1.数据源(虚构) :手机号 ip 网址 上行流量 下行流量 状态
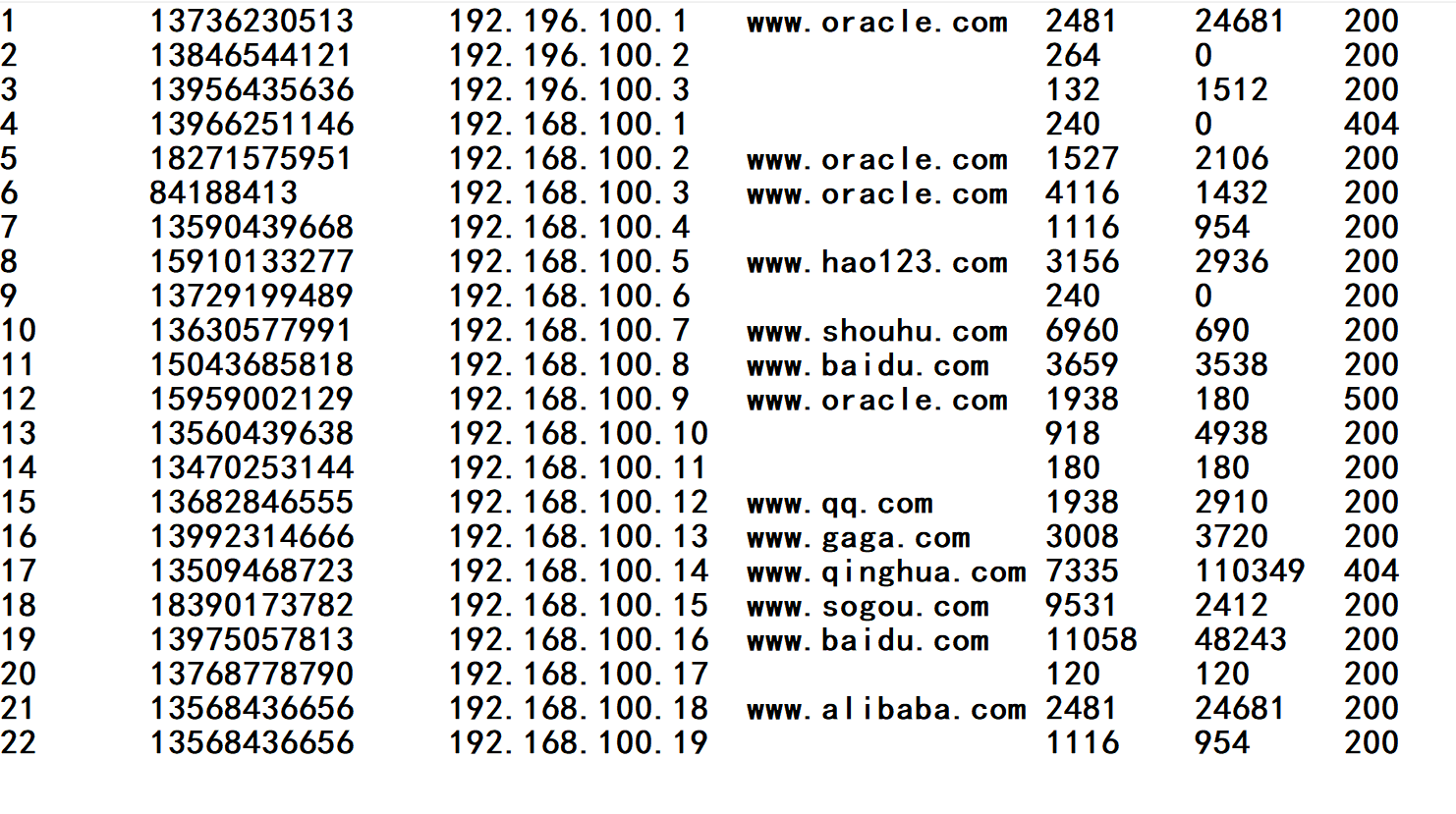
2.要求 :根据手机号分区并计算其上下行流量之和,每个区以手机号 上流量 下流量 流量之和 格式输出
3.java代码
(1)Diver
package com.oracle.flowbean;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowBeanDrivers {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//封装输出输入路径
args =new String[]{"C:/Users/input","C:/Users/output"};
System.setProperty("hadoop.home.dir","E:/hadoop-2.7.2/");
//1获取job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2设置jar加载路径
job.setJarByClass(FlowBeanDrivers.class);
//3关联mapper和reducer 及其他功能类
job.setMapperClass(FlowBeanMapper.class);
job.setReducerClass(FlowBeanReduce.class);
//3.1关联自定义分区类及分区个数
job.setPartitionerClass(FlowBeanPartitioner.class);
//job.setNumReduceTasks(5);
//4设置map输出的key和value
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
//5设置最终输出的key和value
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//6设置输入路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//7提交job
boolean result=job.waitForCompletion(true);
System.exit(result? 0 : 1);
}
}
(2)重写序列化类
package com.oracle.flowbean;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 1实现writable接口 重写序列化和反序列化方法
* 2根据业务需求,设计类中的属性
* 3生成setter和getter方法
* 4生成空参构造 ,给反序列化用
* 5生成gotring(0 自定义输出格式
* 6实现序列和反序列方法
*/
public class FlowBean implements Writable {
private long upFlow;
private long downflow;
private long sumFlow;
//空参构造
public FlowBean() {
}
@Override
public String toString() {
return upFlow +" "+downflow +
" " + sumFlow ;
}
//序列化方法
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downflow);
out.writeLong(sumFlow);
}
//反序列化方法
public void readFields(DataInput in) throws IOException {
upFlow=in.readLong();
downflow=in.readLong();
sumFlow=in.readLong();
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownflow() {
return downflow;
}
public void setDownflow(long downflow) {
this.downflow = downflow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
}
(3)mapper类
