") ax.set_title("Bar plot of Cabin ")

1.2.6 兄弟姐妹与配偶数目
画出乘客兄弟姐妹与配偶数目的条形分布图,如下所示。可以发现,大部分乘客在船上没有兄弟姐妹或配偶,大约200位乘客在船上有1个兄弟姐妹或配偶
fig,ax = plt.subplots(figsize=(7,5)) train["SibSp"].value_counts().plot(kind="bar") ax.set_title("Bar plot of SibSp ")

1.2.7 父母与子女数目
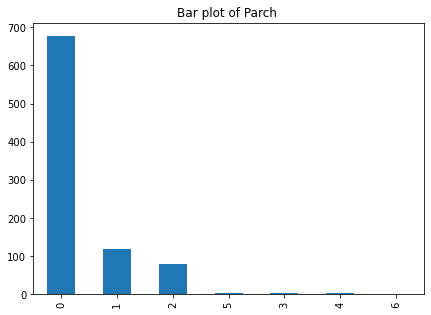
画出乘客父母与子女数目的条形分布图,如下所示。可以发现,大部分乘客在船上没有父母或子女,100多位乘客在船上有1个兄弟姐妹或配偶,大约90位乘客在船上有2个兄弟姐妹或配偶
fig,ax = plt.subplots(figsize=(7,5)) train["Parch"].value_counts().plot(kind="bar") ax.set_title("Bar plot of Parch ")
1.2.8 乘客出发港口
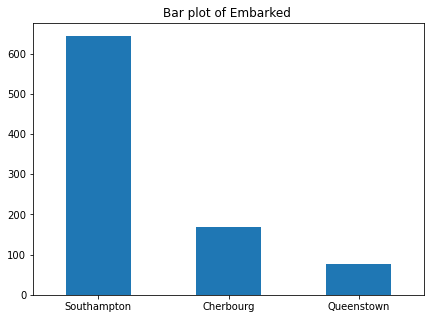
画出乘客出发港口的分布条形图,如下所示。可以发现,大部分乘客从Southampton港口出发,不到200位乘客从Cherburge出发,不到100位乘客从Queentown出发
fig,ax = plt.subplots(figsize=(7,5)) train["Embarked"].value_counts().plot(kind="bar") ax.set_xticklabels(("Southampton","Cherbourg","Queenstown"),rotation= "horizontal" ) ax.set_title("Bar plot of Embarked ")
1.3 多变量探索
1.3.1 性别与是否获救
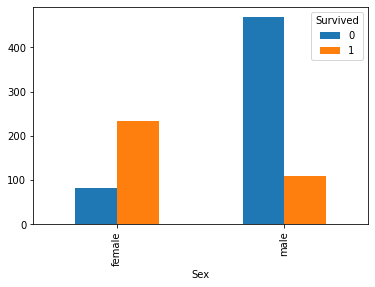
画出性别与是否获救的交叉表和条形图,如下所示。可以发现,女性获救的可能性更高,而男性获救的比例很低
pd.crosstab(train["Sex"],train["Survived"])
| Survived | 0 | 1 |
|---|---|---|
| Sex | ||
| female | 81 | 233 |
| male | 468 | 109 |
pd.crosstab(train["Sex"],train["Survived"]).plot(kind="bar")
1.3.2 船舱等级与是否获救
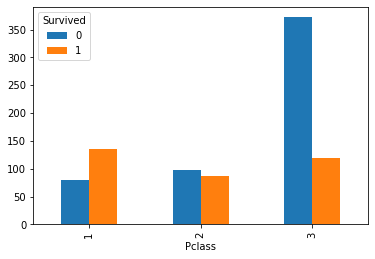
画出船舱等级与是否获救的交叉表与条形图,如下所示。可以发现,第一等级的乘客获救的可能性更高,超过50%,第二等级的乘客获救可能性在50%左右,而第三等级的乘客获救可能性很低
pd.crosstab(train["Pclass"],train["Survived"])
| Survived | 0 | 1 |
|---|---|---|
| Pclass | ||
| 1 | 80 | 136 |
| 2 | 97 | 87 |
| 3 | 372 | 119 |
pd.crosstab(train["Pclass"],train["Survived"]).plot(kind="bar")
1.3.3 兄弟姐妹或配偶数量与是否获救
画出兄弟姐妹与配偶数目与是否获救的交叉表与条形图,如下所示。可以发现,有数量为1或2的乘客获救的可能性更高
pd.crosstab(train["SibSp"],train["Survived"]).plot(kind="bar")

1.3.4 父母或子女数目和是否获救
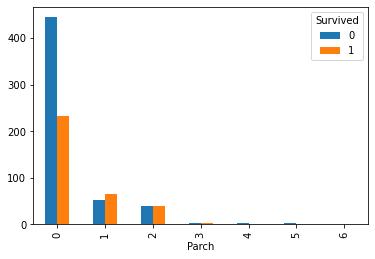
画出父母或子女数目与是否获救的交叉表与条形图,如下所示。可以发现,有数量为1或2的乘客获救的可能性更高
pd.crosstab(train["Parch"],train["Survived"]).plot(kind="bar")
1.3.5 登船港口与是否获救
画出登船港口与是否获救的交叉表与条形图,如下所示。可以发现,从Cherburge出发的乘客获救的人数比例更高
pd.crosstab(train["Embarked"],train["Survived"]).plot(kind="bar")

1.3.6 乘客船舱与是否获救
画出乘客所在船舱与是否获救的交叉表与条形图,如下所示。可以发现,船舱后没有缺失的乘客获救的人数比例更高
pd.crosstab(train["Cabin"],train["Survived"]).plot(kind="bar")

1.3.7 乘客年龄与是否获救
画出乘客是否获救与年龄的箱线图,如下所示。从箱线图上来看,两者关系并不明显
fig,ay = plt.subplots() Age1 = train.Age[train.Survived == 1].dropna() Age0 = train.Age[train.Survived == 0].dropna() plt.boxplot((Age1,Age0),labels=('Survived','Not Survived')) ay.set_ylim([-5,70]) ay.set_title("Boxplot of Age")
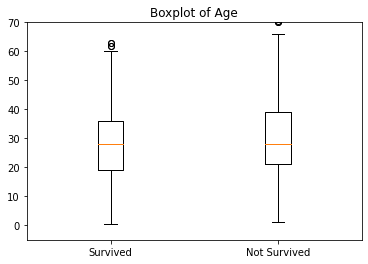
1.3.8 票价与是否获救
画出乘客是否获救与票价的箱线图,如下所示。可以发现,总体而言,获救的乘客票价更高
fig,ay = plt.subplots() Fare1 = train.Fare[train.Survived == 1] Fare0 = train.Fare[train.Survived == 0] plt.boxplot((Fare1,Fare0),labels=('Survived','Not Survived')) ay.set_ylim([-10,150]) ay.set_title("Boxplot of Fare")