package com.oracle.flowbean;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 统计每个手机号上下行流量,及总流量
*/
public class FlowBeanMapper extends Mapper<LongWritable, Text,Text,FlowBean> {
Text k = new Text();
FlowBean flowBean = new FlowBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1获取一行数据
String line = value.toString();
//2切割一行数据
String[] fields = line.split(" ");
//3封装一个对象
//3.1封装key到数组
k.set(fields[1]);
//3.2封装value
//封装上行流量
long upFlow = Long.parseLong( fields[fields.length-3]);
//封装下行流量
long downFlow = Long.parseLong( fields[fields.length-2]);
flowBean.setUpFlow(upFlow);
flowBean.setDownflow(downFlow);
//4写出
context.write(k,flowBean);
}
}
(4)reduce类
package com.oracle.flowbean;
import com.oracle.flowbean.FlowBean;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowBeanReduce extends Reducer<Text,FlowBean,Text,FlowBean> {
FlowBean v = new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
//累加求和
//总流量累加,上下行流量累加
//上行流量求和
long sum_upFlow = 0;
//下行流量求和
long sum_downFlow = 0;
for (FlowBean flowBean : values) {
sum_upFlow+=flowBean.getUpFlow();
sum_downFlow+=flowBean.getDownflow();
}
v.setUpFlow(sum_upFlow);
v.setDownflow(sum_downFlow);
v.setSumFlow(sum_downFlow+sum_upFlow);
//输出
context.write(key,v);
}
}
(5)分区类
package com.oracle.flowbean;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class FlowBeanPartitioner extends Partitioner<Text,FlowBean> {
public int getPartition(Text key, FlowBean value, int i) {
int partition=4;
//获得手机号
String phonenumber = key.toString().substring(0, 3);
//根据phnenumber进行判断分区
if ("136".equals(phonenumber)){
partition=0;
}else if ("137".equals(phonenumber)){
partition=1;
}
else if ("138".equals(phonenumber)){
partition=2;
}else if ("139".equals(phonenumber)){
partition=3;
}
return partition;
}
}
4.小结
(1)默认情况不主动分区
//job.setNumReduceTasks(*);
找到源码可见,默认get到一个区
public int getNumReduceTasks() {
return this.getInt("mapreduce.job.reduces", 1);
}
(2)设置分区数大于分区类设置的个数
大于设置的分区数,超出的分区为空。
(3)设置分区数小于分区类设置的个数
小于设置的分区数,error。