1.3.9 票价与乘客舱位等级
画出乘客票价与舱位等级的箱线图,如下所示。可以明显的发现,舱位等级越高的乘客,票价越高。这两个变量之间存在非常明显的线性相关关系
fig,ay = plt.subplots() Farec1 = train.Fare[train.Pclass == 1] Farec2 = train.Fare[train.Pclass == 2] Farec3 = train.Fare[train.Pclass == 3] plt.boxplot((Farec1,Farec2,Farec3),labels=("Pclass1","Pclass2","Pclass3")) ay.set_ylim([-10,180]) ay.set_title("Boxplot of Fare and Pclass")
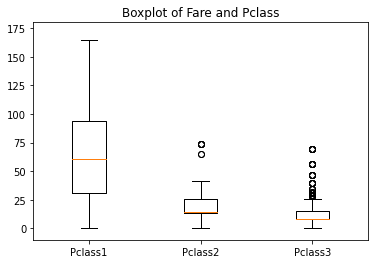
1.4 数据处理
1.4.1 缺失值处理
用年龄的均值填充年龄的缺失值,用出发港口的众数填补出发港口的缺失值
train.Age.mean() train.Age.fillna(29.7,inplace=True) train.Embarked.fillna("S",inplace=True)
1.4.2 数据分箱
根据以上分析结果和变量间的关系,将年龄数据分段为0-5岁、5-15岁、15-20岁、20-35岁、35-50岁、50-60岁、60-100岁7段。将Parch变量分成数目为0、数目为1或2、数目为大于2三段。将SibSp变量分成数目为0、数目为1或2、数目为大于2三段。将Cabin变量分为缺失和没有缺失两段
train.age=pd.cut(train.Age,[0,5,15,20,35,50,60,100]) pd.crosstab(train.age,train.Survived).plot(kind="bar")
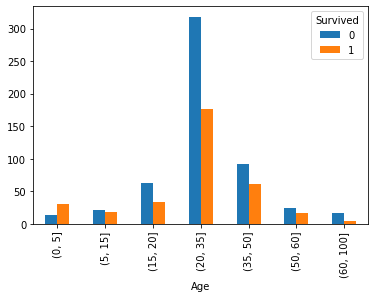
train.Parch[(train.Parch>0) & (train.Parch<=2)]=1 train.Parch[train.Parch>2]=2 train.SibSp[(train.SibSp>0) & (train.SibSp<=2)]=1 train.SibSp[train.SibSp>2]=2 train.Cabin[train.Cabin!="U"]="K"
1.4.3 创建虚拟变量
为Pclass、Sex、Embarked、Parch、SibSp、Cabin变量创建虚拟变量
dummy_Pclass = pd.get_dummies(train.Pclass, prefix='Pclass') dummy_Sex = pd.get_dummies(train.Sex, prefix='Sex') dummy_Embarked = pd.get_dummies(train.Embarked, prefix='Embarked') dummy_Parch = pd.get_dummies(train.Parch, prefix='Parch') dummy_SibSp = pd.get_dummies(train.SibSp, prefix='SibSp') dummy_Age = pd.get_dummies(train.age, prefix='Age') dummy_Cabin = pd.get_dummies(train.Cabin, prefix='Cabin')
1.5 模型建立
1.5.1 创建训练集
from sklearn.linear_model import LogisticRegression from sklearn.metrics import confusion_matrix, roc_curve,roc_auc_score,classification_report
划分训练集,将编号为0-623的乘客作为训练集。去除PassengerId和Name变量,添加常数项intercept.
因变量为乘客是否获救,自变量为乘客的票价、性别、登船码头、父母与子女数目、兄弟姐妹与配偶数目、年龄、船舱。除票价外,都为虚拟变量。考虑到Fare和Pclass之间的线性相关性,剔除Pclass变量
train_y = train[:623]["Survived"] cols_to_keep = ["Fare"] train_x = train[:623][cols_to_keep].join(dummy_Sex.loc[:, "Sex_male":]).join(dummy_Embarked.loc[:,"Embarked_Q":]).join(dummy_Parch.loc[:,"Parch_1":]).join(dummy_SibSp.loc[:,"SibSp_1":]).join(dummy_Age.loc[:,"Age_(5, 15]":]).join(dummy_Cabin.loc[:,"Cabin_U" :]) train_x['intercept'] = 1.0 train_x.tail()
1.5.2 模型构建
对训练集构建逻辑斯蒂模型。
clf = LogisticRegression()
clf.fit(train_x,train_y)
1.5.3 模型检验
划分测试集,将编号为624-890的乘客作为测试集
test_y = train[623:]["Survived"] cols_to_keep = ["Fare"] test_x = train[623:][cols_to_keep].join(dummy_Sex.loc[:, "Sex_male":]).join(dummy_Embarked.loc[:,"Embarked_Q":]).join(dummy_Parch.loc[:,"Parch_1":]).join(dummy_SibSp.loc[:,"SibSp_1":]).join(dummy_Age.loc[:,"Age_(5, 15]":]).join(dummy_Cabin.loc[:,"Cabin_U" :]) test_x['intercept'] = 1.0 test_x.head()
利用测试集对模型进行测试
clf.predict(test_x) clf.predict_proba(test_x) preds = clf.predict(test_x) #计算模型的混淆矩阵如下所示 confusion_matrix(test_y,preds)
计算模型的ROC/AUC得分,并画出ROC曲线。模型的ROC/AUC得分为0.88,表明预测准确的概率为88%左右。模型预测结果较好。
pre = clf.predict_proba(test_x) roc_auc_score(test_y,pre[:,1]) #0.88114704457364346 fpr,tpr,thresholds = roc_curve(test_y,pre[:,1]) fig,ax = plt.subplots(figsize=(8,5)) plt.plot(fpr,tpr) ax.set_title("Roc of Logistic Regression")

模型预测结果分类报告如下所示
print(classification_report(test_y,preds))
precision recall f1-score support
0 0.82 0.91 0.86 172
1 0.79 0.64 0.71 96
accuracy 0.81 268
macro avg 0.80 0.77 0.78 268
weighted avg 0.81 0.81 0.80 268
总体而言,模型的拟合结果较好